Как извлечь страницу из PDF на iPhone или iPad
PDF-документ — лучший формат файлов для решения рабочих задач, но иногда вам нужна только часть отправленного вам документа. Извлечь страницу из PDF-документа всегда было непросто. Зачастую для этого нужно было установить дорогостоящее программное обеспечение. Кроме того, рост удаленной работы привел к необходимости быстрого решения этой задачи. Если вы находитесь вне офиса и вам необходимо поделиться одной страницей документа с вашим начальником, в прошлом вам, возможно, приходилось откладывать эту задачу до тех пор, пока вы не вернетесь в офис или не получите доступ к настольному устройству. И если запрос от начальника был срочным, вам нужно было быстро найти решение. Это всегда было непросто.
PDFelement для iOS решил эту проблему с помощью мобильного приложения для iPhone и iPad, которое содержит простые и эффективные инструменты для извлечения страниц из PDF-документов. С помощью этого приложения вы можете с легкостью извлекать страницы в документах любого размера за считанные минуты.
Как извлечь страницы из PDF-файлов на iPhone или iPad
PDFelement предлагает быстрое и простое решение для извлечения страниц из ваших PDF-файлов. Инструкция о том, как это сделать:
1. Откройте приложение PDFelement и ваш PDF-файл
Загрузите бесплатное приложение PDFelement из Apple Store на свое устройство и зарегистрируйте учетную запись.
После завершения загрузки приложение можно открыть, нажав на значок приложения на главном экране вашего устройства. Необходимый вам файл появится в приложении.
2. Доступ к функциям управления страницами
Откройте файл и нажмите на третий значок в верхней части экрана, чтобы получить доступ к функции управления страницами. С ее помощью вы сможете управлять всеми страницами вашего документа по отдельности.
3. Извлечение страницы
Нажмите «Редактировать» внизу страницы и затем выберите отдельную страницу, которую вы хотите извлечь.
4. Сохранение страницы
Выберите белую панель с исходным именем файла внутри и переименуйте его, используя клавиатуру вашего устройства. Затем нажмите «Готово».
Поставьте галочку в левом нижнем углу экрана — вы извлекли и сохранили эту страницу. Теперь все готово, чтобы поделиться станицей с другими пользователями.
Извлечение отдельных страниц из больших PDF-документов никогда больше не будет проблемой! PDFelement предоставляет простой и эффективный инструмент для извлечения одной или нескольких страниц из PDF-документов, с которыми вы работаете. Этот инструмент доступен в многофункциональном приложении вместе с другими инструментами редактирования, сохранения, управления и совместного использования, что делает PDFelement идеальным решением для работы с PDF. Все это можно выполнить на вашем iPhone или iPad с помощью популярного и бесплатного приложения.
Экспорт и импорт PDF страниц
В процессе жизненного цикла документа может понадобиться внести значительные изменения в его содержание. Он может быть собран в один документ из множества разделов. Некоторые страницы, главы и разделы могут быть изменены, переработаны, перемещены, удалены или скопированы в отдельный документ. С Master PDF Editor вы легко можете справиться с этими задачами.
Он может быть собран в один документ из множества разделов. Некоторые страницы, главы и разделы могут быть изменены, переработаны, перемещены, удалены или скопированы в отдельный документ. С Master PDF Editor вы легко можете справиться с этими задачами.
Экспорт PDF страниц
Функция позволяет разделить многостраничный файл на несколько файлов меньшего размера или сделать его постраничную разбивку.
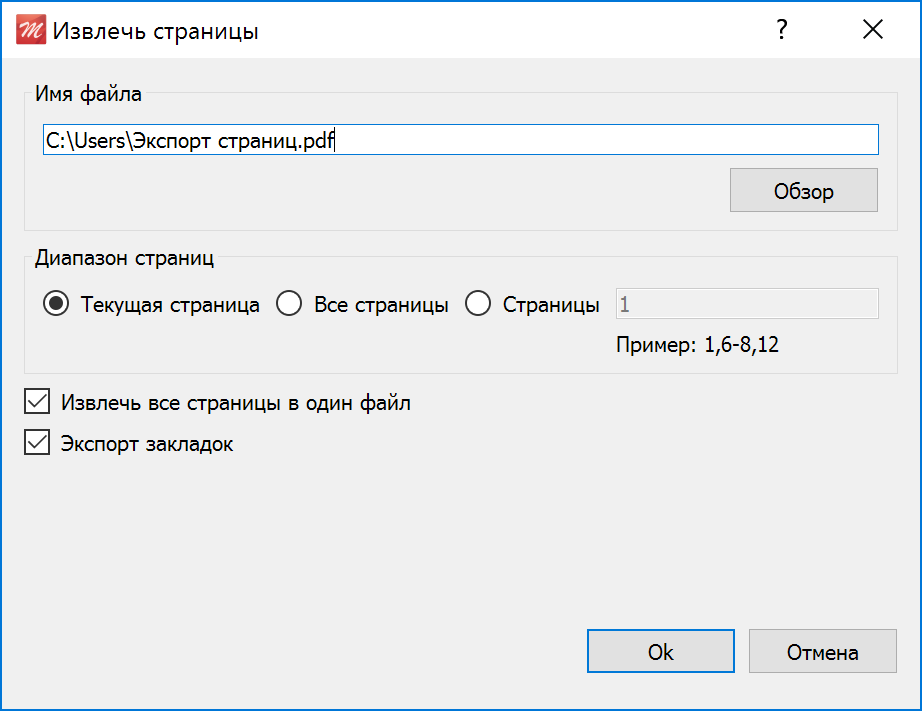
Чтобы извлечь страницы из документа выберите в главном меню Документ > Извлечь страницы… (Ctrl+Shift+E). Откроется диалоговое окно Извлечь страницы.
- Имя файла — выберите путь и указать имя файла для сохранения извлеченных страниц. Для доступа к списку файлов нажмите кнопку Обзор.
По умолчанию извлеченные страницы помещаются в новый документ с названием Экспорт страниц[имя исходного документа]_[номер страницы].
- Диапазон страниц — укажите, какие страницы требуется извлечь: текущая страница, все страницы или страницы выборочно (с указанием номеров или диапазона).

- Извлечь все страницы в один файл при установленном флажке, все страницы будут извлекаться в один файл. Чтобы создать отдельный PDF файл для каждой извлеченной страницы, снимите флажок.
- Экспорт закладок при установленном флажке будут из PDF файла будут экспортироваться закладки.
Владелец PDF документа может установить ограничение на извлечение страниц. Ограничения, установленные для данного документа можно просмотреть, выбрав в главном меню Файл > Свойства
Импорт PDF страниц
Функция дает возможность объединить и систематизировать несколько отдельных PDF файлов в одном документе.
Чтобы вставить страницы в документ выберите в главном меню Документ > Вставить страницы…(Ctrl+Shift+I). Откроется диалоговое окно Вставить страницы.
- Позиция — выберите один из вариантов вставки страниц: перед страницей (с указанием номера), после страницы (с указанием номера), перед первой страницей, после последней страницей.
- Имя файла — выберите путь и имя файла для вставки страниц. Для этого нажмите кнопку Обзор. Также укажите номера страниц, которые требуется вставить в текущий документ.
- Импорт закладок — установите флажок, чтобы импортировать закладки документа.
Как извлечь страницы из PDF ▷ ➡️ Creative Stop ▷ ➡️
Вы скачали PDF очень длинные из которых, однако, вас интересуют только некоторые главы? Что бы вы сказали об экстраполяции только тех страниц, которые вам нужны, путем удаления всего остального? Это можно сделать, и уверяю вас, это очень просто.
Прошли те времена, когда нужно было покупать дорогое профессиональное программное обеспечение. редактировать PDF файлы. Сейчас существует множество программ, даже бесплатных, которые позволяют извлекать страницы из PDF файлы просто указав числа. Все, что вам нужно сделать, это открыть документ, запись номера сохраняемых страниц (даже серийные) и нажмите кнопку. Вы удивитесь, насколько это просто!
Вы удивитесь, насколько это просто!
Как сказать Вы не хотите устанавливать новые программы на свой компьютер? Нет проблем, вы можете получить тот же результат даже с отличными онлайн-сервисами, которые позволяют вам делать все из браузера, без регистрации и без установки надоедливых плагинов. Но теперь давайте не будем теряться в разговоре, засучить рукава и попытаться выяснить
Начнем с пары применения абсолютно бесплатно для извлечения страниц из файлов PDF в Windows.
PDFtk бесплатно (бесплатно)
Если вам нужно извлечь одну или несколько страниц из PDF и использовать Windows, не стесняйтесь и попробуйте PDFtk Free. Это бесплатное программное обеспечение, которое позволяет чрезвычайно легко и быстро комбинировать и разбивать PDF-файлы: все, что вам нужно сделать, это открыть документ, указать диапазон страниц (или отдельных страниц) для экспорта и нажать кнопку. Проще чем это?
Это бесплатное программное обеспечение, которое позволяет чрезвычайно легко и быстро комбинировать и разбивать PDF-файлы: все, что вам нужно сделать, это открыть документ, указать диапазон страниц (или отдельных страниц) для экспорта и нажать кнопку. Проще чем это?
Чтобы загрузить PDFtk Free на свой компьютер, зайдите на его официальный сайт и нажмите зеленую кнопку Скачать бесплатно PDFtk найдено в середине страницы. Затем откройте файл pdftk_free-xx-Ganar-настроить.ехе вы только что скачали и нажимаете кнопки да y Siguiente, Затем установите флажок рядом с элементом Я принимаю соглашение и завершите настройку, нажав сначала Siguiente в течение четырех раз подряд, а затем до устанавливать y законченный.
Теперь запустите PDFtk, нажмите кнопку Добавить PDF и выберите PDF, из которого вы хотите извлечь страницы.
Это очень легко. Для указания диапазона страниц вы можете использовать формат хх (например, 3-5 для экстраполяции с третьей на пятую страницу документа), а для указания отдельных страниц для экстраполяции вы можете использовать формат х, х, х … (например, 5,6,9 для извлечения страниц 5, 6 и 9). Вы также можете использовать оба формата в комбинации или указать несколько диапазонов страниц (например, 3–5.8 для извлечения страниц с 3 по 5 плюс страницы с номерами 8 или 3–5.8–10 для извлечения страниц с 3 по 5 и от 8 до 10).
После выбора страниц для извлечения нажмите кнопку Создать PDF расположенную внизу слева, выберите папку, в которой вы будете сохранять полученный PDF (то есть тот, который содержит только указанные вами страницы) и все.
Бесплатные PDFill PDF инструменты (бесплатно)
Еще одно программное обеспечение, которое я предлагаю вам попробовать, — это PDFill FREE PDF Tools. Если вы никогда не слышали об этом, PDFill FREE PDF Tools — это набор бесплатных инструментов, которые позволяют редактировать PDF файлы и преобразовать их очень просто. Включает функции для объединить файлы PDF, разделить их, повернуть, зашифровать, преобразовать в изображения и многое другое. Для работы тебе нужно GhostScript y Microsoft .Net Framework — Две бесплатные программы, которые, если их еще нет на ПК, автоматически загружаются и устанавливаются во время начальной настройки.
Теперь, однако, забанить разговор и принять меры. Чтобы скачать PDFill БЕСПЛАТНЫЕ PDF Tools на свой ПК, подключитесь к сайту программы и сначала нажмите на кнопку Скачать сейчас найдено под заголовком Получить только этот инструмент (вверху справа), а затем на кнопку Скачать сейчас который находится в центре страницы, которая открывается.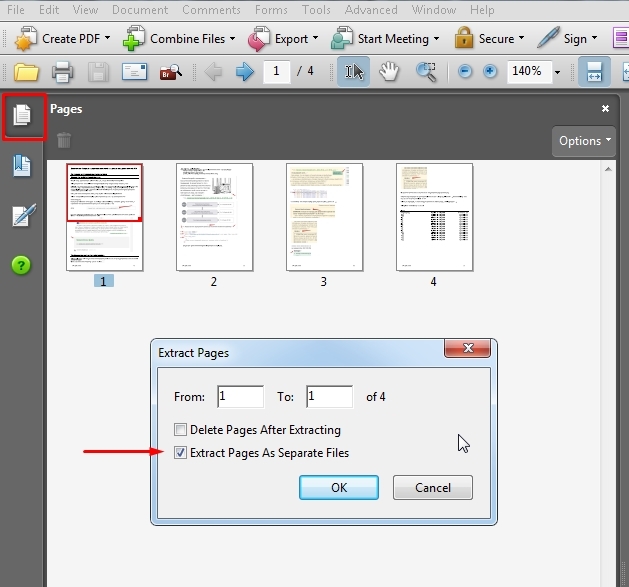
Затем откройте файл PDFill_PDF_Tools_FREE.exe (т.е. PDFill БЕСПЛАТНЫЙ установочный пакет PDF Tools) нажмите кнопку да y SiguienteПоставьте галочку рядом со статьей Я принимаю условия лицензионного соглашения и нажмите еще раз Siguiente.
На этом этапе снимите флажок с элементов, связанных с другими продуктами PDFill (которые не являются вредными, но не нуждаются в них), и завершите настройку, сначала нажав Siguiente два раза подряд, а затем вверх устанавливать y законченный.
Теперь вы действительно можете действовать! Затем запустите PDFill БЕСПЛАТНЫЕ PDF Tools, нажав на значок программы, который появился на рабочем столе Windows, и нажмите кнопку Разделить или изменить порядок страниц присутствует в главном окне программы.
Теперь убедитесь, что рядом с пунктом есть галочка Разделить страницы, Укажите в смежных текстовых полях диапазон страниц, которые вы хотите извлечь из PDF (например, 3 y 5 чтобы извлечь страницы с 3 по 5) и нажмите кнопку Привет как для Guardar выходной документ.
Вы используете Mac? Нет проблем, есть отличное программное обеспечение для извлекать страницы PDF также на macOS: это одни из лучших.
PDF Toolkit + (1.99 €)
PDF Toolkit + — это приложение для обслуживания файлов PDF, позволяющее объединять и разделять документы, извлекать из них изображения и уменьшать их вес всего несколькими щелчками мыши. Вы можете купить его в Mac App Store по цене 1,99 евро.
Как это использовать? Но конечно. Начните и выберите вкладку Разделить / извлечь страницы, затем перетащите PDF-файл, из которого вы хотите экстраполировать страницы в поле слева, и укажите список страниц для сохранения в соответствующем текстовом поле. Вы можете указать диапазоны страниц ( хх-хх ), отдельные страницы ( х, х, х … ) или оба (например, 3–5. 8 для извлечения страниц с 3 по 5 плюс страница № 8).
8 для извлечения страниц с 3 по 5 плюс страница № 8).
Операция завершена, нажмите кнопку. процессвыберите папку, в которую вы хотите сохранить документ, и все готово.
Предварительный просмотр (бесплатно)
Разве ты не хочешь тратить деньги? Нет проблем Вы можете получить отличные результаты даже с Anteprima, программным обеспечением для просмотра изображений и файлов PDF, которое входит в стандартную комплектацию macOS. Чтобы использовать его, откройте документ, из которого вы хотите извлечь страницы, и включите отображение miniaturas Меню перспектива размещен в верхней части экрана.
На этом этапе выберите миниатюры страниц, которые вы хотите извлечь из PDF, используя комбинацию Cmd + клик (o cmd + shift + click выбрать полные диапазоны страниц) и перетащите их на рабочий стол. На рабочем столе будет создан новый документ, содержащий только выбранные страницы.
На рабочем столе будет создан новый документ, содержащий только выбранные страницы.
Если вы спешите и / или не хотите устанавливать новые программы на свой компьютер, вы можете извлекать страницы из файлов PDF даже с помощью некоторых онлайн-сервисов, которые работают прямо из браузера.
iLovePDF (бесплатно)
iLovePDF — это онлайн-сервис, позволяющий редактировать и конвертировать файлы PDF различными способами. В базовой версии он бесплатный, позволяя извлекать страницы из больших документов размером до 80 МБ (максимальное количество диапазонов страниц — 10 для экстраполяции), в противном случае это стоит 3,99 евро в месяц. Сделав бесплатную регистрацию, можно немного снизить ограничения бесплатной версии сервиса, доведя порог загрузки до 100 МБ и до 12 максимальных диапазонов извлекаемых страниц.
Все понятно? Затем подключитесь к странице iLovePDF, на которую я ссылался ранее, и перетащите PDF-файл, из которого вы хотите извлечь страницы, в окно браузера. Если перетаскивание не работает, нажмите кнопку Выбирать PDF-файл и выберите «вручную» интересующий вас документ.
Если перетаскивание не работает, нажмите кнопку Выбирать PDF-файл и выберите «вручную» интересующий вас документ.
На данный момент, укажите в полях Со страницы № y до страницы № начальные и конечные номера страниц, которые нужно извлечь, нажмите кнопку Сплит PDF и дождитесь автоматической загрузки выходного документа на ваш ПК. Если вы хотите настроить более одного диапазона страниц для извлечения из PDF (например, Извлечение со страницы 3 до страницы 5, а затем со страницы 9 до страницы 11 документа), нажмите кнопку Добавить диапазон и заполните поля Со страницы № y до страницы № Похоже, ниже. Поставьте галочку рядом с элементом Объедините все интервалы в один PDF если вы хотите извлечь все выбранные диапазоны страниц в одном документе.
Что же касается intimidadТам не должно быть никаких проблем. iLovePDF автоматически удаляет все файлы, загруженные на ваши серверы, через несколько часов после загрузки. Очевидно, что если у вас есть документы, содержащие строго конфиденциальную информацию, не загружайте их онлайн (не только в iLovePDF, но и в любой службе, которая не находится под вашим непосредственным контролем).
iLovePDF автоматически удаляет все файлы, загруженные на ваши серверы, через несколько часов после загрузки. Очевидно, что если у вас есть документы, содержащие строго конфиденциальную информацию, не загружайте их онлайн (не только в iLovePDF, но и в любой службе, которая не находится под вашим непосредственным контролем).
Как извлечь страницы из PDF в Windows 10
PDF — многоплатформенный формат документа. Таким образом, нет недостатка в приложениях PDF и программном обеспечении для управления всеми вашими потребностями PDF. Одной из таких потребностей является возможность извлекать определенную страницу или набор страниц из большого PDF-документа.
Сторонние инструменты могут сделать это легко, но знаете ли вы, что в Windows 10 есть встроенный инструмент, который выполняет ту же работу? Это называется Microsoft Печать в PDF, и вот как это использовать.
Как извлечь страницы из PDF в Windows 10
Функция «Печать в PDF» встроена в Windows 10 и доступна для любого приложения, имеющего функцию печати. Вы можете найти его в диалоге печати приложений. Также обратите внимание, что «извлечение страницы из PDF» сохраняет исходный документ PDF без изменений. Извлеченные страницы «копируются» в виде отдельного PDF-файла и сохраняются в выбранном вами месте.
Вы можете найти его в диалоге печати приложений. Также обратите внимание, что «извлечение страницы из PDF» сохраняет исходный документ PDF без изменений. Извлеченные страницы «копируются» в виде отдельного PDF-файла и сохраняются в выбранном вами месте.
Процесс прост. Мы используем Google Chrome для открытия и извлечения страниц PDF:
- Откройте файл PDF, из которого вы хотите извлечь страницы, с помощью программы, поддерживающей PDF. Браузеры, такие как Chrome и Microsoft Edge, являются идеальными кандидатами. Даже Microsoft Word может сделать эту работу.
- Перейти к Распечатать диалоговое окно или нажмите универсальную комбинацию клавиш Ctrl + P. Вы также можете щелкнуть правой кнопкой мыши и выбрать Распечатать из контекстного меню.
- В диалоговом окне «Печать» установите для принтера значение Microsoft Печать в PDF.
- В разделе Страницы выберите опцию для ввода диапазона страниц и введите номер страницы, которую вы хотите извлечь. Например, если вы хотите извлечь страницу 7 из файла PDF, введите 7 в поле. Если вы хотите извлечь несколько непоследовательных страниц, таких как страницы 7 и 11, введите 7, 11 в коробке.
- Нажмите Распечатать и перейдите к месту, где вы хотите сохранить файл.
 Например, если вы хотите извлечь страницу 7 из файла PDF, введите 7 в поле. Если вы хотите извлечь несколько непоследовательных страниц, таких как страницы 7 и 11, введите 7, 11 в коробке.
Например, если вы хотите извлечь страницу 7 из файла PDF, введите 7 в поле. Если вы хотите извлечь несколько непоследовательных страниц, таких как страницы 7 и 11, введите 7, 11 в коробке.Несколько извлеченных страниц сохраняются в виде одного документа PDF. Чтобы разделить их как разные документы, вам нужно извлечь их один за другим.
Возможность извлечения страниц PDF полезна во многих повседневных ситуациях, как и эти бесплатные инструменты, которые помогут вам редактировать файлы PDF.
в любом месте.
Почему так сложно извлекать текст из PDF? / Хабр
Перевод статьи с сайта компании FilingDB, составляющей базу данных из документации европейских компанийСогласно распространённым представлениям, извлечение текста из PDF не должно быть такой уж сложной задачей. Ведь вот он, текст, прямо у нас перед глазами, и люди постоянно и с большим успехом воспринимают содержимое PDF. Откуда взяться трудностям в автоматическом извлечении текста?
Откуда взяться трудностям в автоматическом извлечении текста?
Оказывается, точно так же, как работа с именами людей сложна для алгоритмов из-за множества пограничных случаев и неправильных предположений, так и работа с PDF сложна из-за чрезвычайной гибкости PDF-формата.
Основная проблема в том, что PDF не предполагался как формат для ввода данных – его разрабатывали, как канал вывода, дающий возможность тонкой подстройки вида итогового документа.
По сути, формат PDF состоит из потока инструкций, описывающих, как создаётся изображение на странице. В частности, текстовые данные хранятся не в виде параграфов – или даже слов – а в виде символов, нарисованных на определённых местах в странице. В итоге при преобразовании текста или документа Word в PDF большая часть семантики контента теряется. Вся внутренняя структура текста превращается в аморфный суп из плавающих на странице символов.
Наполняя FilingDB, мы извлекли текстовые данные из десятков тысяч PDF-документов. В процессе мы наблюдали за тем, как оказались неверными абсолютно все наши предположения о структуре PDF-файлов. Наша миссия оказалась особенно трудной потому, что нам приходилось обрабатывать PDF-документы, приходящие от разных источников, с совершенно разными стилями, шрифтами и внешним видом.
В процессе мы наблюдали за тем, как оказались неверными абсолютно все наши предположения о структуре PDF-файлов. Наша миссия оказалась особенно трудной потому, что нам приходилось обрабатывать PDF-документы, приходящие от разных источников, с совершенно разными стилями, шрифтами и внешним видом.
Ниже описывается, какие особенности PDF-файлов делают сложной или даже невозможной задачу извлечения из них текста.
Защита от чтения PDF
Вы могли встречать PDF-файлы, запрещающие копировать из них текстовое содержимое. К примеру, вот, что выдаёт программа SumatraPDF при попытке скопировать текст из защищённого от копирования документа:
Интересно, что текст виден, но при этом программа для просмотра отказывается передавать выделенный текст в буфер обмена.
Это реализовано при помощи нескольких флагов с «разрешениями доступа», один из которых управляет разрешением на копирование. Важно понимать, что сам PDF-файл это делать не заставляет – его содержимое от этого не меняется, и задача по его реализации лежит полностью на программе для просмотра.
Естественно, это на самом деле не защищает от извлечения текста из PDF, поскольку любая достаточно продвинутая библиотека для работы с PDF позволит пользователю либо поменять эти флаги, либо проигнорировать их.
Символы за пределами страниц
Частенько в PDF можно встретить больше текстовых данных, чем те, что показаны на странице. Возьмём эту страницу из ежегодного отчёта Nestle за 2010-й.
К этой странице прикреплено больше текста, чем видно. В частности, в содержимом, связанном с нею, можно найти следующее:
KitKat отметила свой 75-й день рождения в 2010-м, но остаётся молодой и успевает за тенденциями, имея более 2,5 млн фанатов на Facebook. Её продукция продаётся в более чем 70 странах, а продажи хорошо растут в развитых странах и на развивающихся рынках, например, на Среднем Востоке, в Индии и России. Япония – второй по величине рынок компании.
Этот текст расположен вне границ страницы, поэтому большинство просмотрщиков PDF его не показывают.
 Однако данные там есть, и их можно извлечь программно.
Однако данные там есть, и их можно извлечь программно.Такое иногда бывает из-за принимаемых в последнюю минуту решений о замене или удалении текста в процессе утверждения.
Мелкие или невидимые символы
Иногда на странице PDF можно встретить очень маленькие или вообще невидимые символы. Вот, к примеру, страница из отчёта Nestle за 2012 год.
На странице имеется мелкий белый текст на белом фоне, где написано следующее:
Wyeth Nutrition logo Identity Guidance to marketsVevey Octobre 2012 RCC/CI&D
Иногда это делается для повышения доступности, с теми же целями, которым служит тег alt в HTML.
Слишком много пробелов
Иногда в PDF между буквами слов вставлены дополнительные пробелы. Это наверняка сделано в целях кернинга (изменения интервала между символами).
К примеру, в отчёте Hikma Pharma от 2013 года есть такой текст:
Если его скопировать, получим:
ch a i r m a n ' s s tat em en tВ общем случае сложно решить задачу реконструкции исходного текста.
 Наиболее успешно у нас работает подход с применением оптического распознавания символов, OCR.
Наиболее успешно у нас работает подход с применением оптического распознавания символов, OCR.Недостаточно пробелов
Иногда в PDF не хватает пробелов, или они заменены другим символом.
Пример 1: следующая выдержка сделана из ежегодного отчёта SEB за 2017.
Извлечённый текст:
TenyearsafterthefinancialcrisisstartedПример 2: отчёт Eurobank от 2013 содержит следующее:
Извлечённый текст:
On_April_7,_2013,_the_competent_authoritiesИ снова лучше всего оказалось использовать для таких страниц OCR.
Встроенные шрифты
PDF работает со шрифтами, мягко говоря, сложным образом. Чтобы понять, как хранятся в PDF текстовые данные, сначала нам нужно разобраться в глифах, названиях глифов и шрифтах.
- Глиф – это набор инструкций, описывающих, как изображать символ или букву.
- Название глифа – это название, связанное с этим глифом. К примеру, «торговая марка» для ™ или «а» для глифа «а».
- Шрифт – это список глифов и связанных с ними названий. К примеру, в большинстве шрифтов есть глиф, который большинство людей распознает, как букву «а», при этом в разных шрифтах содержатся различные способы изображения этой буквы.

В PDF символы хранятся в виде чисел, кодов символов [codepoints]. Чтобы понять, что нужно выводить на экран, рендерер должен пройти цепочку от кода символа к названию глифа, а потом к самому глифу.
К примеру, PDF может содержать код символа 116, который он сопоставляет с названием глифа «t», который, в свою очередь, сопоставлен глифу, описывающему, как выводить на экран символ «t».
Большинство PDF используют стандартную кодировку символов. Кодировка символов – это набор правил, присваивающих смысл самим кодам символов. К примеру:
- В ASCII и Unicode для обозначения буквы «t»используется код символа 116.
- Unicode сопоставляет код символа 9786 глифу «белый смайлик», который выводится, как ☺, а в ASCII такой код не определён.

Однако в PDF-документе иногда используется собственная кодировка символов и специальные шрифты. Это может показаться странным, но документ может обозначать букву «t» кодом символа 1. Он сопоставит код символа 1 названию глифа «c1», которое будет сопоставлено глифу, описывающему, как выводить букву «t».
Хотя для человека итоговый результат ничем не отличается, машина запутается из-за таких кодов символов. Если коды символов не соответствуют стандартной кодировке, программным способом почти невозможно понять, что обозначают коды 1, 2 или 3.
Зачем же в PDF нужно включать нестандартные шрифты и кодировку?
- Одна причина – усложнить извлечение текста.
- Вторая – использование субшрифтов. В большинстве шрифтов есть глифы для очень большого числа кодовых символов, при этом в PDF может использоваться небольшое их подмножество. Для экономии места создатель PDF может обрезать все ненужные глифы и создать компактный субшрифт, который скорее всего будет использовать нестандартную кодировку.
Один из способов обойти это – извлечь глифы шрифтов из документа, прогнать их через OCR, построить соответствие между шрифтом и Unicode. Это позволит вам переводить кодировку, связанную со шрифтом, в Unicode, к примеру: код символа 1 соответствует названию «c1», которое, судя по глифу, должно обозначать «t», которому соответствует код Unicode 116.
Карта кодирования, которую вы только что сделали – та, что сопоставляет цифры 1 и 116 – называется в PDF-стандарте картой ToUnicode. В PDF-документах могут содержаться собственные карты ToUnicode, однако это не обязательно.
Распознавание слов и параграфов
Воссоздание параграфов и даже слов из аморфного символьного супа PDF-файлов – задача сложная.
PDF-документ содержит список символов на странице, а распознавать слова и параграфы должен потребитель. Люди от природы эффективно справляются с этим, поскольку чтение – навык распространённый.
Чаще всего используется алгоритм группировки, сравнивающий размеры, расположение и выравнивание символов, с целью определить, что является словом или параграфом.
У простейших реализаций таких алгоритмов сложность легко может достичь O(n²), из-за чего обработка плотно забитых страниц может проходить долго.
Порядок текста и параграфов
Распознавание текста и порядка параграфов – задача сложная по двум причинам.
Во-первых, иногда правильного ответа просто нет. Если у документов с обычным типографским набором с одной колонкой последовательность чтения выходит естественной, то у документов с более смелым расположением элементов определить её сложнее. К примеру, не совсем ясно, должна ли следующая вставка идти до, после или в середине статьи, рядом с которой она расположена:
Во-вторых, даже когда человеку ответ ясен, компьютеры определить точный порядок параграфов бывает очень сложно – даже с использованием ИИ. Возможно, это утверждение покажется вам чересчур смелым, но в некоторых случаях правильную последовательность параграфов можно определить, только понимая содержимое текста.
Рассмотрим данное расположение компонентов в два столбца, где описано приготовление овощного салата.
В западном мире разумно предположить, что чтение идёт слева направо и сверху вниз. Поэтому мы, не изучая содержимого текста, можем свести все варианты к двум: A B C D и A C B D.
Изучив содержание, поняв, о чём там говорится, и зная, что овощи моют перед нарезкой, мы можем понять, что правильным порядком будет A C B D. Алгоритмически это определить крайне сложно.
При этом «в большинстве случаев» работает подход, полагающийся на порядок хранения текста внутри PDF-документа. Обычно он соответствует порядку вставки текста во время создания. Когда большие отрезки текста содержат по многу параграфов, они обычно соответствуют тому порядку, который подразумевал их автор.
Встроенные изображения
Нередко часть содержимого документа (или весь документ) оказывается отсканированным изображением. В таких случаях в нём нет текстовых данных, и приходится прибегать к OCR.
К примеру, ежегодный отчёт Yell от 2011 года доступен только в виде скана:
Почему бы просто всё не распознать?
Хотя OCR может помочь с некоторыми описанными проблемами, у него тоже есть свои недочёты.

- Длительное время обработки. Запуск OCR на скане из PDF обычно отнимает на порядок больше времени (а то и ещё дольше), чем прямое извлечение текста из PDF.
- Сложности с нестандартными символами и глифами. Алгоритмам OCR сложно работать с новыми символами – смайликами, звёздочками, кружочками, квадратиками (в списках), надстрочными индексами, сложными математическими символами, и т.п.
- Нет подсказок о последовательности текста. Упорядочивать текст, извлекаемый из PDF-документа, легче, поскольку большую часть времени этот порядок соответствует порядку вставки текста в файл. При извлечении текста с изображений таких подсказок не будет.
Тестирование
Пока что мы ещё не упоминали о том, насколько сложно подтвердить, что текст был извлечён правильно или ожидаемо. Мы обнаружили, что лучше всего проводить обширный набор тестов, изучающих как базовые метрики (длину текста, длину страницы, соотношение количества слов и пробелов), так и более сложные (процент английских слов, процент нераспознанных слов, процент чисел), а также следить за предупреждениями типа подозрительных или неожиданных символов.

Что мы можем посоветовать для извлечения текста из PDF? Прежде всего убедиться, что у текста нет более удобного источника.
Если интересующие вас данные идут только в формате PDF, тогда важно понимать, что эта проблема кажется простой лишь на первый взгляд, а решить её со 100% точностью может и не получиться.
Как извлечь таблицы с данными из PDF-файлов? — Разработка на vc.ru
Выполнить эту процедуру можно в Python с помощью библиотеки Camelot.
Camelot дает возможность настроить извлечение таблиц в том случае, если невозможно получить желаемый результат с настройками библиотеки по умолчанию. Каждая извлекаемая таблица представляет собой pandas DataFrame, который легко интегрируется в ETL и рабочие процессы анализа данных. Использование Camelot позволяет экспортировать извлекаемую таблицу в форматы csv, JSON, Excel и HTML.
Хотим поделиться, как нам удалось осуществить.
Имеется pdf-файл (Table.pdf) следующего содержания:
Таблица экономии топлива на маршруте следования спецтранспорта при различных показателях движения
Результаты подтверждены проверкой.
Извлекаем из этого файла таблицу и сохраняем ее в csv формате.
- Сначала нужно провести некоторые подготовительные действия, а именно: для работы библиотеки Camelot следует установить необходимые зависимости (tkinter и ghostscript) .
- Очень важно, друзья, проверить правильность установки этих зависимостей:

Для tkinter следует запустить Python и выполнить:
В случае некорректной установки tkinter будет выведено сообщение об ошибке.
Для ghostscript, установленной в среде Windows, выполнить действие, набрав в командной строке:
C:\> gswin64c.exe -version
C:\> gswin32c. exe -version
exe -version
для 32-битной версии ОС.
В случае правильной установки будет выведена информация о версии ghostscript и об авторских правах.
- Далее устанавливаем библиотеку с помощью командной строки ОС:
pip install camelot-py[cv]
- Теперь после установки всех требований, можно извлекать таблицы. Открываю новый файл Python и выполняю следующее:
import camelot
# PDF-файл с извлекаемой таблицей
file = ‘Table. pdf’
pdf’
Функция read_pdf () извлекает все таблицы в PDF-файле.
# извлечение всех таблиц в PDF-файле tables = camelot.read_pdf(file)
По умолчанию Camelot использует только первую страницу PDF-файла для извлечения таблиц.
Чтобы указать несколько страниц, можно использовать ключевое слово pages с аргументом:
tables = camelot.read_pdf(file, pages=’1,2,3′)
Проверяем количество извлеченных таблиц:
print(‘Количество извлеченных таблиц:’, tables. n)
n)
Вывод результата:
Количество извлеченных таблиц: 1
Для экспортирования всех возможных таблиц, которые могут быть в загруженном pdf-файле в csv-файлы необходимо выполнить:
# экспорт всех таблиц в zip-архив tables.export(‘export.csv’, f=’csv’, compress=True)
Для параметра compress задано значение True, это создаст zip-архив, содержащий все таблицы в формате csv.
Стоит уточнить, что Camelot работает именно с текстовыми PDF-файлами, а не с отсканированными документами.
Как извлечь изображения из файлов PDF в Windows 10
Что вы будете делать, если вы получите PDF-документ, который содержит кучу великолепных изображений, и вы хотите сохранить их, но не знаете, как извлечь изображения из PDF- файлов?
Как все мы знаем, формат переносимых документов (PDF) является наиболее предпочтительным форматом, и он используется во всем мире для отправки и потребления текста, изображений и другого мультимедийного контента через Интернет. Но иногда становится действительно трудно извлечь изображения из файлов PDF и сохранить их как файлы JPEG, PNG или TIFF, чтобы использовать их в других местах.
Но иногда становится действительно трудно извлечь изображения из файлов PDF и сохранить их как файлы JPEG, PNG или TIFF, чтобы использовать их в других местах.
Ну, не беспокойтесь об этом сейчас. Мы получили вашу поддержку, и в этом руководстве мы покажем вам различные простые способы извлечения изображений из PDF на компьютерах с Windows 10.
Итак, без лишних слов, давайте посмотрим, как извлечь изображения из PDF файлы и сохранить их для других целей.
Хотя существует множество способов извлечь изображения из файлов PDF и сохранить их на вашем компьютере. Но здесь мы рассмотрим только те конкретные методы, которые используются большинством народов и которым очень легко следовать.
Эти методы извлечения изображений включают использование средства снятия скриншотов Windows 10, Adobe Photoshop, Adobe Acrobat Reader, Adobe Acrobat Pro, онлайн-конвертера PDF в изображения и программного обеспечения для извлечения PDF в изображения. Вот так:
Метод 1: Извлечение изображений из PDF, сделав снимок экрана
Если вы просто хотите извлечь из PDF-документа только пару изображений и вам не очень важно разрешение, в котором они появляются, тогда это самый простой способ для вас.
Выполните следующие действия и узнайте, как извлечь изображения из PDF-файлов, сделав снимок экрана в Windows 10 с помощью инструмента для разрезания:
- Сначала откройте файл PDF, а затем перейдите к изображению, которое вы хотите захватить.
- Теперь нажмите клавиши Win + Shift + S вместе, чтобы открыть Snipping Tool.
- Затем выберите Прямоугольный нож на панели инструментов.
- Теперь нажмите и перетащите мышью, чтобы сделать снимок экрана под PDF-файлом.
- Как только снимок экрана будет сделан, нажмите одновременно клавиши Ctrl + S, чтобы сохранить его на своем компьютере.
Таким образом, вы можете легко извлечь все изображения из файлов PDF по одному. Это самый простой способ извлечь изображения из PDF в системе Windows 10, если у вас есть только несколько изображений для извлечения.
Способ 2. Извлечение изображений из PDF с помощью Adobe Acrobat Reader
Если у вас есть Adobe Acrobat Reader на ноутбуке или настольном компьютере с Windows 10 (что, скорее всего, у вас есть), вы можете легко использовать встроенные в него инструменты для извлечения изображений из файлов PDF.
Выполните следующие действия и узнайте, как извлечь изображения из файлов PDF в Windows 10 с помощью Adobe Acrobat Reader:
- Сначала откройте файл PDF, а затем перейдите к изображению, которое вы хотите извлечь.
- Затем нажмите в меню «Правка» и выберите «Сделать снимок».
- Теперь просто нажмите и перетащите курсор мыши на область изображения, чтобы сделать снимок экрана.
- Как только снимок экрана будет сделан, на нем будет написано «Выбранная область скопирована».
- Теперь вы можете вставить скопированное изображение в Microsoft Paint или любое другое программное обеспечение для редактирования фотографий, доступное на вашем ПК, и сохранить его в любом формате.
Этот процесс извлечения PDF в изображения стоит попробовать, когда вам нужно извлечь изображения по отдельности. Если вы хотите извлечь все изображения из PDF сразу, следуйте нижеописанным методам.
Способ 3. Извлечение изображений из PDF с помощью Adobe Photoshop
Adobe Photoshop — еще один лучший способ извлечения изображений из PDF на ПК с Windows 10. Если вы используете Photoshop в своей системе, вы можете выполнить следующие шаги, чтобы легко извлечь все изображения из файлов PDF:
Если вы используете Photoshop в своей системе, вы можете выполнить следующие шаги, чтобы легко извлечь все изображения из файлов PDF:
- Прежде всего, откройте Adobe Photoshop на своем ПК, а затем откройте файл PDF, как обычно, открыв любой файл изображения.
- Теперь диалоговое окно «Импорт PDF» появится автоматически, здесь вы должны выбрать опцию «Изображения».
- Затем, удерживая клавишу Shift, выберите изображения, которые вы хотите открыть в Photoshop, а затем нажмите кнопку ОК.
- Теперь все выбранные изображения будут открываться отдельно в фотошопе, нажмите сочетание клавиш Ctrl + S, чтобы сохранить их на своем компьютере.
Таким образом, вы можете легко извлекать изображения из файлов PDF с помощью Adobe Photoshop и сохранять их в нужном формате.
Как извлечь данные из PDF
В этой статье описываются три инструмента для извлечения таблиц данных из PDF-файлов: инструмент с открытым исходным кодом Tabula и коммерческие инструменты smallpdf и cometdocs .
Проблема
Часто наши данные не поступают в аккуратный лист Excel или CSV, а скрываются в виде таблицы в PDF-файле, как в этом отчете Организации Объединенных Наций:
Если затем мы попытаемся скопировать и вставить числа оттуда в электронную таблицу, столбцы и / или строки не будут переведены:
Есть много инструментов, которые пытаются решить эту проблему.Каждая таблица PDF немного отличается (некоторые из них чрезмерно спроектированы, некоторые используют странные текстовые формы), поэтому, если одно решение не работает для вашего конкретного PDF-файла, вы можете попробовать другое. Первый инструмент, который мы покажем вам, который позволяет извлекать таблицы данных из PDF-файлов, — это Tabula:
.Решение 1: Tabula
Tabula — это небольшое программное обеспечение с открытым исходным кодом, которое вы можете загрузить на свой Windows или Mac. После того, как вы установили его и нажали на значок инструмента, он откроется в вашем браузере, например Firefox или Chrome.Но не волнуйтесь: все ваши данные будут обрабатываться на вашем компьютере. Таким образом, Tabula отлично подходит для конфиденциальных данных.
Вот что вы увидите, когда откроете Tabula:
Нажмите «Обзор», а затем «Импорт», чтобы открыть PDF-файл с таблицей данных, которую вы хотите извлечь.
Не загружайте полный PDF-файл, а только страницы, содержащие ваши таблицы данных.
Если ваш PDF-файл полон тяжелых изображений или состоит из сотен страниц, любому инструменту будет сложно с ним справиться. Многие программы чтения PDF, такие как Preview на Mac или Adobe Acrobat, позволяют сохранять одну или несколько страниц PDF по отдельности. Воспользуйтесь этим, если выбранный вами инструмент для извлечения PDF-файлов работает медленно.
После импорта PDF-файла теперь вы можете указать Tabula, где находятся таблицы на вашей странице (ах). Для этого вы можете щелкнуть и перетащить выделенный фрагмент. Если вы затем щелкните «Предварительный просмотр и экспорт извлеченных данных» , вы увидите, как Tabula интерпретирует ваш выбор:
Для этого вы можете щелкнуть и перетащить выделенный фрагмент. Если вы затем щелкните «Предварительный просмотр и экспорт извлеченных данных» , вы увидите, как Tabula интерпретирует ваш выбор:
Внимательно посмотрите на предварительный просмотр ваших данных.Иногда некоторые символы текста отсутствуют, и только половина ваших чисел верна. Если ваши данные выглядят не так, как задумано, у вас есть два варианта:
1. На боковой панели переключайтесь между «Поток» и «Решетка». Stream ищет пробелы между столбцами, а Lattice ищет граничные линии между столбцами. Выбор Lattice вместо Stream или наоборот может иметь огромное значение.
2. Проверьте свой выбор и поэкспериментируйте. Часто бывает хорошо нарисовать рамку выбора очень близко к данным; даже в пределах таблицы.Хуже работает выделение стола и некоторого белого пространства вокруг него. Если предварительный просмотр не улучшился, попробуйте выбрать подмножество таблицы данных.
Если предварительный просмотр не улучшился, попробуйте выбрать подмножество таблицы данных.
Как только ваши данные будут выглядеть хорошо, вы можете экспортировать их как csv, tsv или JSON или просто скопировать и вставить таблицу в свою электронную таблицу. Очень вероятно, что вам все же нужно немного очистить данные. Здесь мы убираем пробелы в числах. После этого мы можем скопировать и вставить результат в Datawrapper.
Решение 2: smallpdf
Если вы не можете или не хотите устанавливать программное обеспечение на свой компьютер и ваши документы не конфиденциальны, Smallpdf может быть хорошим решением.Это программа для преобразования PDF-файлов, которую вы можете бесплатно использовать онлайн (два раза в час). Вы также можете скачать его как бесплатную пробную версию.
Чтобы использовать онлайн-версию, перейдите по адресу https://smallpdf. com/pdf-to-excel и перетащите файл PDF в большое зеленое поле:
com/pdf-to-excel и перетащите файл PDF в большое зеленое поле:
Подождите секунду, и ваш файл будет готов к загрузке. Поскольку smallpdf не просил нас делать выбор, как это сделала Tabula, загруженные нами полные страницы () будут преобразованы.
Мы получаем файл Excel с двумя вкладками: в первой мы находим текст, который был помещен рядом с таблицей в нашем исходном PDF-файле; во второй вкладке находим таблицу; даже в оригинальном дизайне. Smallpdf преобразует числа лучше, чем Tabula. Однако мы видим, что он немного испортил многострочные заголовки:
Решение 3: cometdocs
Если вы хотите конвертировать более двух PDF-файлов одновременно и у вас нет проблем с подпиской на сервис, cometdocs может быть хорошей альтернативой. Он позволяет конвертировать пять PDF-файлов в неделю. Когда вы зайдете на их веб-сайт (cometdocs.com), вы увидите кнопку «Загрузить». Щелкните по нему, чтобы выбрать свой PDF:
После загрузки PDF-файла он появится в белом поле. Под ним вы увидите четыре вкладки. Нажмите «конвертировать» и перетащите туда ваш PDF-файл. Затем щелкните по желаемому формату вывода (в нашем случае — Excel). Чтобы начать преобразование вашего PDF-файла, вам необходимо зарегистрироваться:
Через минуту или две вы получите электронное письмо со ссылкой на преобразованный файл. В нашем файле Excel вся информация будет на одном листе:
Как и smallpdf, cometdocs конвертирует целые страницы в файл Excel. Нам нужно будет немного очистить здесь и удалить некоторые строки и столбцы.
Прочие инструменты
Существует так много других инструментов для извлечения данных из PDF-файлов. Так что, если ни один из этих вариантов вам не подходит, стоит немного присмотреться. : Если вы поклонник командной строки, вам могут быть интересны такие инструменты, как pdftk. Если вы найдете инструмент лучше (бесплатный и / или с открытым исходным кодом), чем те, которые мы объяснили здесь, дайте нам знать!
Извлечь страницы из PDF в Интернете & vert; Таблицы PDF
Обновлено в феврале 2019 г.
Вы можете извлекать страницы из PDF с помощью Google Chrome, сохраняя страницы как отдельный файл PDF.Мы покажем вам, как это сделать.
Это особенно полезно, когда вам нужно преобразовать всего несколько страниц очень большого документа с помощью нашего Конвертер PDF в Excel, или если вы хотите уменьшить размер PDF-файла для других целей.
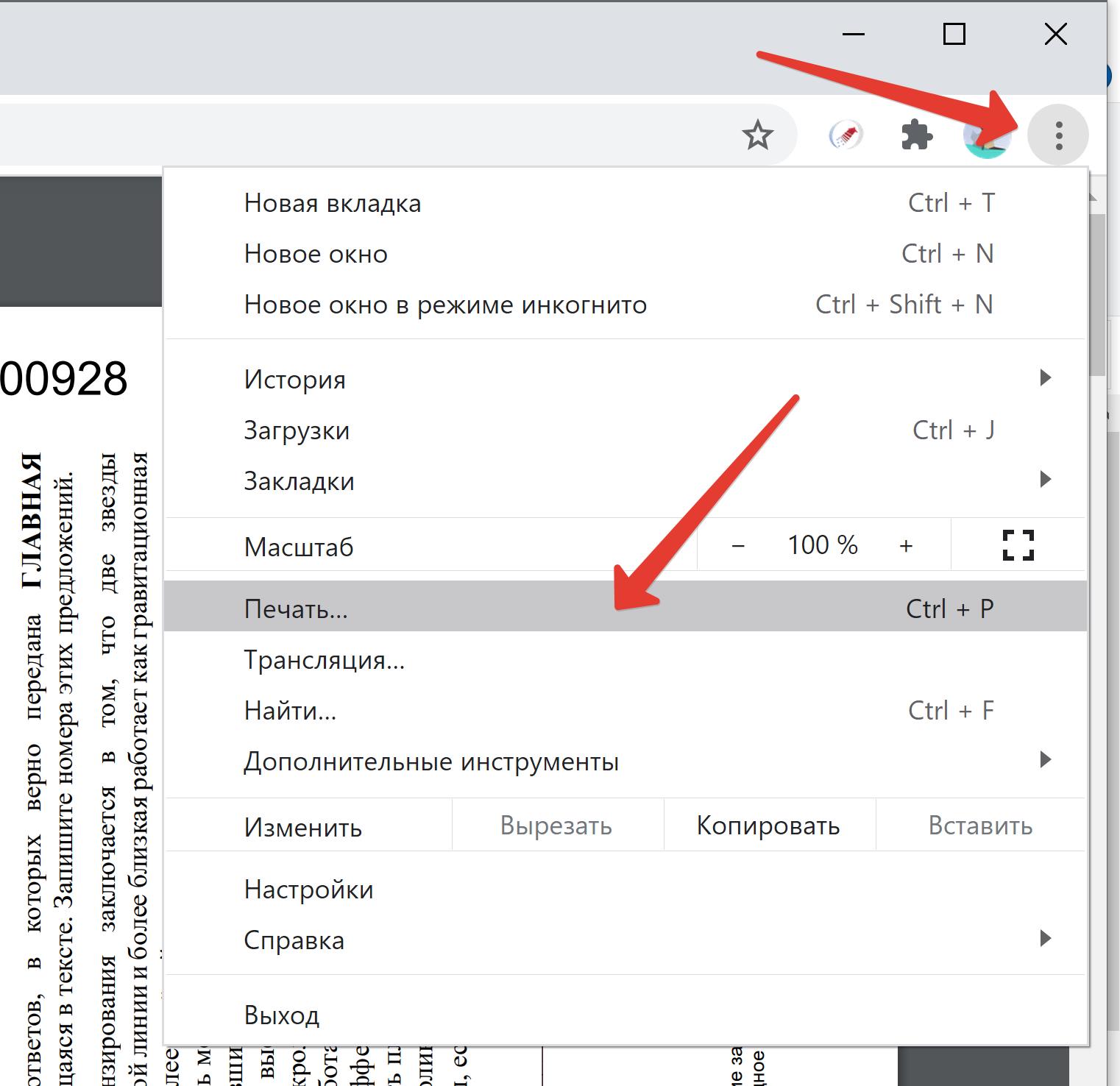
В этом примере я извлечу страницы из PDF-версии Консолидированная финансовая отчетность Группы Нестле за 2016 год.
Процесс, который я буду проиллюстрировать, идентичен в Opera и очень похож в Firefox, Safari и Internet Explorer.
Шаг 1
Найдите PDF-документ в проводнике Windows, щелкните его правой кнопкой мыши и
выберите Открыть с помощью -> Google Chrome .
Шаг 2
Когда PDF-файл откроется в Chrome, щелкните значок «Печать» в правом верхнем углу. сторона окна.
Шаг 3
Когда появится диалоговое окно «Печать», нажмите Изменить в разделе Назначение .
Шаг 4
На следующем экране выберите Сохранить как PDF .
NB: не используйте Microsoft Print to PDF , так как ваш PDF-файл будет сохранен как изображение, а не как PDF-файл с возможностью поиска.
Шаг 5
Введите номера страниц, которые нужно извлечь, в выделенное текстовое поле.
Например, если вам нужны страницы с 8 по 10, введите 8-10 .
Или, если вам нужны страницы 12 и 14, введите 12, 14 .
Теперь, если вы хотите быть абсолютным индивидуалистом, вы можете объединить
два с 8-10, 12, 14 .Это даст вам страницы 8, 9, 10, 12 и 14 в одном документе PDF.
Шаг 6
Нажмите Сохранить , после чего вам будет предложено дать новому PDF-файлу имя и папку для его сохранения.
Поздравляем, все готово! Теперь вы можете конвертировать PDF-файлы в Excel, CSV, XML или HTML.
У вас есть еще вопросы?
Ознакомьтесь с другими сообщениями в нашем блоге здесь или нашу страницу часто задаваемых вопросов. Также обращайтесь к нам.
5 методов извлечения данных PDF
Если ваши PDF-файлы связаны со счетами, квитанциями, паспортами или водительскими правами, воспользуйтесь Nanonets PDF scraper или PDF data extractor для бесплатного извлечения данных из PDF-документов.Нажмите ниже, чтобы узнать больше о Nanonets PDF scraper .
Portable Document Format (PDF) — это формат файлов для обмена данными между организациями, предприятиями и учреждениями. Хотя вы можете с легкостью просматривать, сохранять и распечатывать PDF-файлы, редактирование или попытки очистить, проанализировать или извлечь данные из PDF-файлов могут быть проблемой; например, пробовали ли вы когда-нибудь извлекать таблицы из документов PDF?
Получение и извлечение данных из PDF имеет решающее значение для реорганизации и представления данных в соответствии с вашими требованиями.В большинстве других форматов документов, таких как DOC, XLS или CSV, извлечение части информации выполняется просто; просто отредактируйте данные или скопируйте и вставьте.
Но это довольно сложно сделать для PDF-файлов; редактирование невозможно, а копирование и вставка просто не поддерживает исходное форматирование и порядок представления данных; попробуйте извлечь таблицы из PDF!
При обработке массового извлечения данных PDF эти проблемы могут вызвать ошибки, задержки и перерасход средств, которые могут серьезно повлиять на цели вашей организации.Компании сталкиваются с аналогичными проблемами при извлечении текста из PDF-файлов или преобразовании PDF-файлов в XML!
Хотите очистить данные из документов PDF или преобразовать таблицу PDF в Excel? Воспользуйтесь парсером Nanonets PDF или парсером PDF, чтобы очищать данные PDF или анализировать файлы PDF в любом масштабе!
Итак, как можно эффективно извлекать данные из файла PDF? Вот 5 различных способов извлечения данных из PDF в порядке возрастания эффективности и точности:
Копирование и вставка
Подход «копирование и вставка» является наиболее практичным вариантом при работе с управляемым количеством PDF-документов.
- Открыть каждый файл PDF
- Выбор части данных или текста на определенной странице или наборе страниц
- Копировать выбранную информацию
- Вставить скопированную информацию в файл DOC, XLS или CSV
Как упоминалось ранее , этот простой подход чаще всего приводит к ошибочному и подверженному ошибкам извлечению данных. Вам придется потратить значительное количество времени и усилий, чтобы реорганизовать и представить извлеченную информацию последовательным и значимым образом.
Аутсорсинг ручного ввода данных
Обработка ручного извлечения данных из PDF-файлов внутри компании для большого количества документов может стать непосильной и чрезмерно дорогой в долгосрочной перспективе.
Аутсорсинг ручного ввода данных — очевидная альтернатива, которая является дешевой и быстрой. Онлайн-сервисы, такие как Upwork, Freelancer, Hubstaff Talent & Fiverr и другие подобные компании, имеют армию профессионалов по вводу данных из стран со средним уровнем дохода в Южной Азии, Юго-Восточной Азии и Африке.
Эти профессионалы по вводу данных по сути выполнят шаги, описанные в предыдущем методе, но в большом масштабе. Хотя такой подход может снизить затраты и задержки на извлечение данных, контроль качества и безопасность данных вызывают серьезную озабоченность!
Требуется бесплатное онлайн-распознавание текста для изображения в текст, PDF в таблицу, PDF в текст или извлечения данных PDF? Ознакомьтесь с онлайн-API OCR Nanonets в действии и начните создавать собственные модели OCR бесплатно!
PDF-конвертеры
PDF-конвертеры — очевидный выбор для тех, кто озабочен качеством и безопасностью данных.Конвертеры PDF позволяют управлять извлечением данных внутри компании, будучи быстрым и эффективным. Такие конвертеры PDF доступны в виде программного обеспечения, веб-решений и даже мобильных приложений.
PDF-файлы чаще всего конвертируются в форматы Excel (XLS или XLSX) или CSV, поскольку они представляют таблицы в аккуратном виде; Также широко используются конвертеры PDF в XML. Просто откройте или загрузите PDF-документ и преобразуйте его в удобный формат.
Однако конвертеры PDF просто не приспособлены для обработки документов в большом масштабе.Массовое извлечение данных просто невозможно, и нужно повторять процесс извлечения данных для каждого документа, по одному!
Вот некоторые лучшие инструменты / программное обеспечение для конвертации PDF:
- Adobe
- Просто PDF
- SmallPDF
- PDF2Go
- PDFtoExcel
- PDFelement
- Nitro Pro
- Cometdoc22 902 902 Pro
- Veryysk 902 , PDF-документы содержат таблицы, а также текст, изображения и рисунки.Во многих случаях интересующие данные обычно находятся в таблицах. Конвертеры PDF обрабатывают весь документ PDF, не предоставляя возможности ограничить извлечение данных определенным разделом в PDF.
Инструменты извлечения из PDF в таблицы делают именно это. Инструменты / технологии извлечения таблиц PDF, такие как Tabula и Excalibur, позволяют выбирать разделы в PDF-файле, вычерчивая рамку вокруг таблицы, а затем извлекая данные в файл Excel (XLS или XLSX) или CSV.
Хотя инструменты PDF в таблицы дают достаточно эффективные результаты, вам могут потребоваться усилия разработчиков или штатные специалисты, чтобы использовать базовые технологии, обеспечивающие эти инструменты, в соответствии с вашими собственными требованиями.
Кроме того, такие инструменты извлечения данных PDF работают только с собственными файлами PDF, а не с отсканированными документами (которые чаще всего используются в организационной коммуникации и обмене информацией).
У онлайн-API OCR и OCR наносетей есть много интересных вариантов использования.
Запланировать звонок
Программное обеспечение для автоматического извлечения данных PDF или программное обеспечение OCR, такое как Nanonets, обеспечивает наиболее целостное решение проблемы извлечения данных из PDF-файлов или извлечения текста из изображений. (Что такое OCR или OCR PDF? — вот подробное объяснение того, что такое программное обеспечение OCR)
Они надежны, эффективны, чрезвычайно быстры, по конкурентоспособной цене, безопасны, масштабируемы и могут обрабатывать отсканированные документы, а также файлы PDF в исходном формате.
Такие автоматизированные парсеры PDF или парсеры PDF используют комбинацию оптического распознавания символов (OCR), роботизированной автоматизации процессов (RPA), распознавания образов, распознавания текста и других методов, которые идеально подходят для работы в большом масштабе и обработки массового извлечения данных.
Рабочий процесс в целом включает следующие шаги:
- Соберите пакет образцов документов для использования в качестве обучающего набора
- Обучите автоматизированное программное обеспечение извлекать данные в соответствии с вашими потребностями
- Протестируйте и проверьте
- Запустите обученный программное обеспечение для реальных документов
- Обработка извлеченных данных
Преимущества использования Nanonets по сравнению с другими программами для извлечения данных PDF выходят далеко за рамки просто повышения точности.Вот 7 причин, по которым вам следует подумать об использовании Nanonets для извлечения данных из документов PDF вместо других инструментов и автоматизированного программного обеспечения.
Обновление май 2021: этот пост был первоначально опубликован в окт. 2020 и с тех пор обновлялся.
Вот слайд, на котором резюмируются выводы, сделанные в этой статье. Вот альтернативная версия этого поста.
Преобразование файлов PDF в структурированные данные.
PDF здесь, чтобы остаться.В сегодняшней рабочей среде PDF стал повсеместным в качестве цифровой замены бумаги и содержит все виды важных бизнес-данных. Но какие есть варианты, если вы хотите извлекать данные из документов PDF ? Переназначение данных PDF вручную часто является первым рефлексом, но в большинстве случаев не удается по разным причинам. В этой статье мы поговорим о решениях для извлечения данных PDF (PDF Parser) и о том, как исключить ручной ввод данных из рабочего процесса.
Кейс для извлечения данных из документов PDF
С тех пор, как PDF был впервые представлен в начале 90-х годов, формат Portable Document Format (PDF) получил огромное распространение и стал повсеместным в современной рабочей среде.Файлы PDF — это идеальное решение для обмена бизнес-данными как внутри компании, так и с торговыми партнерами. Вот некоторые популярные варианты использования PDF-документов в таких областях, как цепочка поставок, закупки и бизнес-администрирование:
- Счета-фактуры
- Заказы на закупку
- Транспортные накладные
- Отчеты
- Презентации
- Прайс и Списки продуктов
- HR Формы
- …
Все типы документов, упомянутые выше, имеют одну общую черту: все они используются для передачи важных бизнес-данных из точки A в точку B.
Пока все хорошо. Однако есть одна загвоздка … PDF — это просто замена бумаги.
Другими словами, данные, хранящиеся в PDF-документах, в основном так же доступны, как и данные, записанные на листе бумаги. Это становится проблемой всякий раз, когда вам нужно получить доступ к данным, хранящимся в ваших документах, удобным способом. Возникает, например, вопрос, как извлечь данные из файлов PDF в файлы Excel?
Рефлекс по умолчанию — вручную переназначить данные из файлов PDF или выполнить копирование и вставку.Очевидно, что ручной ввод данных является утомительным, подверженным ошибкам и дорогостоящим методом, и его следует всеми средствами избегать. Ниже мы представляем вам различные подходы к извлечению данных из файла PDF. Но сначала давайте разберемся, почему извлечение данных PDF может быть сложной задачей.
Почему сложно извлекать данные из файлов PDF?
Есть несколько причин, по которым извлечение данных из PDF может быть сложной задачей, от технических проблем до практических препятствий в рабочем процессе.
Во-первых, многие файлы PDF представляют собой отсканированные изображения.Хотя эти документы легко читаются людьми, компьютеры не могут понять текст отсканированного изображения без предварительного применения метода, называемого оптическим распознаванием символов (OCR).
После того, как ваши документы прошли через сканер PDF с оптическим распознаванием текста и действительно содержат текстовые данные (а не только изображения), можно вручную скопировать и вставить части текста. Очевидно, что этот метод утомителен, подвержен ошибкам и не масштабируется. Открытие каждого PDF-документа по отдельности, поиск нужного текста, затем выбор текста и копирование в другое программное обеспечение занимает слишком много времени.
Как извлечь данные из PDF?
Ручное изменение ключей данных из нескольких документов PDF
Давайте будем честными. Если у вас есть всего несколько PDF-документов, самым быстрым путем к успеху может быть ручное копирование и вставка. Процесс прост: откройте каждый документ, выберите текст, который вы хотите извлечь, скопируйте и вставьте туда, где вам нужны данные.
Даже если вы хотите извлечь данные таблицы, выделение таблицы указателем мыши и вставка данных в Excel во многих случаях даст вам достойные результаты.Вы также можете использовать бесплатный инструмент под названием Tabula для извлечения табличных данных из файлов PDF. Tabula вернет файл электронной таблицы, который вам, вероятно, потребуется обработать вручную. Tabula не включает механизмы распознавания текста, но это определенно хорошая отправная точка, если вы имеете дело с собственными файлами PDF (а не со сканированными изображениями).
Аутсорсинг ручной ввод данных
Аутсорсинг ввода данных — это огромный бизнес. Есть буквально тысячи провайдеров ввода данных, которых вы можете нанять. Чтобы предлагать быстрые и дешевые услуги, эти компании нанимают армии клерков по вводу данных в странах с низким уровнем дохода, которые затем берут на себя всю тяжелую работу.Очевидно, что провайдеры ввода данных также используют передовые технологии для ускорения процесса, однако общий рабочий процесс в основном такой же, как и описанный выше: открытие каждого отдельного документа, выбор правильной текстовой области и размещение данных в базе данных или электронной таблице. .
Аутсорсинг ручной ввод данных связан с большими накладными расходами. Поиск подходящего поставщика, согласование условий и объяснение вашего конкретного варианта использования с экономической точки зрения имеет смысл только в том случае, если вам нужно обрабатывать большие объемы документов.И все же, вероятно, гораздо эффективнее позволить нашему программному обеспечению автоматического сканирования в базу данных выполнять ту работу, которую мы выполняем с помощью нашего анализатора электронной почты или PDF Docparser.
Как автоматизировать извлечение данных PDF?
Решения для автоматического извлечения данных PDF бывают разных видов, от простых инструментов оптического распознавания текста до корпоративных платформ для обработки документов и автоматизации рабочих процессов. Однако большинство систем используют схожий рабочий процесс:
- Сборка пакетов образцов документов, которые действуют как обучающие данные
- Обучите систему каждому типу документов, которые вы хотите обработать
- Настройте процесс для автоматического получения документов, их обработки и отправки данных
В большинстве передовых решений используется комбинация различных методов для обучения системы извлечения данных.Простым методом является, например, зональное распознавание текста, при котором пользователь просто определяет определенные места внутри документа с помощью системы «укажи и щелкни». Более продвинутые методы основаны на регулярных выражениях и распознавании образов.
После начального периода обучения системы извлечения данных из документов предлагают быстрое, надежное и безопасное решение для автоматического преобразования документов PDF в структурированные данные. Использование PDF Parser является жизнеспособным решением, особенно при работе со многими документами одного типа (счета-фактуры, заказы на поставку, отгрузочные накладные и т. Д.).
В Docparser мы предлагаем мощный, но простой в использовании набор инструментов для извлечения данных из файлов PDF. Наше решение было разработано для современного облачного стека, и вы можете автоматически извлекать документы из различных источников, извлекать определенные поля данных и отправлять проанализированные данные в режиме реального времени. Посмотрите наш скринкаст ниже, который дает вам хорошее представление о том, как работает Docparser.
Мы надеемся, что вы получили лучшее представление о различных вариантах извлечения данных из документов PDF.Не стесняйтесь оставлять комментарии или обращаться к нам по электронной почте.
Как извлечь страницы из PDF
Загрузка ….
Размер загруженного файла (ов) превышает 2 МБ, загрузка может занять больше времени.
Пожалуйста, проявите терпение.ОТМЕНА
Ваши файлы останутся конфиденциальными. Безопасная загрузка файлов по HTTPS.
Узнайте, как извлекать страницы из PDF за 3 простых шага
1
Загрузить файл
Перетащите свой PDF-файл в зону размещения выше или нажмите «Загрузить», чтобы выбрать файл на своем компьютере.
2
Извлечь страницы из PDF
Сначала установите (или отметьте) поле слева от имени файла.
Затем выберите вкладку «Правка» в верхнем левом углу экрана.
Затем нажмите «Удалить страницы», а затем «Извлечь страницы» в раскрывающемся списке. Это запустит мастер извлечения страниц. Вы можете выбрать, какой диапазон страниц вы хотите извлечь из файла PDF.3
Загрузите ваш файл
Получите 3 бесплатных загрузки вашего файла PDF.Подпишитесь на ежемесячную или годовую подписку на неограниченное количество скачиваний.
Если вы часто редактируете PDF-файлы, вам понадобится возможность извлекать страницы из PDF-файла. Например, вы можете иметь дело с большим документом, но хотите отправить другому человеку только определенные страницы. Вместо того, чтобы отправлять весь файл, вы можете удалить выбранные страницы и создать новый файл. К счастью, для извлечения страниц из PDF требуется всего несколько шагов. Ниже мы расскажем, как извлекать страницы из PDF-файлов в Интернете с помощью DocFly.
Самый простой способ извлекать страницы из PDF онлайн
Быстрое извлечение страниц из PDF
Ищете способ быстро удалить страницы из PDF? Не смотрите дальше, чем DocFly! С помощью нашего бесплатного онлайн-инструмента вы сможете удалять страницы менее чем за минуту.
Когда извлекать страницы PDF
С DocFly просто удалить страницу из PDF. Зачем отправлять весь файл, если вы хотите поделиться только одной страницей? Теперь это быстро и просто сделать с помощью нашего инструмента для извлечения PDF-файлов.
Все необходимые инструменты для работы с PDF
DocFly предлагает все инструменты, необходимые для создания, редактирования, объединения и защиты ваших файлов PDF. Это полный набор простых в использовании инструментов, которые помогут вам выполнять работу быстрее.
Безопасная загрузка и хранение файлов
Все загружаемые файлы зашифрованы через HTTPS для защиты вашего контента. Файлы хранятся в защищенной базе данных, управляемой облачным хостингом Amazon. Вы можете удалить свои файлы из нашей системы в любое время.
Доступ к файлам из любого места
DocFly — это онлайн-сервис, доступный через любое устройство, подключенное к Интернету.Вы можете получить доступ к своему файлу из дома, офиса или где-либо еще.
Всегда в курсе
DocFly находится в облаке, поэтому всякий раз, когда вы заходите на сайт, вы получаете доступ к последней версии программного обеспечения. Никаких длительных обновлений или загрузки программного обеспечения не требуется.
Готовы извлечь страницы из PDF?
СОЗДАТЬ PDF
ИЗМЕНИТЬ PDF
ПРЕОБРАЗОВАТЬ PDF
Как извлечь PDF-страницы из PDF бесплатно
Иногда вам нужен не полный PDF-файл, а только его часть.Например, если файл слишком велик для размещения на жестком диске, но вас интересуют только несколько страниц этого файла PDF, то вы можете сохранить на жесткий диск только эту часть.
Вы все еще ищете, как извлечь некоторые страницы из нужного PDF-файла? Я часто вижу друзей, которые ищут решения в Интернете, потому что файлы PDF не так легко редактировать, как Word, Excel и другие форматы файлов. Копировать его после форматирования слишком сложно. Но знаете ли вы, что извлекать файлы PDF просто? Чтобы сделать PDF-файл более стильным и тонким, вам понадобятся эти инструменты.
Часть первая — Как извлечь страницы PDF с помощью онлайн-инструментов
Лучший способ извлечь PDF-файл — использовать специальный инструмент PDF. Возможно, вы увидите, что есть рекомендации, что вы можете извлекать PDF-страницы только с помощью браузера или каких-то уникальных методов, и вам не нужно использовать профессиональные инструменты PDF, но вы должны знать, что эти методы не являются панацеей. из. Например, если вы используете браузер, вам нужно обратить внимание на то, есть ли у вас принтер, иначе сохраненный файл, скорее всего, будет пустым.Так что, если вы боитесь неприятностей и вам нужен специальный инструмент PDF, вы можете использовать онлайн-инструмент PDF. Мы порекомендуем вам два бесплатных и простых в использовании PDF-решения.
1. EasePDF
EasePDF — наш первый рекомендуемый онлайн-инструмент для работы с PDF. Он бесплатный и простой в использовании и не требует от пользователей регистрации. EasePDF может эффективно извлекать нужные PDF-страницы, что также поддерживает кроссплатформенность. Всего несколько простых шагов, и задача может быть выполнена.
Шаг 1. Перейдите на домашнюю страницу EasePDF и выберите «Разделить PDF».
Шаг 2. Загрузите файл PDF. Здесь вы можете нажать кнопку Добавить файл (ы) , чтобы загрузить целевой PDF-файл со своего локального компьютера, планшета или смартфона. Или вы можете напрямую перетащить PDF-файл в соответствующую область. Кроме того, вы можете импортировать PDF-файл из своих облачных учетных записей, таких как Google Drive, OneDrive и Dropbox.
Шаг 3. Теперь вы можете выбрать страницы, которые хотите извлечь.У вас есть два способа извлечь нужные страницы. Один — щелкать по страницам одну за другой; другой — использовать режим «Страница с X по X» и ввести номер страницы, которую вы хотите сохранить. Например, если вы хотите сохранить страницы с 5 по 10, просто введите страницы с 5 по 10. Затем нажмите Разделить PDF .
Шаг 4. Загрузите новый файл PDF, если задача выполнена. На этом этапе вы можете отправить электронное письмо другим пользователям или поделиться файлом с другими, скопировав URL-ссылку, которую EasePDF создает для вас.
Примечание
«Помните, что независимо от того, какой режим (мы представляем на шаге 3) вы выберете, выбранные вами страницы будут сохранены как новый файл PDF, а другие страницы не будут сохранены. И, пожалуйста, сначала разблокируйте свой файл PDF, если вы хотите извлечь PDF-файл, защищенный паролем «.
2. iLovePDF
iLovePDF — это надежный и комплексный онлайн-конвертер PDF. Этот онлайн-метод также прост в использовании. С iLovePDF вы можете легко извлекать свои PDF-страницы без каких-либо проблем.Его можно использовать на любых устройствах с современными браузерами.
Шаг 1. Выберите инструмент «Разделить PDF» на домашней странице iLovePDF.
Шаг 2. Затем вы можете загрузить файл PDF со своего компьютера, Google Диска или Dropbox. Также поддерживается перетаскивание файла прямо в таблицу.
Шаг 3. Выберите Извлечь страницы. Есть режимы, которые вы можете выбрать. Вы можете извлечь все страницы или определенный диапазон страниц, поэтому просто выберите ту, которая вам нужна.Не забудьте отметить предложение « Объединить извлеченные страницы в один файл PDF », иначе все страницы будут сохранены как отдельные файлы PDF. Затем щелкните Разделить PDF .
Шаг 4. Затем загрузите новый файл PDF. Вы можете сохранить файл обратно в свою облачную учетную запись и на компьютер или попробовать другие инструменты, которые рекомендует вам iLovePDF.
Часть вторая — Извлечение страниц PDF с помощью настольной программы
Однако, даже если вам не нравится использовать онлайн-инструменты PDF, вот несколько автономных PDF-программ.Они также просты в использовании и не требуют подключения к сети для работы. Но нужно отметить, что Adobe Acrobat Pro DC — это профессиональная программа для работы с PDF, которая требует оплаты. Вы можете подать заявку на 7-дневную бесплатную пробную версию, прежде чем решить, покупать ее или нет.
1. Adobe Acrobat Pro DC
Когда дело доходит до настольных программ PDF, следует упомянуть Adobe. Adobe Acrobat Pro DC — это профессиональный инструмент для работы с PDF, особенно подходящий для малых и крупных предприятий для обработки файлов PDF.С его помощью вы можете эффективно извлекать файлы PDF. Он может хорошо работать как на Windows, так и на Mac.
Шаг 1. Подайте заявку на получение бесплатной пробной версии, если вы еще не приобрели ее и хотите попробовать. Если у вас уже есть, просто проигнорируйте этот шаг.
Шаг 2. Откройте инструмент > Упорядочить страницы . Если вы всегда будете использовать его, вы можете щелкнуть по этому инструменту, затем перетащить его в таблицу справа, и вы сможете быстро найти его в следующий раз.
Шаг 3. Нажмите кнопку Выбрать файл , чтобы выбрать файл PDF, из которого вы хотите извлечь страницы.
Шаг 4. Теперь щелкните страницы, которые вы хотите извлечь. Если вы хотите извлечь более одной страницы, нажмите Ctrl и продолжайте щелкать по страницам. Или вы можете ввести в поле Диапазон страниц.
Шаг 5. Наконец, нажмите кнопку Извлечь . Вы увидите, что есть варианты, которые вы можете выбрать.Установите флажок Удалить страницы после извлечения , если вы хотите удалить страницы из исходного PDF-файла при извлечении. У вас будет только PDF-файл, содержащий выбранные вами страницы. Отметьте Извлечь страницы как отдельные файлы , чтобы извлечь каждую выбранную страницу как отдельный файл PDF. Затем нажмите Extract .
Шаг 6. У вас будет предварительный просмотр вашего PDF-файла, поэтому не беспокойтесь, если вы допустите ошибку. После этого сохраните файл PDF.Переименуйте файл PDF и выберите для него место.
2.2 PDFsam Basic
Другая офлайн-программа для работы с PDF-файлами может извлекать PDF-страницы бесплатно. В то же время вы также можете сжать PDF-файл в процессе извлечения, чтобы уменьшить занимаемое пространство для хранения. Но только несколько инструментов, в том числе Extract PDF, можно использовать бесплатно.
Шаг 1. Загрузите и установите PDFsam Basic.
Шаг 2. Теперь откройте инструмент Извлечь PDF .
Шаг 3. Загрузите PDF-файл, из которого вы хотите извлечь страницы. Однако у вас не может быть предварительного просмотра в PDFsam Basic, поэтому вы можете только ввести номера страниц, которые хотите сохранить, а затем выбрать место для нового файла PDF.
Шаг 4. Если вы хотите одновременно сжать файл, щелкните Скрыть дополнительные настройки > Сжать выходной файл / файлы . Затем переименуйте файл PDF и, наконец, нажмите кнопку «Выполнить », чтобы начать процесс.
Заключение
Выше приведены несколько способов извлечения страниц PDF. Вы узнали, что это было не так сложно, как вы думаете? Есть и другие способы. Если у вас есть хорошие способы поделиться с нами, оставьте комментарий или свяжитесь с нами. Любые отзывы приветствуются.
Как извлечь текст или изображения из файла PDF
Файлы PDF отлично подходят для обмена отформатированными файлами между платформами и между людьми, которые не используют одно и то же программное обеспечение, но иногда нам нужно извлечь текст или изображения из файла PDF и использовать их на веб-страницах, в текстовых документах, презентациях PowerPoint, или в программном обеспечении для настольных издательских систем.
В зависимости от ваших потребностей и параметров безопасности, установленных в отдельном PDF-файле, у вас есть несколько вариантов извлечения текста, изображений или того и другого из файла PDF. Выберите наиболее подходящий для вас вариант.
Бен Майнерс / Getty ImagesИспользуйте Adobe Acrobat Professional . Если у вас есть полная версия Adobe Acrobat, а не только бесплатная программа Acrobat Reader, вы можете извлекать отдельные изображения или все изображения, а также текст из PDF-файла и экспортировать в различные форматы, такие как EPS, JPG и TIFF.Чтобы извлечь информацию из PDF в Acrobat DC, выберите Инструменты > Экспорт PDF и выберите нужный вариант. Чтобы извлечь текст, экспортируйте PDF-файл в формат Word или расширенный текстовый формат и выберите один из нескольких дополнительных параметров, которые включают:
- Сохранить плавный текст
- Сохранить макет страницы
- Включить комментарии
- Включить изображения
Скопируйте и вставьте из PDF с помощью Acrobat Reader . Если у вас есть Acrobat Reader, вы можете скопировать часть файла PDF в буфер обмена и вставить ее в другую программу.Для текста просто выделите часть текста в PDF и нажмите Ctrl + C , чтобы скопировать его.
Затем откройте текстовый редактор, например Microsoft Word, и нажмите Ctrl + V , чтобы вставить текст. С изображением щелкните изображение, чтобы выбрать его, а затем скопируйте и вставьте его в программу, поддерживающую изображения, используя те же команды клавиатуры.
Откройте файл PDF в графической программе . Если вашей целью является извлечение изображений, вы можете открыть PDF-файл в некоторых программах для иллюстраций, таких как более новые версии Photoshop, CorelDRAW или Adobe Illustrator, и сохранить изображения для редактирования и использования в настольных издательских приложениях.
Используйте сторонние программные средства для извлечения PDF . Доступно несколько автономных утилит и подключаемых модулей, которые конвертируют файлы PDF в HTML с сохранением макета страницы, извлекают и конвертируют содержимое PDF в форматы векторной графики, а также извлекают содержимое PDF для использования в программном обеспечении для обработки текстов, презентаций и настольных издательских систем. Эти инструменты предлагают различные варианты, включая пакетное извлечение / преобразование, извлечение всего файла или частичного содержимого, а также поддержку нескольких форматов файлов.В основном это коммерческие и условно-бесплатные утилиты для Windows.
Используйте онлайн-инструменты для извлечения PDF . Благодаря онлайн-инструментам извлечения вам не нужно загружать или устанавливать программное обеспечение. Сколько каждый может извлечь, варьируется. Например, с помощью ExtractPDF.com вы загружаете файл размером до 14 МБ или указываете URL-адрес PDF-файла для извлечения изображений, текста или шрифтов.
Сделайте снимок экрана . Перед тем, как сделать снимок экрана изображения в PDF, максимально увеличьте его в окне на экране.На ПК выберите строку заголовка окна PDF и нажмите Alt + PrtScn . На Mac нажмите Command + Shift + 4 и используйте появившийся курсор, чтобы перетащить и выбрать область, которую вы хотите захватить.
Спасибо, что сообщили нам!
Расскажите почему!
Другой Недостаточно подробностей Сложно понять .
Ваш комментарий будет первым