Что такое файловое хранилище больших данных?—Portal for ArcGIS
О файловых хранилищах больших данных
Файловое хранилище больших данных представляет собой созданный на портале элемент, который ссылается на данные объектов (точки, полилинии, полигоны или табличные данные) в местоположении, доступном для ArcGIS GeoAnalytics Server. Элемент файлового хранилища больших данных на портале позволяет просматривать зарегистрированные данные с помощью инструментов ArcGIS GeoAnalytics Server. Файловые хранилища больших данных могут ссылаться на следующие источники данных:
- Файловое хранилище – директория наборов данных на локальном или сетевом диске.
- HDFS – каталог наборов данных HDFS (Hadoop Distributed File System).
- Hive – базы данных метахранилища.
- Облачное хранилище – блок Amazon Web Services (AWS) Simple Storage Service (S3) или контейнер Microsoft Azure Blob, содержащий директорию с наборами данных.
 Облачные хранилища доступны начиная с ArcGIS 10.5.1.
Облачные хранилища доступны начиная с ArcGIS 10.5.1.
 Облачные хранилища доступны начиная с ArcGIS 10.5.1.
Облачные хранилища доступны начиная с ArcGIS 10.5.1.Файловое хранилище больших данных доступно, если администратор портала включил GeoAnalytics Server. Подробнее о включении GeoAnalytics Server см. в разделе Настройка ArcGIS GeoAnalytics Server.
Существует несколько причин, почему предпочтительнее использовать файловое хранилище больших данных, общее для всех источников данных. Вы можете хранить свои данные в доступном месте до тех пор, пока не будете готовы выполнить анализ. Файловое хранилище больших данных позволяет работать с данными во время выполнения анализа, поэтому вы можете продолжать добавлять данные в набор, находящийся в файловом хранилище больших данных, без необходимости перерегистрации или опубликования своих данных. Вы также можете изменить манифест, чтобы удалить, добавить или обновить наборы данных в файловом хранилище больших данных. Файловое хранилище больших данных отличается необычайной гибкостью с точки зрения определения геометрии и времени и допускает несколько форматов времени в отдельном наборе данных. Файловые хранилища больших данных позволяют разбивать наборы данных на разделы, сохраняя способность работы с несколькими такими разделами как с единым набором данных.
Файловые хранилища больших данных позволяют разбивать наборы данных на разделы, сохраняя способность работы с несколькими такими разделами как с единым набором данных.
Файловые хранилища больших данных становятся доступны только при запуске GeoAnalytics Tools. Это означает, что вы можете только просматривать и добавлять файлы больших данных в анализ; вы не можете визуализировать эти данные на карте.
Файловые хранилища больших данных являются одним из нескольких доступа GeoAnalytics Tools к вашим данным. Список возможных входных данных, которые используют GeoAnalytics Tools см. в разделе GeoAnalytics Tools. Использование во вьюере карт портала.
Подготовка данных для регистрации файлового хранилища больших данных
Файловые хранилища и HDFS
Чтобы подготовить данные для файлового хранилища больших данных необходимо представить наборы данных вложенными папками отдельной родительской папки, которая будет регистрироваться. В зарегистрированной родительской папке имена вложенных папок будут совпадать с именами наборов данных. Если эти вложенные папки будут содержать несколько подпапок или файлов, то все содержимое этих вложенных папок высшего уровня будет считаться отдельным набором данных. Ниже – пример, как зарегистрировать папку FileShareFolder, в которой содержится три набора данных, имена которых Earthquakes, Hurricanes и GlobalOceans. При регистрации родительской папки все подкаталоги указанной папки также регистрируются на сервере GeoAnalytics Server. Всегда регистрируйте родительскую папку (например, \\machinename\FileShareFolder), содержащую один или несколько подпапок отдельных наборов данных.
Если эти вложенные папки будут содержать несколько подпапок или файлов, то все содержимое этих вложенных папок высшего уровня будет считаться отдельным набором данных. Ниже – пример, как зарегистрировать папку FileShareFolder, в которой содержится три набора данных, имена которых Earthquakes, Hurricanes и GlobalOceans. При регистрации родительской папки все подкаталоги указанной папки также регистрируются на сервере GeoAnalytics Server. Всегда регистрируйте родительскую папку (например, \\machinename\FileShareFolder), содержащую один или несколько подпапок отдельных наборов данных.
|---FileShareFolder < -- The top-level folder is what is registered as a big data file share
|---Earthquakes < -- A dataset is all files and folders within the top-level subfolder
|---1960
|---01_1960.csv
|---02_1960. csv
|---1961
|---01_1961.csv
|---02_1961.csv
|---Hurricanes
|---atlantic_hur.shp
|---pacific_hur.shp
|---otherhurricanes.shp
|---GlobalOceans
|---oceans.shp csv
|---1961
|---01_1961.csv
|---02_1961.csv
|---Hurricanes
|---atlantic_hur.shp
|---pacific_hur.shp
|---otherhurricanes.shp
|---GlobalOceans
|---oceans.shp
csv
|---1961
|---01_1961.csv
|---02_1961.csv
|---Hurricanes
|---atlantic_hur.shp
|---pacific_hur.shp
|---otherhurricanes.shp
|---GlobalOceans
|---oceans.shpТакая же структура используется в файловом хранилище и HDFS, хотя терминология отличается. В файловом хранилище имеется папка или каталог высшего уровня, а наборы данных представлены вложенными папками. В HDFS местоположение файлового хранилища зарегистрировано и содержит наборы данных. В следующей таблице приводится описание различий:
| Файловое хранилище | HDFS | |
|---|---|---|
Местоположение файлового хранилища больших данных | Папка или директория | HDFS-путь |
Наборы данных | Вложенные папки высшего уровня | Наборы данных в HDFS-пути |
После того как данные будут организованы в виде папки с вложенными подпапками наборов данных, сделайте их доступными для GeoAnalytics Server, выполнив шаги, указанные в разделе Предоставление доступа к данным ArcGIS Server и зарегистрируйте папку набора данных.
Корневая ветвь реестра
В Hive – базе данных метахранилища все таблицы в базе данных признаются в качестве наборов данных в файловом хранилище больших данных. В следующем примере показано метахранилище с двумя базами данных, default и CityData. При регистрации файлового хранилища больших данных Hive через ArcGIS Server с GeoAnalytics Server, можно выбрать только одну базу данных. В этом примере, если бы была выбрана база данных CityData, то в файловом хранилище больших данных было бы два набора данных, FireData и LandParcels.
|---HiveMetastore < -- The top-level folder is what is registered as a big data file share |---default < -- A database |---Earthquakes |---Hurricanes |---GlobalOceans |---CityData < -- A database that is registered (specified in Server Manager) |---FireData |---LandParcelsОблачные хранилища
Далее приведены три шага для регистрации файлового хранилища больших данных, имеющего тип облачного хранилища.
Подготовка ваших данных
Чтобы подготовить данные для файлового хранилища больших данных в облачном хранилище, отформатируйте ваши наборы данных, как вложенные папки внутри отдельной родительской папки.
Ниже приводится пример возможной структуры ваших данных. В данном примере показана регистрация родителькой папки, FileShareFolder, в которой содержится три набора данных с именами Earthquakes, Hurricanes и GlobalOceans. При регистрации родительской папки, все вложенные папки внутри указанной папки также регистрируются на сервере GeoAnalytics Server.
Пример структурирования данных в облачном хранилище, которое будет использоваться в качестве файлового хранилища больших данных. Это файловое хранилище больших данных содержит три набора данных: Earthquakes, Hurricanes и GlobalOceans.
|---Cloud Store < -- The cloud store being registered |---Container or S3 Bucket Name < -- The container (Azure) or bucket (Amazon) being registered as part of the cloud store |---FileShareFolder < -- The parent folder that is registered as the 'folder' during cloud store registration |---Earthquakes < -- The dataset "Earthquakes" composed of 4 csvs |---1960 |---01_1960.
 csv
|---02_1960.csv
|---1961
|---01_1961.csv
|---02_1961.csv
|---Hurricanes < -- The dataset "Hurricanes" composed of 3 shapefiles
|---atlantic_hur.shp
|---pacific_hur.shp
|---otherhurricanes.shp
|---GlobalOceans < -- The dataset "GlobalOceans" composed of 1 shapefile
|---oceans.shp
csv
|---02_1960.csv
|---1961
|---01_1961.csv
|---02_1961.csv
|---Hurricanes < -- The dataset "Hurricanes" composed of 3 shapefiles
|---atlantic_hur.shp
|---pacific_hur.shp
|---otherhurricanes.shp
|---GlobalOceans < -- The dataset "GlobalOceans" composed of 1 shapefile
|---oceans.shpЗарегистрируйте облачное хранилище на вашем GeoAnalytics Server
Подключитесь к своему сайту GeoAnalytics Server из ArcGIS Server Manager для регистрации облачного хранилища. Когда вы регистрируете облачное хранилище, необходимо включить имя контейнера Azure или имя сегмента AWS S3, а также папку внутри контейнера или сегмента. Указанная папка состоит из вложенных папок, и каждая представлена, как отдельный набор данных. Каждый набор данных состоит из всего содержания вложенной папки.
Регистрация облачного хранилища в качестве файлового хранилища больших данных
Метод регистрации облачного хранилища в качестве файлового хранилища больших данных зависит от того, какое облачное хранилище вы используете.
Следуйте приведенным шагам для регистрации облачного хранилища AWS S3, которое вы создали в предыдущем разделе, в качестве файлового хранилища больших данных:
- Выполните вход на ваш сайт GeoAnalytics Server из ArcGIS Server Manager.
Вы можете войти как издатель или как администратор.
В GeoAnalytics Server 10.5.1 нельзя зарегистрировать облачное хранилище AWS используя учетные данные IAM.
- Перейдите к Сайт > Хранилища данных и выберите Файловое хранилище больших данных из ниспадающего списка Зарегистрировать.
- Предоставьте следующую информацию в диалоговом окне Зарегистрировать файловое хранилище больших данных:
- Введите имя файлового хранилища больших данных.
- Выберите Облачное хранилище в ниспадающем списке Тип.
- Выберите имя вашего облачного хранилища данных AWS в ниспадающем списке Облачное хранилище.
- Щелкните Создать, чтобы зарегистрировать ваше облачное хранилище в качестве файлового хранилища больших данных.

Теперь у вас есть файловое хранилище больших данных и манифест для облачного хранилища AWS. Элемент файлового хранилища больших данных на портале ссылается на сервис каталога больших данных в GeoAnalytics Server.
Следуйте приведенным шагам для регистрации облачного хранилища Azure, которое вы создали в последнем разделе, в качестве файлового хранилища больших данных:
ArcGIS Server Administrator Directory требует выполнения входа в качестве администратора. Чтобы подключиться к интегрированному сайту GeoAnalytics Server, необходимо выполнить вход с помощью токена портала, что требует учетных данных администратора, или в качестве основного администратора сайта GeoAnalytics Server. Если вы не являетесь администратором портала или не имеете доступа к информации учетной записи основного администратора сайта, свяжитесь с администратором вашего портала, чтобы он выполнил эти шаги.
- Перейдите к data > registerItem.
- Скопируйте следующий текст и вставьте его в текстовое поле Элемент. Обновите значение <bigDataFileShareName>, используя имя, которое вы хотите использовать для файлового хранилища больших данных, и значение <cloudStoreName>, используя имя, указанное для облачного хранилища Azure при регистрации его на сайте GeoAnalytics Server.
{ "path": "/bigDataFileShares/<bigDataFileShareName>", "type": "bigDataFileShare", "info": { "connectionString": "{\"path\" : \"/cloudStores/<cloudStoreName>\"}", "connectionType": "dataStore" } } - Щелкните Зарегистрировать элемент.
После того, как элемент зарегистрирован, файловое хранилище больших данных появится в качестве хранилища данных в ArcGIS Server Manager.
- Выполните вход на ваш сайт GeoAnalytics Serverсайт GeoAnalytics Server из ArcGIS Server Manager.
Вы можете войти как издатель или как администратор.
- Перейдите к Сайт > Хранилища данных и щелкните кнопку Создать заново манифест рядом с новым файловым хранилищем больших данных.


Теперь у вас есть файловое хранилище больших данных и манифест для облачного хранилища Azure. Элемент файлового хранилища больших данных на портале ссылается на сервис каталога больших данных в GeoAnalytics Server.
Регистрация файлового хранилища больших данных
Чтобы зарегистрировать файловое хранилище, HDFS или облачное хранилище Hive в качестве файлового хранилища больших данных, подключитесь к сайту GeoAnalytics Server через ArcGIS Server Manager. Более подробно о необходимых для регистрации действиях см. Регистрация данных в ArcGIS Server с помощью Manager в ArcGIS Server.
Подсказка:
Шаги для регистрации облачного хранилища в качестве файлового хранилища больших данных были приведены в предыдущем разделе.
После регистрации файлового хранилища больших данных будет сгенерирован манифест, в котором указывается формат наборов данных в местоположении этого хранилища и в том числе поля, представляющие геометрию и время. Файловое хранилище больших данных создается на портале, который ссылается на сервис каталога больших данных в GeoAnalytics Server, где эти данные зарегистрированы. Более подробно о сервисах каталога больших данных см. документацию Сервис каталога больших данных в Справке ArcGIS Services REST API.
Файловое хранилище больших данных создается на портале, который ссылается на сервис каталога больших данных в GeoAnalytics Server, где эти данные зарегистрированы. Более подробно о сервисах каталога больших данных см. документацию Сервис каталога больших данных в Справке ArcGIS Services REST API.
Изменение файлового хранилища больших данных
После создания сервиса каталога больших данных автоматически генерируется манифест, который загружается на сайт GeoAnalytics Server, где эти данные зарегистрированы. В процессе генерации манифеста в наборе данных не всегда правильно определяются поля геометрии и времени, может потребоваться корректировка. Для внесения изменений в манифест выполните шаги из раздела Редактирование файловых хранилищ больших данных в Manager. Дополнительные сведения о манифесте файлового хранилища больших данных см. в разделе Знакомство с манифестом файлового хранилища больших данных Справки ArcGIS Server.
Выполнение анализа на файловом хранилище больших данных
Выполнение анализа набора данных из файлового хранилища больших данных возможно через любой клиент, который поддерживает GeoAnalytics Server, включая:
- ArcGIS Pro
- Вьюер карт Portal for ArcGIS
- ArcGIS REST API
Для выполнения анализа на файловом хранилище больших данных посредством вьюера карт ArcGIS Pro или Portal for ArcGIS, выберите GeoAnalytics Tools, который вы хотели бы использовать. Перейдите к месту расположения данных, которые будут использоваться в качестве входных для этого инструмента, под Портал в ArcGIS Pro или в диалоговом окне Обзор слоев во вьюере карт Portal for ArcGIS. Данные будут в Мои ресурсы, если вы сами регистрировали эти данные. Если не сами, то проверьте Группы или Весь портал. Примите к сведению, что слой файлового хранилища больших данных, который выбран для анализа, не будет отображаться на карте.
Перейдите к месту расположения данных, которые будут использоваться в качестве входных для этого инструмента, под Портал в ArcGIS Pro или в диалоговом окне Обзор слоев во вьюере карт Portal for ArcGIS. Данные будут в Мои ресурсы, если вы сами регистрировали эти данные. Если не сами, то проверьте Группы или Весь портал. Примите к сведению, что слой файлового хранилища больших данных, который выбран для анализа, не будет отображаться на карте.
Убедитесь, что вы выполнили вход на портал под учетной записью с доступом к зарегистрированному файловому хранилищу больших данных. Чтобы быстро найти все доступные для вас файловые хранилища больших данных выполните поиск на портале по условию bigDataFileShare*.
Для выполнения анализа на файловом хранилище больших данных посредством ArcGIS REST API используйте в качестве входных данных URL-адрес сервиса каталога больших данных. URL-адрес будет иметь формат {«url»:» https://webadaptorhost.domain.com/webadaptorname/rest/DataStoreCatalogs/bigDataFileShares_filesharename/BigDataCatalogServer/dataset»}.
Отзыв по этому разделу?
Начало работы с файловыми хранилищами больших данных—ArcGIS GeoAnalytics Server
О файловых хранилищах больших данных
Файловое хранилище больших данных представляет собой созданный на портале элемент, который ссылается на данные местоположений, доступные на вашем ArcGIS GeoAnalytics Server. Расположение файлового хранилища больших данных может использоваться в качестве входных и выходных данных для векторных данных (точек, полилиний, полигонов и табличных данных) инструментов геоаналитики.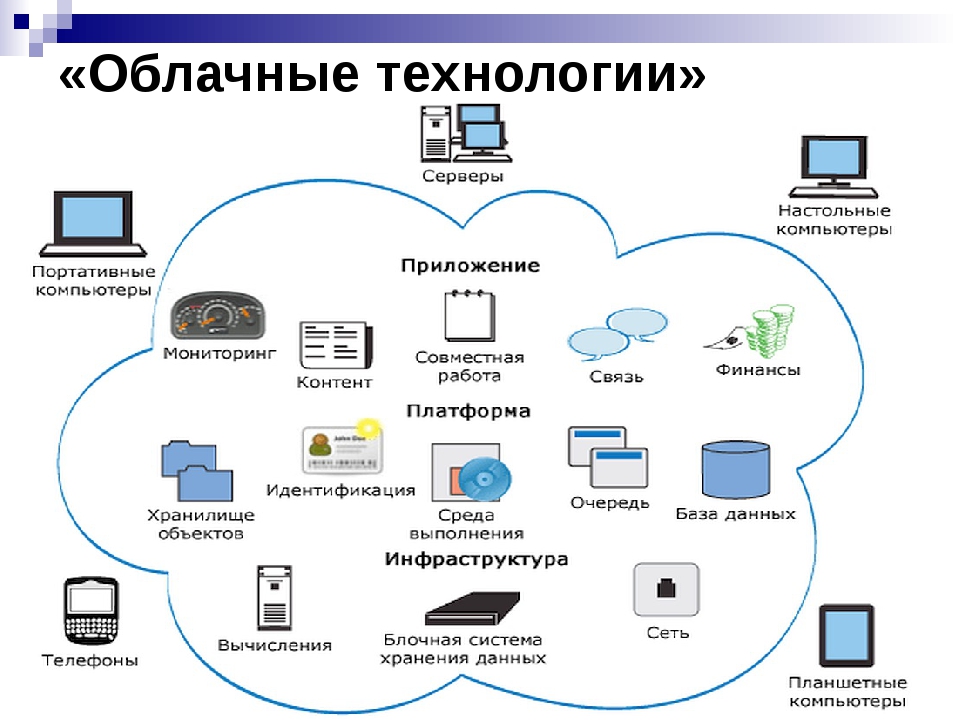 При создании файлового хранилища больших данных генерируется элемент на вашем портале. Элемент указывает на сервис каталога больших данных, который описывает наборы данных в файловом хранилище больших данных и их схему, включая геометрию и информацию о времени, а также выходные форматы, называемые шаблонами, которые вы зарегистрировали. При использовании файлового хранилища больших данных в качестве входных данных в инструменте ArcGIS GeoAnalytics Server, вы можете указать путь к этому элементу и запустить анализ для набора данных.
При создании файлового хранилища больших данных генерируется элемент на вашем портале. Элемент указывает на сервис каталога больших данных, который описывает наборы данных в файловом хранилище больших данных и их схему, включая геометрию и информацию о времени, а также выходные форматы, называемые шаблонами, которые вы зарегистрировали. При использовании файлового хранилища больших данных в качестве входных данных в инструменте ArcGIS GeoAnalytics Server, вы можете указать путь к этому элементу и запустить анализ для набора данных.
Существует несколько причин, почему предпочтительнее использовать файловое хранилище больших данных. Вы можете хранить свои данные в доступном месте до тех пор, пока не будете готовы выполнить анализ. Файловое хранилище больших данных позволяет работать с данными во время выполнения анализа, поэтому вы можете продолжать добавлять данные в набор, находящийся в файловом хранилище больших данных, без необходимости перерегистрации или опубликования своих данных. Вы также можете изменить манифест, чтобы удалить, добавить или обновить наборы данных в файловом хранилище больших данных. Файловое хранилище больших данных отличается необычайной гибкостью с точки зрения определения геометрии и времени и допускает несколько форматов времени в отдельном наборе данных. Файловые хранилища больших данных позволяют разбивать наборы данных на разделы, сохраняя способность работы с несколькими такими разделами как с единым набором данных. Использование файлового хранилища больших данных для выходных данных позволяет хранить результаты в форматах, которые можно использовать для других рабочих процессов, таких как файл parquet для дальнейшего анализа или хранения.
Вы также можете изменить манифест, чтобы удалить, добавить или обновить наборы данных в файловом хранилище больших данных. Файловое хранилище больших данных отличается необычайной гибкостью с точки зрения определения геометрии и времени и допускает несколько форматов времени в отдельном наборе данных. Файловые хранилища больших данных позволяют разбивать наборы данных на разделы, сохраняя способность работы с несколькими такими разделами как с единым набором данных. Использование файлового хранилища больших данных для выходных данных позволяет хранить результаты в форматах, которые можно использовать для других рабочих процессов, таких как файл parquet для дальнейшего анализа или хранения.
Файловые хранилища больших данных становятся доступны только при запуске GeoAnalytics Tools. Это означает, что вы можете только просматривать и добавлять файлы больших данных в анализ; вы не можете визуализировать эти данные на карте.
Файловые хранилища больших данных могут ссылаться на следующие источники входных данных:
- Файловое хранилище – директория наборов данных на локальном или сетевом диске.
- Apache Hadoop Distributed File System (HDFS) – директория HDFS наборов данных.
- Apache Hive – базы данных метахранилища Hive.
- Облачное хранилище – Amazon Simple Storage Service (S3) контейнер, контейнер Blob-объектов Microsoft Azure или хранилище Microsoft Azure Data Lake, содержащее каталог наборов данных.

При записи результатов в общую папку с большими данными вы можете использовать следующие выходные данные GeoAnalytics Tools:
- Файловое хранилище
- HDFS
- Облачное хранилище
Следующие типы файлов поддерживаются в качестве наборов входных и выходных данных в файловых хранилищах больших данных:
- Файлы с разделителями (такие как .csv, .tsv и .txt)
- Шейп-файлы (.shp)
- Файлы Parquet (.gz.parquet)
- Файлы ORC (orc.crc)
Файловое хранилище больших данных доступно, если администратор портала включил GeoAnalytics Server. Более подробно о включении GeoAnalytics Server см. в разделе Настройка ArcGIS GeoAnalytics Server.
Более подробно о включении GeoAnalytics Server см. в разделе Настройка ArcGIS GeoAnalytics Server.
Файловые хранилища больших данных являются одним из нескольких способов доступа GeoAnalytics Tools к вашим данным и не являются обязательными для GeoAnalytics Tools. См. Использование GeoAnalytics Tools в Map Viewer для получения списка возможных форматов входных и выходных данных GeoAnalytics Tools.
Вы можете зарегистрировать сколько угодно файловых хранилищ больших данных. В каждом из файловых хранилищ больших данных может быть любое количество наборов данных.
В таблице ниже приведены некоторые важные термины, относящиеся к файловым хранилищам больших данных.
| Термин | Описание |
|---|---|
Файловое хранилище больших данных | Расположение данных, зарегистрированное для вашего GeoAnalytics Server для использования в качестве входного, выходного или и входного, и выходного набора данных в инструментах геоаналитики. |
Сервис каталога больших данных | Сервис, который описывает входные наборы данных и схемы, а также имена выходных шаблонов файлового хранилища больших данных. Он создается при регистрации файлового хранилища больших данных и создании манифеста. Более подробно о сервисах каталога больших данных см. документацию Сервис каталога больших данных в Справке ArcGIS Services REST API. |
Элемент файлового хранилища больших данных | Элемент портала, ссылающийся на сервис каталога больших данных. Вы можете управлять тем, кто может использовать ваше файловое хранилище больших данных в качестве входных данных для инструментов GeoAnalytics, настроив общий доступ к этому элементу на портале. |
Манифест | Файл JSON, который описывает доступные наборы данных и схему для входных данных в вашем файловом хранилище больших данных. |
Выходные шаблоны | Один или несколько шаблонов, описывающих тип файла и необязательное форматирование при записи результатов в файловое хранилище больших данных. Например, шаблон может задать запись результатов в шейп-файл. Файловое хранилище больших данных может иметь один или несколько шаблонов, либо не иметь шаблонов. |
Тип файлового хранилища больших данных | Тип расположений, которые вы регистрируете. Например, у вас может быть файловое хранилище больших данных или тип HDFS. |
Формат файлового хранилища больших данных | Формат данных, которые вы читаете или записываете. |
Файл hints | Необязательный файл, который может применяться для создания манифеста для файлов с разделителями, используемых в качестве входных данных. |

 Манифест создается автоматически при регистрации файлового хранилища больших данных и может быть изменен путем редактирования или с помощью файла hints. Одно файловое хранилище больших данных имеет один манифест.
Манифест создается автоматически при регистрации файлового хранилища больших данных и может быть изменен путем редактирования или с помощью файла hints. Одно файловое хранилище больших данных имеет один манифест. Например, типом файла может быть шейп-файл.
Например, типом файла может быть шейп-файл.Подготовка данных для регистрации файлового хранилища больших данных
Чтобы использовать ваши наборы данных в качестве входных в файловом хранилище больших данных, убедитесь, что ваши данные корректного формата. См. информацию ниже о форматировании на основе типа файлового хранилища больших данных.
Файловые хранилища и HDFS
Чтобы подготовить данные для файлового хранилища больших данных необходимо представить наборы данных вложенными папками отдельной родительской папки, которая будет зарегистрирована. В этой регистрируемой родительской папке имена вложенных папок будут совпадать с именами наборов данных. Если эти вложенные папки будут содержать несколько подпапок или файлов, то все содержимое этих вложенных папок высшего уровня будет считаться отдельным набором данных, и к ним будет применяться та же схема. Ниже – пример, как зарегистрировать папку ,FileShareFolder в которой содержится три набора данных, имена которых Earthquakes, Hurricanes и GlobalOceans. При регистрации родительской папки все подкаталоги указанной папки также регистрируются на GeoAnalytics Server. Всегда регистрируйте родительскую папку (например, \\machinename\FileShareFolder), содержащую один или несколько подпапок отдельных наборов данных.
Если эти вложенные папки будут содержать несколько подпапок или файлов, то все содержимое этих вложенных папок высшего уровня будет считаться отдельным набором данных, и к ним будет применяться та же схема. Ниже – пример, как зарегистрировать папку ,FileShareFolder в которой содержится три набора данных, имена которых Earthquakes, Hurricanes и GlobalOceans. При регистрации родительской папки все подкаталоги указанной папки также регистрируются на GeoAnalytics Server. Всегда регистрируйте родительскую папку (например, \\machinename\FileShareFolder), содержащую один или несколько подпапок отдельных наборов данных.
Пример файлового хранилища больших данных, в котором содержится три набора данных: Earthquakes, Hurricanes и GlobalOceans.
|---FileShareFolder < -- The top-level folder is what is registered as a big data file share
|---Earthquakes < -- A dataset "Earthquakes", composed of 4 csvs with the same schema
|---1960
|---01_1960. csv
|---02_1960.csv
|---1961
|---01_1961.csv
|---02_1961.csv
|---Hurricanes < -- The dataset "Hurricanes", composed of 3 shapefiles with the same schema
|---atlantic_hur.shp
|---pacific_hur.shp
|---otherhurricanes.shp
|---GlobalOceans < -- The dataset "GlobalOceans", composed of a single shapefile
|---oceans.shp csv
|---02_1960.csv
|---1961
|---01_1961.csv
|---02_1961.csv
|---Hurricanes < -- The dataset "Hurricanes", composed of 3 shapefiles with the same schema
|---atlantic_hur.shp
|---pacific_hur.shp
|---otherhurricanes.shp
|---GlobalOceans < -- The dataset "GlobalOceans", composed of a single shapefile
|---oceans.shp
csv
|---02_1960.csv
|---1961
|---01_1961.csv
|---02_1961.csv
|---Hurricanes < -- The dataset "Hurricanes", composed of 3 shapefiles with the same schema
|---atlantic_hur.shp
|---pacific_hur.shp
|---otherhurricanes.shp
|---GlobalOceans < -- The dataset "GlobalOceans", composed of a single shapefile
|---oceans.shpТакая же структура используется в файловом хранилище и HDFS, хотя терминология отличается. В файловом хранилище имеется папка или каталог высшего уровня, а наборы данных представлены вложенными папками. В HDFS расположение файлового хранилища зарегистрировано и содержит наборы данных. В следующей таблице приводится описание различий:
| Файловое хранилище | HDFS | |
|---|---|---|
Местоположение файлового хранилища больших данных | Папка или директория | Путь HDFS |
Наборы данных | Вложенные папки высшего уровня | Наборы данных в пути HDFS |
После того как данные будут организованы в виде папки с вложенными подпапками наборов данных, сделайте их доступными для GeoAnalytics Server, выполнив шаги, указанные в разделе Предоставление доступа к данным ArcGIS Server и зарегистрируйте папку набора данных.
Доступ к HDFS с помощью Kerberos
GeoAnalytics Server может обращаться к HDFS, используя аутентификацию Kerberos.
GeoAnalytics Server поддерживает защиту RCP, установленную на аутентификацию (hadoop.rpc.protection =authentication). GeoAnalytics Server в настоящее время не поддерживает режимы целостности (integrity) или частности (privacy).
Выполните следующие шаги, чтобы зарегистрировать файловое хранилище HDFS при помощи аутентификации Kerberos:
- В Windows скопируйте файл krb.ini в C:/windows/krb.ini на всех компьютерах вашего сайта GeoAnalytics Server. В Linux скопируйте файл krb.conf в /etc/krb.conf на всех компьютерах вашего сайта GeoAnalytics Server.
- Выполните вход на сайт GeoAnalytics Server из ArcGIS ServerArcGIS Server Administrator Directory.
ArcGIS Server Administrator Directory требует выполнения входа в качестве администратора. Чтобы подключиться к интегрированному сайту GeoAnalytics Server, необходимо выполнить вход с помощью токена портала, что требует учетных данных администратора, или в качестве основного администратора сайта GeoAnalytics Server.
Если вы не являетесь администратором портала или не имеете доступа к информации учетной записи основного администратора сайта, свяжитесь с администратором вашего портала, чтобы он выполнил эти шаги. - Перейдите к data > registerItem.
- Скопируйте следующий текст и вставьте его в текстовое поле Элемент. Обновите следующие значения:
- <bigDataFileShareName>: замените на имя для своего файлового хранилища больших данных.
- <hdfs path>: замените на полный системный путь к файловому хранилищу больших данных, например, hdfs://domainname:port/folder.
- <user@realm>: замените на имя пользователя и область участника.
- <keytab location>: замените на местоположение файла keytab. Файл keytab должен быть доступен для всех компьютеров сайта GeoAnalytics Server, например, //shared/keytab/hadoop.keytab.
{ "path": "/bigDataFileShares/<bigDataFileShareName>", "type": "bigDataFileShare", "info": { "connectionString": "{\"path\":\"<hdfs path>",\"accessMode\":\"Kerberos\",\"principal\":\"user@realm\",\"keytab\":\"<keytab location>\"}", "connectionType": "hdfs" } } - Щелкните Зарегистрировать элемент.
После того как элемент зарегистрирован, файловое хранилище больших данных появится в качестве хранилища данных в ArcGIS Server Manager, вместе с заполненным манифестом. Если манифест не заполнен, перейдите к шагу 5.
- Выполните вход на ваш сайт GeoAnalytics Server из ArcGIS Server Manager.
Вы можете войти как издатель или как администратор.
- Перейдите к Сайт > Хранилища данных и щелкните кнопку Создать заново манифест рядом с новым файловым хранилищем больших данных.
 Если вы не являетесь администратором портала или не имеете доступа к информации учетной записи основного администратора сайта, свяжитесь с администратором вашего портала, чтобы он выполнил эти шаги.
Если вы не являетесь администратором портала или не имеете доступа к информации учетной записи основного администратора сайта, свяжитесь с администратором вашего портала, чтобы он выполнил эти шаги.
Теперь у вас есть файловое хранилище больших данных и манифест для HDFS, к которому вы можете получить доступ при помощи аутентификации Kerberos. Элемент файлового хранилища больших данных на портале ссылается на сервис каталога больших данных в GeoAnalytics Server.
Hive
GeoAnalytics Server использует Spark 3.0.1. Hive должна быть версии 2.3.7 или 3.0.0–3.1.2.
Если вы тестируете и регистрируете файловое хранилище больших данных с Hive некорректной версии, зарегистрировать файловое хранилище больших данных не удастся. Если это произошло, перезапустите набор инструментов GeoAnalyticsManagement в ArcGIS Server Administrator Directory, > services > System > GeoAnalyticsManagement> stop. Повторите шаги для запуска.
Если это произошло, перезапустите набор инструментов GeoAnalyticsManagement в ArcGIS Server Administrator Directory, > services > System > GeoAnalyticsManagement> stop. Повторите шаги для запуска.
В Hive все таблицы в базе данных признаются в качестве наборов данных в файловом хранилище больших данных. В следующем примере показано метахранилище с двумя базами данных, default и CityData. При регистрации файлового хранилища больших данных Hive через ArcGIS Server на GeoAnalytics Server, можно выбрать только одну базу данных. В этом примере, если бы была выбрана база данных CityData, то в файловом хранилище больших данных было бы два набора данных, FireData и LandParcels.
|---HiveMetastore < -- The top-level folder is what is registered as a big data file share
|---default < -- A database
|---Earthquakes
|---Hurricanes
|---GlobalOceans
|---CityData < -- A database that is registered (specified in Server Manager)
|---FireData
|---LandParcelsОблачные хранилища
Далее приведены три шага для регистрации файлового хранилища больших данных, имеющего тип облачного хранилища.
Подготовка ваших данных
Чтобы подготовить данные для файлового хранилища больших данных в облачном хранилище, отформатируйте ваши наборы данных, как вложенные папки внутри отдельной родительской папки.
Ниже приводится пример возможной структуры ваших данных. В данном примере показана регистрация родительской папки, FileShareFolder, в которой содержится три набора данных с именами Earthquakes, Hurricanes и GlobalOceans. При регистрации родительской папки все подкаталоги указанной папки также регистрируются на GeoAnalytics Server.
Пример структурирования данных в облачном хранилище, которое будет использоваться в качестве файлового хранилища больших данных. Это файловое хранилище больших данных содержит три набора данных: Earthquakes, Hurricanes и GlobalOceans.
|---Cloud Store < -- The cloud store being registered
|---Container or S3 Bucket Name < -- The container (Azure) or bucket (Amazon) being registered as part of the cloud store
|---FileShareFolder < -- The parent folder that is registered as the 'folder' during cloud store registration
|---Earthquakes < -- The dataset "Earthquakes", composed of 4 csvs with the same schema
|---1960
|---01_1960. csv
|---02_1960.csv
|---1961
|---01_1961.csv
|---02_1961.csv
|---Hurricanes < -- The dataset "Hurricanes", composed of 3 shapefiles with the same schema
|---atlantic_hur.shp
|---pacific_hur.shp
|---otherhurricanes.shp
|---GlobalOceans < -- The dataset "GlobalOceans", composed of 1 shapefile
|---oceans.shp csv
|---02_1960.csv
|---1961
|---01_1961.csv
|---02_1961.csv
|---Hurricanes < -- The dataset "Hurricanes", composed of 3 shapefiles with the same schema
|---atlantic_hur.shp
|---pacific_hur.shp
|---otherhurricanes.shp
|---GlobalOceans < -- The dataset "GlobalOceans", composed of 1 shapefile
|---oceans.shp
csv
|---02_1960.csv
|---1961
|---01_1961.csv
|---02_1961.csv
|---Hurricanes < -- The dataset "Hurricanes", composed of 3 shapefiles with the same schema
|---atlantic_hur.shp
|---pacific_hur.shp
|---otherhurricanes.shp
|---GlobalOceans < -- The dataset "GlobalOceans", composed of 1 shapefile
|---oceans.shpРегистрация облачного хранилища на GeoAnalytics Server
Подключитесь к своему сайту GeoAnalytics Server из ArcGIS Server Manager для регистрации облачного хранилища. Когда вы регистрируете облачное хранилище, необходимо включить имя контейнера Azure, имя корзины Amazon S3 или имя хранилища Azure Data Lake. Рекомендуется также дополнительно указать папку в контейнере или сегменте. Указанная папка состоит из вложенных папок, и каждая представлена, как отдельный набор данных. Каждый набор данных состоит из всего содержания вложенной папки.
Регистрация облачного хранилища в качестве файлового хранилища больших данных
Следуйте приведенным шагам для регистрации облачного хранилища, которое вы создали в предыдущем разделе, в качестве файлового хранилища больших данных:
- Выполните вход на сайт GeoAnalytics Server из ArcGIS Server Manager.
Вы можете войти как издатель или как администратор.
- Перейдите к Сайт > Хранилища данных и выберите Файловое хранилище больших данных из ниспадающего списка Зарегистрировать.
- Предоставьте следующую информацию в диалоговом окне Зарегистрировать файловое хранилище больших данных:
- Введите имя файлового хранилища больших данных.
- Выберите Облачное хранилище в ниспадающем списке Тип.
- Выберите имя вашего облачного хранилища данных в ниспадающем списке Облачное хранилище.
- Щелкните Создать, чтобы зарегистрировать ваше облачное хранилище в качестве файлового хранилища больших данных.

Теперь у вас есть файловое хранилище больших данных и манифест для облачного хранилища . Элемент файлового хранилища больших данных на портале ссылается на сервис каталога больших данных в GeoAnalytics Server.
Регистрация файлового хранилища больших данных
Чтобы зарегистрировать файловое хранилище, HDFS или облачное хранилище Hive в качестве файлового хранилища больших данных, подключитесь к сайту GeoAnalytics Server через ArcGIS Server Manager. Более подробно о необходимых для регистрации действиях см. Регистрация данных в ArcGIS Server с помощью Manager в ArcGIS Server.
Подсказка:
Шаги для регистрации облачного хранилища в качестве файлового хранилища больших данных были приведены в предыдущем разделе.
После регистрации файлового хранилища больших данных будет сгенерирован манифест, в котором указывается формат наборов данных в местоположении этого хранилища и в том числе поля, представляющие геометрию и время. Если вы дополнительно выбрали регистрацию файлового хранилища больших данных в качестве расположения выходных данных, выходной шаблон манифеста также автоматически создается. Файловое хранилище больших данных создается на портале, который ссылается на сервис каталога больших данных в GeoAnalytics Server, где эти данные зарегистрированы. Более подробно о сервисах каталога больших данных см. документацию Сервис каталога больших данных в Справке ArcGIS Services REST API.
Файловое хранилище больших данных создается на портале, который ссылается на сервис каталога больших данных в GeoAnalytics Server, где эти данные зарегистрированы. Более подробно о сервисах каталога больших данных см. документацию Сервис каталога больших данных в Справке ArcGIS Services REST API.
Изменение файлового хранилища больших данных
После создания сервиса каталога больших данных автоматически генерируется манифест для входных данных, который загружается на сайт GeoAnalytics Server, где эти данные зарегистрированы. В процессе генерации манифеста в наборе данных не всегда правильно определяются поля геометрии и времени, может потребоваться корректировка. Для внесения изменений в манифест выполните шаги из раздела Редактирование манифестов файловых хранилищ больших данных в Manager. Дополнительные сведения о манифесте файлового хранилища больших данных см. в разделе Знакомство с манифестом файлового хранилища больших данных в Справке ArcGIS Server.
Изменение выходных шаблонов для файлового хранилища больших данных
Если вы решили использовать файловое хранилище больших данных в качестве расположения выходных данных, автоматически создаются выходные шаблоны. Эти шаблоны описывают форматирование выходных результатов анализа, и задают, например, тип файла, а также способ регистрации времени и геометрии. Если вы хотите изменить геометрию или форматирование времени, добавить или удалить шаблоны, вы можете изменить шаблоны. Для внесения изменений в выходные шаблоны выполните шаги из раздела Редактирование манифестов файловых хранилищ больших данных в Manager. Более подробно о выходных шаблонах см. в разделе Выходные шаблоны в файловых хранилищах больших данных.
Эти шаблоны описывают форматирование выходных результатов анализа, и задают, например, тип файла, а также способ регистрации времени и геометрии. Если вы хотите изменить геометрию или форматирование времени, добавить или удалить шаблоны, вы можете изменить шаблоны. Для внесения изменений в выходные шаблоны выполните шаги из раздела Редактирование манифестов файловых хранилищ больших данных в Manager. Более подробно о выходных шаблонах см. в разделе Выходные шаблоны в файловых хранилищах больших данных.
Выполнение анализа на файловом хранилище больших данных
Выполнение анализа набора данных из файлового хранилища больших данных возможно через любой клиент, который поддерживает GeoAnalytics Server, включая:
- ArcGIS Pro
- Map Viewer
- ArcGIS REST API
- ArcGIS API for Python
Для выполнения анализа на файловом хранилище больших данных с помощью ArcGIS Pro или Map Viewer выберите GeoAnalytics Tools, который вы хотели бы использовать. Перейдите к месту расположения данных, которые будут использоваться в качестве входных для этого инструмента, в разделе Портал в ArcGIS Pro или в диалоговом окне Обзор слоев в Map Viewer. Данные будут в Мои ресурсы, если вы сами регистрировали эти данные. Если не сами, то проверьте Группы или Весь портал. Примите к сведению, что слой файлового хранилища больших данных, который выбран для анализа, не будет отображаться на карте.
Перейдите к месту расположения данных, которые будут использоваться в качестве входных для этого инструмента, в разделе Портал в ArcGIS Pro или в диалоговом окне Обзор слоев в Map Viewer. Данные будут в Мои ресурсы, если вы сами регистрировали эти данные. Если не сами, то проверьте Группы или Весь портал. Примите к сведению, что слой файлового хранилища больших данных, который выбран для анализа, не будет отображаться на карте.
Убедитесь, что вы выполнили вход на портал под учетной записью с доступом к зарегистрированному файловому хранилищу больших данных. Чтобы быстро найти все доступные для вас файловые хранилища больших данных выполните поиск на портале по условию bigDataFileShare*.
Для выполнения анализа на файловом хранилище больших данных посредством ArcGIS REST API используйте в качестве входных данных URL-адрес сервиса каталога больших данных. URL-адрес будет иметь формат {«url»:» https://webadaptorhost.domain.com/webadaptorname/rest/DataStoreCatalogs/bigDataFileShares_filesharename/BigDataCatalogServer/dataset»}. Например, если имя компьютера – example, имя домена – esri, имя Web Adaptor – server, имя файлового хранилища больших данных – MyData, а имя набора данных – Earthquakes, то URL-адрес будет {«url»:» https://example.esri.com/server/rest/DataStoreCatalogs/bigDataFileShares_MyData/BigDataCatalogServer/Earthquakes»}. Более подробно о вводе данных для анализа больших данных посредством REST, см. раздел Ввод объектов в документации ArcGIS Services REST API.
Например, если имя компьютера – example, имя домена – esri, имя Web Adaptor – server, имя файлового хранилища больших данных – MyData, а имя набора данных – Earthquakes, то URL-адрес будет {«url»:» https://example.esri.com/server/rest/DataStoreCatalogs/bigDataFileShares_MyData/BigDataCatalogServer/Earthquakes»}. Более подробно о вводе данных для анализа больших данных посредством REST, см. раздел Ввод объектов в документации ArcGIS Services REST API.
Сохранение результатов в файловое хранилище больших данных
Вы можете запустить анализ для набора данных (из файлового хранилища больших данных или другого источника) и сохранить его результаты в файловое хранилище больших данных. Если вы сохраняете результаты в файловое хранилище больших данных, вы не сможете их визуализировать. Вы можете сделать это, используя следующие клиенты:
- Map Viewer
- ArcGIS REST API
- ArcGIS API for Python
Когда вы записываете результаты в файловое хранилище больших данных, обновляется входной манифест, и в него включается набор данных, который вы только что сохранили. Результаты, записанные в файловое хранилище больших данных, теперь доступны в качестве входных данных для другого инструмента.
Результаты, записанные в файловое хранилище больших данных, теперь доступны в качестве входных данных для другого инструмента.
Отзыв по этому разделу?
обзор для новичков / Блог компании 1cloud.ru / Хабр
Международный рынок гипермасштабируемых дата-центров
растетс ежегодными темпами в 11%. Основные «драйверы» — предприятия, подключенные устройства и пользователи — они обеспечивают постоянное появление новых данных. Вместе с объемом рынка растут и требования к надежности хранения и уровню доступности данных.
Ключевой фактор, влияющий на оба критерия — системы хранения. Их классификация не ограничивается типами оборудования или брендами. В этой статье мы рассмотрим разновидности хранилищ — блочное, файловое и объектное — и определим, для каких целей подходит каждое из них.
/ Flickr / Jason Baker / CC
Типы хранилищ и их различия
Хранение на уровне блоков лежит в основе работы традиционного жесткого диска или магнитной ленты. Файлы разбиваются на «кусочки» одинакового размера, каждый с собственным адресом, но без метаданных. Пример — ситуация, когда драйвер HDD
Файлы разбиваются на «кусочки» одинакового размера, каждый с собственным адресом, но без метаданных. Пример — ситуация, когда драйвер HDD
блоки по адресам на отформатированном диске. Такие СХД используются многими приложениями, например, большинством реляционных СУБД, в списке которых Oracle, DB2 и др. В сетях доступ к блочным хостам
организуетсяза счет SAN с помощью протоколов Fibre Channel, iSCSI или AoE.
Файловая система — это промежуточное звено между блочной системой хранения и вводом-выводом приложений. Наиболее распространенным примером хранилища файлового типа является NAS. Здесь, данные хранятся как файлы и папки, собранные в иерархическую структуру, и доступны через клиентские интерфейсы по имени, названию каталога и др.
/ Wikimedia / Mennis / CC
При этом следует отметить, что разделение «SAN — это только сетевые диски, а NAS — сетевая файловая система» искусственно. Когда появился протокол iSCSI, граница между ними начала размываться. Например, в начале нулевых компания NetApp стала предоставлять iSCSI на своих NAS, а EMC — «ставить» NAS-шлюзы на SAN-массивы. Это делалось для повышения удобства использования систем.
Например, в начале нулевых компания NetApp стала предоставлять iSCSI на своих NAS, а EMC — «ставить» NAS-шлюзы на SAN-массивы. Это делалось для повышения удобства использования систем.
Что касается объектных хранилищ, то они отличаются от файловых и блочных отсутствием файловой системы. Древовидную структуру файлового хранилища здесь заменяет плоское адресное пространство. Никакой иерархии — просто объекты с уникальными идентификаторами, позволяющими пользователю или клиенту извлекать данные.
Марк Горос (Mark Goros), генеральный директор и соучредитель Carnigo, сравнивает такой способ организации со службой парковки, предполагающей выдачу автомобиля. Вы просто оставляете свою машину парковщику, который увозит её на стояночное место. Когда вы приходите забирать транспорт, то просто показываете талон — вам возвращают автомобиль. Вы не знаете, на каком парковочном месте он стоял.
Большинство объектных хранилищ позволяют прикреплять метаданные к объектам и агрегировать их в контейнеры. Таким образом, каждый объект в системе состоит из трех элементов: данных, метаданных и уникального идентификатора — присвоенного адреса. При этом объектное хранилище, в отличие от блочного, не ограничивает метаданные атрибутами файлов — здесь их можно настраивать.
Таким образом, каждый объект в системе состоит из трех элементов: данных, метаданных и уникального идентификатора — присвоенного адреса. При этом объектное хранилище, в отличие от блочного, не ограничивает метаданные атрибутами файлов — здесь их можно настраивать.
/ 1cloud
Применимость систем хранения разных типов
Блочные хранилища
Блочные хранилища обладают набором инструментов, которые
обеспечиваютповышенную производительность: хост-адаптер шины разгружает процессор и освобождает его ресурсы для выполнения других задач. Поэтому блочные системы хранения часто
используютсядля виртуализации. Также хорошо подходят для работы с базами данных.
Недостатками блочного хранилища являются высокая стоимость и сложность в управлении. Еще один минус блочных хранилищ (который относится и к файловым, о которых далее) — ограниченный объем метаданных. Любую дополнительную информацию приходится обрабатывать на уровне приложений и баз данных.
Файловые хранилища
Среди плюсов файловых хранилищ
выделяютпростоту. Файлу присваивается имя, он получает метаданные, а затем «находит» себе место в каталогах и подкаталогах. Файловые хранилища обычно
дешевлепо сравнению с блочными системами, а иерархическая топология удобна при обработке небольших объемов данных. Поэтому с их помощью организуются системы совместного использования файлов и системы локального архивирования.
Пожалуй, основной недостаток файлового хранилища — его «ограниченность». Трудности возникают по мере накопления большого количества данных — находить нужную информацию в куче папок и вложений становится трудно. По этой причине файловые системы не используются в дата-центрах, где важна скорость.
Объектные хранилища
Что касается объектных хранилищ, то они хорошо масштабируются, поэтому
способныработать с петабайтами информации. По статистике, объем неструктурированных данных во всем мире
достигнет 44 зеттабайт к 2020 году — это в 10 раз больше, чем было в 2013. Объектные хранилища, благодаря своей
Объектные хранилища, благодаря своей
работать с растущими объемами данных,
стали стандартомдля большинства из самых популярных сервисов в облаке: от Facebook до DropBox.
Такие хранилища, как Haystack Facebook, ежедневно пополняются 350 млн фотографий и хранят 240 млрд медиафайлов. Общий объем этих данных оценивается в 357 петабайт.
Хранение копий данных — это другая функция, с которой хорошо справляются объектные хранилища. По данным исследований, 70% информации лежит в архиве и редко изменяется. Например, такой информацией могут выступать резервные копии системы, необходимые для аварийного восстановления.
Но недостаточно просто хранить неструктурированные данные, иногда их нужно интерпретировать и организовывать. Файловые системы имеют ограничения в этом плане: управление метаданными, иерархией, резервным копированием — все это становится препятствием. Объектные хранилища оснащены внутренними механизмами для проверки корректности файлов и другими функциями, обеспечивающими доступность данных.
Плоское адресное пространство также выступает преимуществом объектных хранилищ — данные, расположенные на локальном или облачном сервере, извлекаются одинаково просто. Поэтому такие хранилища часто применяются для работы с Big Data и медиа. Например, их используют Netflix и Spotify. Кстати, возможности объектного хранилища сейчас доступны и в сервисе 1cloud.
Благодаря встроенным инструментам защиты данных с помощью объектного хранилища можно создать надежный географически распределенный резервный центр. Его API основан на HTTP, поэтому к нему можно получить доступ, например, через браузер или cURL. Чтобы отправить файл в хранилище объектов из браузера, можно прописать следующее:
<form action = "[url_storage/account/container/object]"
method = "post"
enctype = "multipart/form-data">
<input type="hidden" name="redirect" value="[url_result]">
<input type="hidden" name="signature" value="[hmac]">
<input type="file" name="file_name">
<input type="submit">
</form>
После отправки к файлу добавляются необходимые метаданные. Для этого есть такой запрос:
Для этого есть такой запрос:
curl -i [url_storage/account/container/object] -X POST
-H "X-Auth-Token: [token]" -H "X-Object-Meta-ValueA: [value-a]"
Богатая метаинформация объектов позволит оптимизировать процесс хранения и минимизировать затраты на него. Эти достоинства — масштабируемость, расширяемость метаданных, высокая скорость доступа к информации — делают объектные системы хранения оптимальным выбором для облачных приложений.
Однако важно помнить, что для некоторых операций, например, работы с транзакционными рабочими нагрузками, эффективность решения уступает блочным хранилищам. А его интеграция может потребовать изменения логики приложения и рабочих процессов.
P.S. Еще несколько материалов о хранении данных из блога 1cloud:
20 лучших облачных хранилищ данных
Облачные файловые хранилища бывают различных видов. Напрямую сравнить различных провайдеров затруднительно, потому что они ориентированы на предоставление различных услуг:
Большинство сервисов предоставляет определенный объем дискового пространства бесплатно, но, если вы собираетесь хранить резервные копии медиа файлов, вы быстро исчерпаете этот лимит. Помимо этого нужно выяснить, какие операционные системы поддерживаются, можно ли выполнять резервное копирование и использовать файлы с нескольких устройств.
Помимо этого нужно выяснить, какие операционные системы поддерживаются, можно ли выполнять резервное копирование и использовать файлы с нескольких устройств.
Безопасность облачного хранилища данных также является важным фактором. Все сервисы утверждают, что разработали оптимальную политику безопасности, но лишь немногие из них дают пользователям реальный контроль над данными. Обращайте внимание на сервисы, которые следуют политике «нулевой осведомленности«. Это означает, что они не могут просматривать или передавать ваши файлы, даже если бы захотели. Но будьте готовы к тому, что вы будете нести большую ответственность за сохранность своих данных.
Вот краткое описание 20 ведущих облачных файловых хранилищ и их преимущества по сравнению с другими сервисами:
Тарифные планы SugarSync начинаются с $ 9,99 в месяц за 100 Гб или $ 74,99 в год. За эти деньги вы получите возможность выполнять резервное копирование с неограниченного количества устройств на Mac или Windows. Существует 30-дневная бесплатная ознакомительная версия.
Вы можете добавить или изменить файл на одном устройстве, и он будет мгновенно доступен на другом. Также можно создать резервную копию существующей структуры папок, что значительно упрощает работу.
С помощью всего лишь нескольких кликов вы можете обеспечить сохранение папки в режиме реального времени, и получить к ней доступ с любого устройства. Это простое, но мощное облако файловое хранилище, которое отличается разумным соотношением цены и качества:
Предлагая пользователям тарифные планы от $ 4,92 в месяц или $ 59,99 в год, Carbonite является одним из наиболее конкурентоспособных облачных сервисов с точки зрения цены. Он ориентирован на частных пользователей и малый бизнес. Тарифный план ‘Pro‘ дает возможность осуществлять резервное копирование с неограниченного количества рабочих станций по цене $ 269,99 в год.
Сервис также предлагает поддержку 7 дней в неделю, с 8:30 до 21:00. Предоставляется 15-дневная бесплатная ознакомительная версия. Пакет аварийного восстановления от Carbonite — еще одно решение, которое включает в себя опции восстановления данных на сайте и облачного резервного копирования, с 500 гигабайтами облачного пространства и 1 терабайтом на локальном диске. Этот тарифный план стоит $ 1,199.99 в год:
Этот тарифный план стоит $ 1,199.99 в год:
IDrive бесплатно предоставляет в распоряжение пользователей 5 Гб дискового пространства и возможность использовать его с неограниченного количества устройств. Существуют платные тарифные планы, цены на которые начинаются с $ 4,95 в месяц за 150 Гб, или $ 49,50 в год. Сервис работает только с Windows и Mac.
Это бесплатное файловое хранилище предлагает решение в виде «единого окна», которое позволяет создавать резервные копии PC, Mac, и даже картинок Facebook. Бизнес-пользователи могут создавать резервную копию компьютеров, серверов, Exchange, SQL, NAS и мобильных устройств.
Помимо 256-битного AES шифрования сервис предоставляет возможность использования личного ключа, известного только вам. Кроме этого поддерживается сохранение различных версий файлов (до 10).
У IDrive также есть интересный способ работы с клиентами: они присылают пользователю физический диск, на который он копирует свои данные и отправляет его им обратно. Таким образом, не нужно беспокоиться о превышении недельного лимита.
Таким образом, не нужно беспокоиться о превышении недельного лимита.
Для многих Dropbox был первым и остался единственным облачным хранилищем. Это популярный сервис для личного пользования благодаря его простому интерфейсу и конкурентоспособным ценам. За $ 9,99 в месяц или $ 99,99 в год вы получаете 1000 Гб дискового пространства, 2 Гб можно использовать бесплатно. Dropbox доступен для пользователей Windows, Mac и Linux.
Это файловое хранилище синхронизирует файлы в автоматическом режиме и позволяет обмениваться ими с семьей и друзьями, даже если у них нет учетной записи в сервисе. Сохраненные файлы доступны с любого устройства. Можно совместно использовать папки для общей работы с документами, хотя Dropbox больше ориентирован на частных лиц, а не на компании.
Google предлагает пользователям надежное и недорогое решение для хранения данных. Вы получаете бесплатно 15 Гб, а если нужно больше, то 100 Гб обойдутся в $ 1,99 в месяц, или $ 23,88 в год. Google Drive можно использовать на неограниченном количестве устройств. Сервис не поддерживает Linux, а только Windows и Mac.
Сервис не поддерживает Linux, а только Windows и Mac.
Подвох заключается в конфиденциальности. Многие компании переходят на модель работы, при которой они берут за свои услуги символическую плату, но монетизируют привлеченных клиентов, используя их данные для различных целей, в том числе для рекламы. К сожалению, это не очень хорошо с точки зрения безопасности хранимой информации:
Облако файловое хранилище всего за $ 5 в месяц или $ 50 в год. За эти деньги вы получите возможность неограниченного копирования. Также предоставляется возможность в течение 15 дней бесплатно пользоваться сервисом в ознакомительном режиме.
Backblaze отличается от большинства облачных сервисов. Пользователь скачивает программное обеспечение и устанавливает его, после чего резервное копирование происходит автоматически. Не нужно выбирать файлы и папки. Все делается автоматически. Backblaze сканирует компьютер и находит фотографии, музыку, документы и другие важные файлы. Когда вы не работаете на компьютере, Backblaze копирует, сжимает и шифрует данные, после чего отправляет их в безопасный центр обработки данных для дальнейшего хранения.
Что особенно приятно — это отсутствие каких-либо ограничений. Можно выполнять резервное копирование данных в облако с внешнего жесткого диска без дополнительных затрат. Также нет ограничений на размер файла.
Backblaze работает в фоновом режиме на Windows или Mac. Сервис не только безопасен, благодаря надежному шифрованию, но и прост в использовании:
Предоставляет сервис файлового хранилища за $ 5,99 в месяц или $ 59,99 в год, доступна 30-дневная бесплатная версия. Сервис работает под Windows, Mac или Linux. После того, как вы задали основные настройки, CrashPlan работает в фоновом режиме, автоматически копируя ваши файлы в облако.
Можно выбрать бесплатный вариант резервного копирования на внешнем жестком диске, так что все файлы будут храниться локально. По понятным причинам этот вариант имеет ряд ограничений.
Также существует возможность создавать резервные копии на других доверенных компьютерах в Сети (например, родственников и друзей). И, наконец, есть вариант облачного хранилища, который является наиболее безопасным: вы получаете возможность безлимитного резервного копирования, без ограничений по объему, использованию канала или типу файлов. CrashPlan использует оборудование корпоративного уровня и шифрование по военным стандартам. Доступ к файлам можно получить с любого устройства по своему выбору.
CrashPlan использует оборудование корпоративного уровня и шифрование по военным стандартам. Доступ к файлам можно получить с любого устройства по своему выбору.
Mozy предлагает стартовый бесплатный тарифный план — 2 Гб дискового пространства. Стоимость платных начинается с $ 5,99 в месяц или $ 65,89 в год за 50 Гб.
Сервисом пользуются более 6 миллионов человек и 100 000 компаний по всему миру, которые доверяют ему более 90 петабайт своих данных. Опция «установил и забыл» позволяет запланировать резервное копирование на определенное время. Все остальное будет выполнено автоматически.
Это бесплатное файловое хранилище обеспечивает двойное шифрование: 256-битное AES или 448-битный управляемый ключ Blowfish, а также передачу данных через зашифрованное SSL-подключение.
Мониторинг дата-центров осуществляется в режиме 24/7: контроль температуры, резервное питание, анализ сейсмической активности и другие меры безопасности. Данный сервис имеет несколько дата-центров в странах ЕС, так что европейские данные могут сохраняться в Европе:
JustCloud предлагает неограниченное пространство для хранения данных по цене от $ 4,49 в месяц или $ 53,88 в год. Также доступна 14-дневная бесплатная ознакомительная версия. JustCloud обеспечивает быстрый и безопасный сервис, с синхронизацией между несколькими компьютерами и устройствами.
Также доступна 14-дневная бесплатная ознакомительная версия. JustCloud обеспечивает быстрый и безопасный сервис, с синхронизацией между несколькими компьютерами и устройствами.
Есть бесплатные мобильные приложения. С их помощью можно легко обмениваться файлами с друзьями. Это простой и автоматизированный сервис, который стремится внедрять новейшие технологии, с большим спектром поддерживаемых устройств и операционных систем.
Также сервис обеспечивает создание неограниченного количества версий копий файлов. Все файлы кодируются с помощью многоуровневого шифрования и хранятся в защищенных центрах обработки данных.
Цены на услуги файлового хранилища данных Mega начинаются с 9,99 EUR в месяц за 500 Гб, или 99,99 EUR в год. Также можно бесплатно получить 50 Гб. Сервис работает с Windows, Mac и Linux.
Mega вышел на рынок в 2013 году, но уже успел заслужить хорошую репутацию. Сервис исповедует строгий подход к безопасности. Мощная система полного шифрования защищает пользовательские данные даже от самого Mega. Но это не влияет на удобство и простоту его использования.
Но это не влияет на удобство и простоту его использования.
Несмотря на то, что Mega остается единственным провайдером облачного хранилища данных с высокопроизводительным полным шифрованием на базе браузера, он довольно прост, и это привлекает миллионы пользователей.
Еще одно недорогое облачное хранилище, предоставляющее услуги всего от 5 долларов в месяц за неограниченное дисковое пространство, или $ 59,99 в год. Также доступна 14-дневная бесплатная ознакомительная версия, сервис работает с Windows и Mac.
У вас есть возможность хранить в облаке неограниченный объем данных в течение долгого времени. End-to-end шифрование всегда включено, поэтому файлы всегда будут зашифрованы, прежде чем успеют покинуть ваш компьютер.
Также доступно мощное Android-приложение, с помощью которого можно сохранить все данные на мобильных устройствах. Вы можете восстановить потерянные файлы с любого устройства.
Облако файловое хранилище SOS предполагает создание пользователем ключей, которые никогда не хранятся в облаке. Таким образом, только владелец может получить доступ к файлам. Данные хранятся на защищенных серверах с постоянным мониторингом, каждую ночь осуществляется резервное копирование данных на различные устройства.
Таким образом, только владелец может получить доступ к файлам. Данные хранятся на защищенных серверах с постоянным мониторингом, каждую ночь осуществляется резервное копирование данных на различные устройства.
Цены начинаются с $ 7 в месяц за 30 Гб, или $ 84 в год. Вы можете использовать сервис на неограниченном количестве устройств. Он работает с Windows, Mac и Linux. Максимальный объем доступного хранилища составляет 5 Тб, при этом 1 Тб обойдется всего в $ 12 в месяц. Кроме внушительного объема дискового пространства пользователь получает полный контроль над своими данными. Вся информация хранится на серверах в зашифрованном виде.
Несмотря на ощутимый уклон в сторону шифрования, это относительно гибкое решение, предлагающее различные индивидуальные услуги для отдельных пользователей и корпоративных клиентов.
Подход других сервисов, которые используют только локальное шифрование, делает ваши данные уязвимыми. Если вам не нужен такой сервис, то SpiderOak это хороший вариант.
Norton — это известное имя в сфере онлайн-безопасности, теперь компания расширяют свою деятельность и на сегмент файловых хранилищ.
На сервисе нет стартового бесплатного плана и бесплатной ознакомительной версии. Но за $ 4,17 в месяц ($ 49,99 в год) вы получите 25 Гб дискового пространства и сможете использовать его с 5 компьютеров, работающих на базе операционных систем Windows или Mac.
Norton предлагает надежное шифрование. Резервные копии важных файлов создаются автоматически. Также можно увеличить объем хранилища, если вам потребуется больше места.
Можно передавать файлы между компьютерами и извлекать данные из резервных копий с любого ПК через защищенные паролем веб-страницы. Предыдущие резервные копии хранятся в течение 90 дней. С целью экономии пространства при создании резервной копии файлы автоматически сжимаются.
SafeCopy предлагает много места в облаке по разумной цене. До 3 ГБ пользователь получает бесплатно, за $ 4,17 в месяц ($ 50 в год) доступно 200 Гб.
Предлагается 30-дневная бесплатная ознакомительная версия. Вы можете использовать сервис на неограниченном количестве устройств, работающих на базе операционных систем Windows и Mac. Файлы защищены с помощью 448-разрядного шифрования военного уровня. Большая часть вычислений осуществляется за счет собственных серверов SafeCopy, поэтому нагрузка на процессор пользовательского компьютера будет невысокой.
Существует возможность хранить неограниченное количество версий, можно создавать резервные копии нескольких папок. При удалении файла на компьютере он остается в файловом хранилище без регистрации. Так что это отличный способ застраховаться от ошибок.
LiveDrive предоставляет неограниченный объем облачного хранилища за $ 8 в месяц или $ 48 в год. Предлагается 14-дневная бесплатная ознакомительная версия, но она не включает в себя бесплатное хранилище. Сервис работает под Windows и Mac.
LiveDrive является одним из наиболее динамично развивающихся сервисов облачных хранилищ данных. Предлагаемый программный пакет легко устанавливается, и с помощью специального приложения позволяет видеть свои файлы с любого устройства на IOS, Android или Windows 8.
Предлагаемый программный пакет легко устанавливается, и с помощью специального приложения позволяет видеть свои файлы с любого устройства на IOS, Android или Windows 8.
Можно синхронизировать файлы на разных компьютерах и работать на различных устройствах. Общий доступ к документам осуществляется через интернет. Тарифный план включает в себя 2 Тб доступного пространства. Версия «Про» предоставляет дополнительный функционал и 5 Тб пространства.
pCloud предоставляет 10 Гб бесплатного хранилища, которое будет доступно пользователю с неограниченного количества устройств. Сервис поддерживает работу с Windows, Mac и Linux. Если нужно больше места, это обойдется всего в $ 4,99 в месяц или $ 49,99 в год за 100 Гб. Также можно получить 10 дополнительных гигабайт за привлеченных друзей. Для бизнес-пользователей существует 5-терабайтный тарифный план с инструментами корпоративного уровня для совместной работы и управления пользователями.
Облако файловое хранилище pCloud позволяет получить доступ к файлам с компьютера, со смартфона или другого мобильного устройства. Существует возможность повысить безопасность через шифрование конфиденциальных файлов с помощью pCloud Crypto. Это обойдется в $ 3,99 за месяц. Шифрование выполняется на стороне клиента, даже pCloud не имеет доступа к файлам.
Существует возможность повысить безопасность через шифрование конфиденциальных файлов с помощью pCloud Crypto. Это обойдется в $ 3,99 за месяц. Шифрование выполняется на стороне клиента, даже pCloud не имеет доступа к файлам.
OpenDrive предлагает неограниченное облачное хранилище, доступное с любого количества устройств, за $ 9,95 в месяц или $ 99 в год. Поддерживаемые системы — Windows и Mac. 5Гб дискового пространства вы получаете бесплатно.
Наряду со стационарной версией существует приложение для Android, которое можно использовать для быстрого и простого резервного копирования.
Сервис предлагает круглосуточную поддержку для бизнес-пользователей, а также множество инструментов для обмена файлами с другими людьми. Можно управлять свободным пространством и каналом, а также количеством подключенных пользователей. Вы также можете делиться с друзьями файлами и папками любого размера и воспроизводить медиа-файлы прямо из облака.
Также поддерживается функция «горячих ссылок», которая позволяет вставлять ссылки на файлы в облаке в электронные письма и документы. Также можно добавлять пользователей к общим папкам.
Также можно добавлять пользователей к общим папкам.
Файловое хранилище Altdrive не имеет стартового бесплатного тарифного плана, и сервисом можно пользоваться только с одного устройства. Также доступна 30-дневная ознакомительная версия, она работает на Mac, Windows и Linux, Solaris. Неограниченное пространство для хранения данных можно купить за $ 4,45 в месяц или $ 44,50 в год.
Altdrive поддерживает работу с файлами до 4 Гб. Сервис делает сильный акцент на безопасности. Это является одной из причин, почему он не предлагает синхронизацию или совместное использование.
Кроме этого сервис ориентирован на технически подкованных пользователей. Он предлагает услуги, которых нет у других сервисов. Например, геолокация украденных устройств. Также поддерживается управление версиями файлов, что позволяет создать резервную копию по требованию или по графику.
Zoolz являются более дорогим решением, чем большинство других сервисов на рынке. Он не предоставляет бесплатного начального плана, вы можете использовать только одно устройство, и поддерживает только Windows. Использование данного сервиса обойдется в $ 14,17 в месяц или $ 169,99 в год за неограниченное пространство.
Использование данного сервиса обойдется в $ 14,17 в месяц или $ 169,99 в год за неограниченное пространство.
Это облако файловое хранилище специализируются на длительном хранении. Его создатели заявляют, что будут хранить ваши данные в облаке всю жизнь и что другие компании не предлагают такого длительного периода.
Перед тем, как файлы сохраняются на серверах, они шифруются с помощью 256-битного AES шифрования военного класса. Также поддерживается множество дополнительных функций, таких как планирование и настройка лимита скорости загрузки. Существует вариант гибридного копирования, если пользователю необходима вторая резервная копия на локальном сервере.
Хотя, если потребуется, можно восстанавливать из резервных копий отдельные файлы или все сразу. Процесс запускается с задержкой в 3-5 часов.
ADrive является гибким сервисом, поддерживающим Windows, Mac и Linux. Можно использовать неограниченное количество устройств, доступен бесплатный тарифный план на 50 Гб. Платные тарифные планы начинаются с $ 6,95 в месяц или $ 69,95 в год.
Можно получить доступ к файлам из любой точки мира, а также обмениваться ими или редактировать их через интернет. Сервис предлагает удобные инструменты для поиска файлов. Премиум и бизнес-планы поддерживают совместное использование данных, восстановление различных версий сохраненных файлов, ограничение периода доступности публичных файлов и SSL-шифрование. А также «Отсутствие рекламы третьих сторон«. Это предполагает, что базовый пакет будет содержать рекламу.
Можно получить доступ к файлам через интернет из любого места. Бесплатное файловое хранилище также предлагает специальные приложения для загрузки с Android и iOS.
Пожалуйста, оставьте ваши мнения по текущей теме статьи. За комментарии, отклики, лайки, подписки, дизлайки огромное вам спасибо!
Что такое объектное хранилище? — Российская Федерация
По мере того как сотрудники создают все больше материалов, ИТ-отделы предприятий отмечают экспоненциальный рост требований к хранилищам данных. Создание мультимедийных ресурсов — ключевой фактор.
Спрос на объектные системы хранения будет расти из-за необходимости архивировать больше неструктурированных данных. Этот рост будет стимулировать развертывание новых, экономически эффективных решений распределенных систем хранения, которые могут масштабироваться до сотен петабайтов.
Требования рынка
Десять лет назад мы ожидали, что объем данных в мире превысит уровень петабайта для большинства организаций, а для некоторых из них достигнет даже эксабайта. Сегодня мы живем в мире, где облачные технологии привели к наступлению эпохи революционного новаторства, а Интернет вещей (IoT) позволил миллионам устройств создавать, собирать и отправлять данные каждую секунду. Этот прогноз стал реальностью.
Для управления беспрецедентным объемом создаваемых данных предприятиям необходимо определить, каким образом можно эффективно защищать, хранить, анализировать и максимально повышать ценность своих неструктурированных данных. Предназначение объектного хранилища — делать это в масштабе Интернета.
Интернет спроектирован таким образом, чтобы технология распространения информации была полностью децентрализованной. Каждый объект в системе объектного хранилища уникален. Объекты идентифицируются по ИД, который однозначно определяет способ поиска объектов.
В данной системе хранения существует несколько физических узлов, работающих независимо друг от друга. В любой момент в систему можно добавить дополнительные узлы. Эта структура позволяет предприятиям масштабировать вместимость и производительность независимо друг от друга.
В этом процессе данные, записываемые в систему объектного хранилища приложением, передаются через уровень доступа, на котором они шифруются, разделяются на части и распределяются.
Уникальный ИД объекта используется для получения объекта через уровень доступа путем нахождения порогового номера хранимых частей и воссоздания объекта.
Технология хранения
Благодаря ссылкам на объекты по ИД, а не по именам файлов, систему можно масштабировать. Этот подход не имеет ограничений по размеру, а получать данные проще, поскольку в объект можно добавить большое количество метаданных.
Этот подход не имеет ограничений по размеру, а получать данные проще, поскольку в объект можно добавить большое количество метаданных.
Система объектного хранилища гарантирует, что ИТ могут пользоваться текущими инвестициями. Кроме того, она позволяет организации не упустить будущие возможности независимо от того, хранятся ли данные локально, в облаке или и там и там.
Обзор рынка
По мере того как организации пересматривают свои стратегии хранения данных, чтобы справиться с ростом скорости создания и потребления данных, объектное хранилище предоставляет предприятиям защищенное, адаптивное и экономное решение для управления данными.
Чем больше пул данных, тем выше стоимость долговременного владения. Информация доступна постоянно, а упрощенная платформа управления ускоряет обслуживание и дополнительные операции.
Облачные технологии, IoT и мобильные устройства являются движущей силой наполненного данными мира, и многие организации поймут, что инвестиции в завтрашний день начинаются сегодня. Объектное хранилище позволяет организациям, которым требуется работать с данными в масштабах Интернета, реализовать масштабируемое дальновидное решение для хранения данных, которое даст предприятиям возможность развиваться в течение следующих 20 лет и более.
Объектное хранилище позволяет организациям, которым требуется работать с данными в масштабах Интернета, реализовать масштабируемое дальновидное решение для хранения данных, которое даст предприятиям возможность развиваться в течение следующих 20 лет и более.
Как современным ИТ-сервисам эффективнее хранить данные
Объектные хранилища созданы для встраивания в приложения, поэтому их основной интерфейс — программный (API), то есть, команды, которые хранилище и приложения передают друг другу. Один из распространённых API — S3 (Simple Storage Service), а поддерживающие его объектные хранилища, называют S3-хранилищами. У объектных хранилищ бывает и «человеческий» интерфейс (UI), через который можно, к примеру, загрузить объект и настроить доступ к нему.
Примеры использования объектного хранилища:
- Хранение архива документов: файлов, писем, архивных данных, нормативной документации. Здесь можно особо выделить хранение «тяжёлых» файлов, которые накапливаются, но для которых не хочется покупать всё больше железа: исходники медиа-файлов, полные последовательности ДНК.
- Хранение неструктурированных данных, которые не имеют фиксированного формата и состоят из объектов разного размера, типа и структуры. В объектном хранилище часто накапливают big data, к которым затем применяют машинный анализ и строят прогнозы для принятия бизнес-решений.
- Раздача контента: для видеохостингов, фотобанков, галерей, кода игр и даже статических (то есть не меняющихся) страниц веб-сайтов. Важна возможность не только разместить практически неограниченное число объектов, но и организовать доступ к ним любого количества пользователей.
- Хранение резервных копий (бэкапов) данных. Объектное хранилище можно интегрировать с системами, которые делают бэкапы любых папок, дисков, баз данных и целых инфраструктур и организовать автоматическое бэкапирование с сохранением версий.
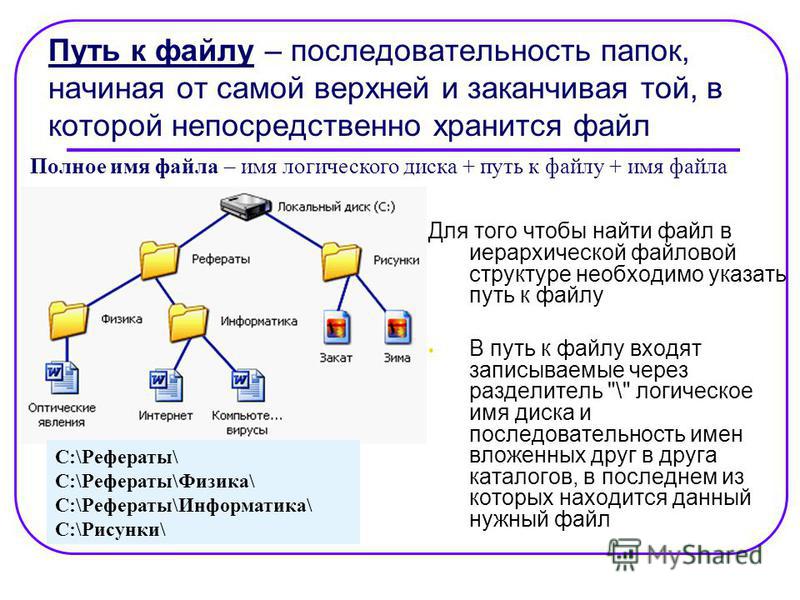
Иногда объектные хранилища все же используют в роли файловых систем, когда работать нужно с файлами в иерархии каталогов, но хочется сохранить преимущества объектного хранилища по надежности и масштабируемости. В этом случае можно использовать дополнительные утилиты, например Диск-О, чтобы создать дерево каталогов и имитировать работу с объектами хранилища как с файлами. Использовать эти утилиты несложно, поэтому в некоторых случаях объектным хранилищем вполне можно заменить файловое.
В этом случае можно использовать дополнительные утилиты, например Диск-О, чтобы создать дерево каталогов и имитировать работу с объектами хранилища как с файлами. Использовать эти утилиты несложно, поэтому в некоторых случаях объектным хранилищем вполне можно заменить файловое.
для чего они нужны и какие типы существуют – База знаний Timeweb Community
Отличительной чертой нашего времени является постоянный рост объема деловой информации. Дизайнеры, маркетологи, копирайтеры, представители IT-профессий, а также компании, работающие с огромными массивами данных, постоянно нуждаются в надежном месте, в котором можно было бы хранить ценные файлы. Если раньше их держали на дискетах, флешках и компакт-дисках, то сейчас лучше всего отправлять их в облачные хранилища.
Облачное хранилище: что это такое?
В общем и целом, это специально выделенное место на серверах, куда любой пользователь может закачать различные документы: текстовые файлы, любимые аудиозаписи и видеоролики, картинки, гифки, переписку из мессенджеров и многое другое. При этом серверы могут находиться где угодно: в Европе, Азии или Северной Америке.
Механизм облачного хранилища очень прост: нужно установить клиентское приложение и зарегистрироваться в нем. После чего можете спокойно сбрасывать в «облако» любую информацию, обмениваться ей с коллегами, обновлять ее, просматривать и так далее. Доступ к нему можно получить с любого устройства и из любого места, в котором есть Интернет.
Поскольку данные бывают разные, то и хранить их лучше в подходящих для этого местах. По типу организации облачные хранилища делятся на:
- файловые,
- блочные,
- объектные,
- базы данных.
Поговорим о каждом типе подробнее.
В основе файловой системы лежит иерархическая структура: корневая запись, от которой отходят данные о файлах и их атрибутах. Все они, в свою очередь, организованы в удобную структуру каталогов – зная имя того или иного документа, доступ к нему можно получить, щелкнув мышью по его имени. С ними можно осуществлять любые операции – открывать, изменять, переименовывать, удалять, копировать, перемещать в другую папку.
Файловое хранилище может быть двух видов: физическим и виртуальным. В первом случае данные сохраняются на жестком диске, во втором – на виртуальном. Последний имеет намного больший объем чем жесткий, а еще туда можно настроить удаленный доступ. В качестве примера можно привести Dropbox, «Облако Mail.Ru», «Google Диск», «Яндекс. Диск» и другие аналогичные им сервисы.
Преимущества:
- Простая и понятная структура.
- В таком хранилище легко ориентироваться, искать нужные документы.
Недостатки:
- Ограниченность в объеме, по мере заполнения которого падает скорость доступа, а вместе с ней и производительность.
Для чего подходит: для работы с небольшими объемами разны данных.
Блочное хранилищеВ блочном хранилище структура размещения та же, но все попадающие туда файлы делятся системой на блоки, каждому из которых присваивается свой идентификатор. С его помощью система собирает файлы в случае надобности.
Преимущества:
- Каждая пользовательская среда находится отдельно, за счет чего можно рассортировывать данные и обеспечить отдельный доступ к ним.
- БХ обеспечивает повышенную производительность: благодаря хост-адаптеру шины, который разгружает процессор и освобождает его ресурсы для выполнения других задач.
Недостатки:
- Оно дороже, и им трудно управлять, поскольку работа с блоками создает дополнительную нагрузку на базу данных.
- Оно, как и файловое, ограничено в объеме.
Для чего подходит: для работы с корпоративными базами данных
Объектное хранилищеЭто самый популярный тип хранилища. Вместо файловой системы в нем есть плоское пространство, состоящее из множества объектов, каждый из которых состоит из идентификатора и метаданных. Идентификатор – это присвоенный адрес, в роли которого выступает 128-битное число. Зная его можно без труда найти нужный файл. Метаданные (информация о файле) – его имя, размер, координаты и другая информация.
Объектные хранилища бывают частными или публичными. В первом случае оно создается в частном облаке, во втором – облако берут в аренду у провайдера публичных облаков.
Достоинства:
- Возможность работы с колоссальным объемом информации. Общий объем данных, хранящихся в Haystack Facebook, оценивается в 357 петабайт.
- Возможность хранения резервных копий данных, особенно тех, от которых зависит жизнедеятельность системы (например, файлы для аварийного восстановления).
- Возможность проверки корректности файлов и обеспечения быстрого доступа к ним.
Недостатки:
- Сложно называть объекты.
- Во многих объектных хранилищах отсутствует интерфейс для загрузки и управления файлами.
Для чего подходит: для хранения больших данных, текстовых документов, изображений, медиафайлов, переписок и многого другого.
База данныхБаза данных – это совокупность определенной информации, хранящаяся в строго установленном порядке на физических или виртуальных носителях. Она управляется специальной программой под названием СУБД (Система Управления Базами Данных). СУБД позволяет обрабатывать любые тексты, графику, медиа; с ними можно делать все что угодно: хранить, анализировать, тестировать продукты и обновления, запускать новые проекты.
Она очень хорошо подходят для постоянных типовых операций. Например, туда записывается информация о заказах, поступающих в интернет-магазин, на основе которой приложение автоматически выписывает счет на оплату. Примером такой базы может стать нереляционная высокопроизводительная СУБД Redis, она хранит данные в оперативной памяти.
Базы данных могут находиться либо на сервере, либо в облаке. Облачные СУБД сегодня являются самыми популярными в своей области. Согласно исследованиям Market Realist, их используют 35% респондентов, экспериментируют с ними 14%, планируют внедрение – 12%.
Преимущества:
- Облачные базы данных имеют практически неограниченный объем хранения.
- Есть функция резервного копирования.
- Они обладают высоким внешним и внутренним уровнем безопасности, который обеспечивается техническими средствами и экспертами.
- Поддержка многозадачного и многопользовательского режимов.
Недостатки:
- Сложность управления, что требует затрат на соответствующий персонал и ПО.
- В случае нахождения их на физическом носителе имеют ограниченный объем, так что может потребоваться увеличение дискового пространства.
- Высокая стоимость разработки и эксплуатации.
Для чего подходят: для управления однородными массивами данных.
Чего ждать в будущемВ перспективе нас ждет появление еще одного типа хранилищ – вычислительного, вся работа которого основана на обработке данных в процессе перемещения в слой хранения, что позволяет не отвлекать на выполнение операций ресурсы центрального процессора. По своей доступности, экономичности и надежности облачное хранилище пока остается основным местом для безопасного хранения данных.
Что такое файловое хранилище | IBM
Что такое файловое хранилище и когда оно наиболее полезно? В этом руководстве будет дано определение хранилища файлов, объяснены его преимущества и рассмотрены некоторые типичные варианты использования.
Что такое файловое хранилище?
Файловое хранилище — также называемое файловым хранилищем или хранилищем на основе файлов — это методология иерархического хранилища, используемая для организации и хранения данных на жестком диске компьютера или на устройстве сетевого хранения (NAS). В файловом хранилище данные хранятся в файлах, файлы организованы в папки, а папки организованы в виде иерархии каталогов и подкаталогов.Чтобы найти файл, вам или вашей компьютерной системе нужен только путь — от каталога к подкаталогу, от папки к файлу.
Иерархическое хранилище файлов хорошо работает с легко организованными объемами структурированных данных. Но по мере роста количества файлов процесс их извлечения может стать громоздким и трудоемким. Масштабирование требует добавления дополнительных аппаратных устройств или постоянной замены их устройствами большей емкости, что может стать дорогостоящим.
В некоторой степени вы можете смягчить эти проблемы масштабирования и производительности с помощью облачных сервисов хранения файлов.Эти службы позволяют нескольким пользователям получать доступ и совместно использовать одни и те же файловые данные, расположенные в удаленных центрах обработки данных (в облаке). Вы просто платите ежемесячную абонентскую плату за хранение файловых данных в облаке, и вы можете легко масштабировать емкость и указать критерии производительности и защиты данных. Более того, вы избавляетесь от расходов на обслуживание собственного оборудования на месте, поскольку эта инфраструктура управляется и поддерживается поставщиком облачных услуг (CSP) в его центре обработки данных. Это также известно как «инфраструктура как услуга» (IaaS).
Хранилище файлов, хранилище блоков и хранилище объектов
Файловое хранилище было популярным методом хранения на протяжении десятилетий — оно знакомо практически каждому пользователю компьютера и хорошо подходит для хранения и организации транзакционных данных или управляемых томов структурированных данных, которые можно аккуратно хранить в базе данных на жестком диске в сервер.
Однако многие организации сейчас изо всех сил пытаются управлять растущими объемами цифрового веб-контента или неструктурированных данных.Если вам нужно хранить очень большие или неструктурированные тома данных, вам следует рассмотреть возможность блочного или объектного хранилища, которое организует данные и обращается к ним по-разному. В зависимости от различных требований к скорости и производительности ваших ИТ-операций и различных приложений вам может потребоваться комбинация этих подходов.
Блочное хранилище
Блочное хранилище обеспечивает более высокую эффективность хранения (более эффективное использование доступного оборудования для хранения данных) и более высокую производительность, чем файловое хранилище.Блочное хранилище разбивает файл на порции (или блоки) одинакового размера и сохраняет каждый блок отдельно под уникальным адресом.
Вместо того, чтобы соответствовать жесткой структуре каталогов / подкаталогов / папок, блоки могут храниться в любом месте системы. Для доступа к любому файлу операционная система сервера использует уникальный адрес для объединения блоков в файл, что занимает меньше времени, чем переход по каталогам и файловым иерархиям для доступа к файлу. Блочное хранилище хорошо подходит для критически важных бизнес-приложений, транзакционных баз данных и виртуальных машин, которым требуется низкая задержка (минимальная задержка).Это также дает вам более детальный доступ к данным и стабильную производительность.
В следующем видео Эми Бли разбирает различия между хранилищем блоков и хранилищем файлов:
Блочное хранилище и файловое хранилище (04:03)
Хранилище объектов
Объектно-ориентированное хранилище стало предпочтительным методом для архивирования данных и резервного копирования сегодняшних цифровых коммуникаций — неструктурированных медиа и веб-контента, такого как электронная почта, видео, файлы изображений, веб-страницы и данные датчиков, производимые Интернетом вещей (IoT). .Он также идеально подходит для архивирования данных, которые не часто меняются (статические файлы), например больших объемов фармацевтических данных или музыкальных, графических и видеофайлов.
Объекты — это дискретные единицы данных, которые хранятся в структурно плоской среде данных. Опять же, здесь нет папок, каталогов или сложных иерархий; вместо этого каждый объект представляет собой простой автономный репозиторий, который включает данные, метаданные (описательную информацию, связанную с объектом) и уникальный идентификационный номер ID.Эта информация позволяет приложению находить объект и получать к нему доступ.
Вы можете объединить устройства хранения объектов в более крупные пулы хранения и распределить эти пулы хранения по расположениям. Это обеспечивает неограниченное масштабирование, повышенную отказоустойчивость данных и аварийное восстановление. Объекты могут храниться локально, но чаще всего они находятся на облачных серверах и доступны из любой точки мира.
IBM Cloud Object Storage: Создано для бизнеса (04:10)
Преимущества
Если вашей организации требуется централизованный, легко доступный и недорогой способ хранения файлов и папок, хранение на уровне файлов — хороший подход.К преимуществам файлового хранилища можно отнести следующие:
- Простота : Хранение файлов — это самый простой, наиболее привычный и понятный подход к организации файлов и папок на жестком диске компьютера или NAS-устройства. Вы просто называете файлы, помечаете их метаданными и сохраняете их в папках в иерархии каталогов и подкаталогов. Нет необходимости писать приложения или код для доступа к вашим данным.
- Общий доступ к файлам : Хранилище файлов идеально подходит для централизации и совместного использования файлов в локальной сети (LAN).Файлы, хранящиеся на устройстве NAS, легко доступны для любого компьютера в сети, имеющего соответствующие права доступа.
- Общие протоколы : Хранилище файлов использует общие протоколы уровня файлов, такие как блок сообщений сервера (SMB), общая файловая система Интернета (CIFS) или сетевая файловая система (NFS). Если вы используете операционную систему Windows или Linux (или обе), стандартные протоколы, такие как SMB / CIFS и NFS, позволят вам читать и записывать файлы на сервер под управлением Windows или Linux через вашу локальную сеть (LAN).
- Защита данных : Хранение файлов на отдельном запоминающем устройстве, подключенном к локальной сети, обеспечивает определенный уровень защиты данных на случай отказа сетевого компьютера. Услуги облачного хранения файлов обеспечивают дополнительную защиту данных и аварийное восстановление за счет репликации файлов данных в нескольких географически разнесенных центрах обработки данных.
- Доступность : Хранение файлов с помощью устройства NAS позволяет перемещать файлы с дорогостоящего компьютерного оборудования на более доступное устройство хранения, подключенное к локальной сети.Более того, если вы решите подписаться на услугу облачного хранения файлов, вы избавитесь от затрат на обновление оборудования на месте и связанных с этим текущих затрат на обслуживание и эксплуатацию.
Сценарии использования
Файловое хранилище — хорошее решение для широкого спектра потребностей в данных, включая следующие:
- Локальный общий доступ к файлам : Если ваши потребности в хранении данных в целом согласованы и просты, например, для хранения файлов и обмена ими с членами команды в офисе, рассмотрите простоту хранения на уровне файлов.
- Централизованная совместная работа с файлами : если вы загружаете, храните и обмениваете файлы в централизованной библиотеке, расположенной на сайте, за его пределами или в облаке, вы можете легко совместно работать над файлами с внутренними и внешними пользователями или с приглашенными гостями. вне вашей сети.
- Архивирование / хранение : Вы можете экономично архивировать файлы на устройствах NAS в среде небольшого центра обработки данных или подписаться на облачную службу хранения файлов для хранения и архивирования ваших данных.
- Резервное копирование / аварийное восстановление : Вы можете безопасно хранить резервные копии на отдельных устройствах хранения, подключенных к локальной сети. Или вы можете подписаться на облачную службу хранения файлов, чтобы реплицировать файлы данных в нескольких географически разнесенных центрах обработки данных и получить дополнительную защиту данных за счет удаленности и избыточности.
Облачное хранилище файлов (или хостинг файлового хранилища)
Сегодняшние средства связи быстро перемещаются в облако, чтобы получить преимущества подхода к общему хранилищу, который по своей сути оптимизирует масштаб и затраты.Вы можете уменьшить размер локальной ИТ-инфраструктуры своей организации, используя недорогое облачное хранилище, сохраняя при этом доступность данных, когда они вам нужны.
Подобно локальной системе хранения файлов, облачное хранилище файлов, также называемое хостингом файловых хранилищ, позволяет нескольким пользователям совместно использовать одни и те же данные файлов. Но вместо того, чтобы хранить файлы данных локально на устройстве NAS, вы можете хранить эти файлы вне офиса в центрах обработки данных (в облаке) и получать к ним доступ через Интернет.
Благодаря облачному хранилищу файлов вам больше не нужно обновлять оборудование хранилища каждые три-пять лет или выделять средства на установку, обслуживание и персонал, необходимый для управления им.Вместо этого вы просто подписываетесь на облачное хранилище за предсказуемую ежемесячную или годовую плату. Вы можете сократить свой ИТ-персонал или перенаправить эти технические ресурсы на более прибыльные области вашего бизнеса.
Хранение файловых данных в облаке также позволяет увеличивать емкость по мере необходимости и по запросу. Сервисы облачного хранения файлов обычно предлагают простые заранее определенные уровни с различными уровнями емкости хранилища и требованиями к производительности рабочих нагрузок (общее количество операций ввода / вывода в секунду или IOPS), а также защиту данных и репликацию в другие центры обработки данных. для непрерывности бизнеса — все за предсказуемую ежемесячную плату.Или вы можете увеличивать или уменьшать количество операций ввода-вывода в секунду и динамически расширять объемы данных, платя только за то, что вы используете.
Услуги облачного хранилища на основе подписки имеют стратегические преимущества, особенно для многосайтовых и более крупных организаций. К ним относятся простота совместного использования в сети местоположений, аварийное восстановление и простота добавления инноваций и технологий, которые появятся в будущем.
Файловое хранилище и IBM Cloud
Решения IBM Cloud File Storage надежны, быстры и гибки.Вы получите защиту от потери данных во время обслуживания или сбоев с помощью шифрования данных в состоянии покоя, а также дублирования томов, создания моментальных снимков и репликации. Центры обработки данных IBM, расположенные по всему миру, гарантируют высокий уровень защиты данных, репликации и аварийного восстановления.
IBM Cloud предлагает четыре предопределенных уровня Endurance с ценой за гигабайт (ГБ), которая фиксирует ваши расходы, обеспечивая предсказуемую почасовую или ежемесячную оплату для ваших краткосрочных или долгосрочных потребностей в хранении данных.Уровни долговечности файлового хранилища поддерживают производительность до 10 000 (10 КБ) операций ввода-вывода в секунду / ГБ и могут удовлетворить потребности большинства рабочих нагрузок, независимо от того, требуется ли вам производительность низкой, общей или высокой интенсивности.
С помощью IBM File Storage вы сможете увеличивать или уменьшать количество операций ввода-вывода в секунду и расширять существующие тома на лету. И вы можете дополнительно защитить свои данные, подписавшись на функцию IBM Snapshot, которая создает доступные только для чтения образы вашего тома файлового хранилища в определенных точках, из которых вы можете легко восстановить свои данные в случае случайной потери или повреждения.
Узнайте больше об уровнях и параметрах производительности IBM File Storage Endurance.
Подпишитесь на бесплатную двухмесячную пробную версию и начните бесплатно создавать в IBM Cloud.
Хранилище файлов, хранилище блоков или хранилище объектов?
Файлы, блоки и объекты — это форматы хранения, в которых хранятся, систематизируются и представляются данные различными способами — каждый со своими возможностями и ограничениями. Хранилище файлов организует и представляет данные в виде иерархии файлов в папках; блочное хранилище разбивает данные на произвольно организованные тома одинакового размера; а объектное хранилище управляет данными и связывает их со связанными метаданными.
Что такое файловое хранилище?
Файловое хранилище, также называемое хранилищем на уровне файлов или файловым хранилищем, — это именно то, что вы думаете: данные хранятся как единый фрагмент информации внутри папки, как если бы вы организовали листы бумаги внутри манилы. папка. Когда вам нужно получить доступ к этому фрагменту данных, ваш компьютер должен знать путь, чтобы найти его. (Осторожно — это может быть длинный извилистый путь.) Данные, хранящиеся в файлах, организованы и извлекаются с использованием ограниченного количества метаданных, которые сообщают компьютеру, где именно хранится сам файл.Это как каталог библиотечных карточек для файлов данных.
Представьте себе шкаф, полный картотек . Каждый документ организован в определенную логическую иерархию — по шкафу, по ящику, по папке, затем по листу бумаги. Отсюда и появился термин «иерархическое хранилище» — файловое хранилище. Это старейшая и наиболее широко используемая система хранения данных для систем хранения с прямым и подключением к сети, и вы, вероятно, используете ее на протяжении десятилетий. Каждый раз, когда вы получаете доступ к документам, сохраненным в файлах на вашем персональном компьютере, вы используете хранилище файлов.Файловое хранилище имеет широкие возможности и может хранить что угодно. Он отлично подходит для хранения массива сложных файлов и позволяет пользователям быстро перемещаться по ним.
Проблема в том, что, как и в случае с вашим картотечным шкафом, этот виртуальный ящик можно открыть только на время. Файловые системы хранения должны масштабироваться за счет добавления дополнительных систем, а не за счет увеличения емкости.
Что такое блочное хранилище?
Блочное хранилище разделяет данные на блоки — понятно? — и хранит их как отдельные части.Каждому блоку данных присваивается уникальный идентификатор, который позволяет системе хранения размещать более мелкие фрагменты данных там, где это наиболее удобно. Это означает, что некоторые данные могут храниться в среде Linux®, а некоторые — в устройстве Windows.
Блочное хранилище часто конфигурируется так, чтобы отделять данные от пользовательской среды и распределять их по нескольким средам, которые могут лучше обслуживать данные. А затем, когда данные запрашиваются, базовое программное обеспечение хранилища повторно собирает блоки данных из этих сред и представляет их обратно пользователю.Обычно он развертывается в средах сети хранения данных (SAN) и должен быть привязан к работающему серверу.
Поскольку блочное хранилище не зависит от единственного пути к данным, как файловое хранилище, его можно получить быстро. Каждый блок живет сам по себе и может быть разбит на разделы, чтобы к нему можно было получить доступ в другой операционной системе, что дает пользователю полную свободу настраивать свои данные. Это эффективный и надежный способ хранения данных, который прост в использовании и управлении. Он хорошо работает с предприятиями, выполняющими крупные транзакции, и предприятиями, которые развертывают огромные базы данных, а это означает, что чем больше данных вам нужно хранить, тем лучше вы будете с блочным хранилищем.
Но есть и недостатки. Блочное хранилище может быть дорогим. Он имеет ограниченные возможности для обработки метаданных, а это означает, что с ним нужно работать на уровне приложения или базы данных, добавляя еще одну вещь, о которой разработчик или системный администратор должен беспокоиться.
Что такое объектное хранилище?
Объектное хранилище, также известное как объектно-ориентированное хранилище, представляет собой плоскую структуру, в которой файлы разбиваются на части и распределяются по оборудованию. В объектном хранилище данные разбиваются на дискретные единицы, называемые объектами, и хранятся в едином репозитории, а не в виде файлов в папках или блоков на серверах.
Тома хранилища объектов работают как модульные блоки: каждый из них представляет собой автономный репозиторий, в котором хранятся данные, уникальный идентификатор, позволяющий найти объект в распределенной системе, и метаданные, описывающие данные. Эти метаданные важны и включают такие детали, как возраст, личные данные / ценные бумаги и непредвиденные обстоятельства доступа. Метаданные хранилища объектов также могут быть чрезвычайно подробными и могут хранить информацию о том, где было снято видео, какая камера использовалась и какие актеры показаны в каждом кадре.Для извлечения данных операционная система хранилища использует метаданные и идентификаторы, которые лучше распределяют нагрузку и позволяют администраторам применять политики, которые выполняют более надежный поиск.
Для объектного хранилища требуется простой интерфейс прикладного программирования (API) HTTP, который используется большинством клиентов на всех языках. Хранилище объектов экономично: вы платите только за то, что используете. Его легко масштабировать, что делает его отличным выбором для общедоступного облачного хранилища. Это система хранения, хорошо подходящая для статических данных, а ее гибкость и простой характер означают, что ее можно масштабировать до чрезвычайно больших объемов данных.Объекты содержат достаточно информации, чтобы приложение могло быстро найти данные, и хорошо хранят неструктурированные данные.
Конечно, есть недостатки. Объекты нельзя изменять — нужно сразу полностью написать объект. Хранилище объектов также плохо работает с традиционными базами данных, потому что запись объектов — медленный процесс, а написание приложения для использования API хранилища объектов не так просто, как использование хранилища файлов.
Почему Red Hat?
Не уверены, какой формат хранения подходит для вашего проекта? С Red Hat Data Services вам не нужно выбирать.Red Hat Ceph Storage предоставляет SDS для стандартного оборудования по вашему выбору. Благодаря объединению блочного, объектного и файлового хранилища в одну платформу, он эффективно и автоматически управляет всеми вашими данными. Red Hat Gluster Storage — это платформа SDS, разработанная для удовлетворения требований традиционного файлового хранилища — задач большой емкости, таких как резервное копирование и архивирование, а также высокопроизводительных задач аналитики и виртуализации.
Что такое файловое хранилище? — Определение из WhatIs.com
Хранилище файлов, также называемое хранилищем файлового уровня или хранилищем файлового уровня , хранит данные в иерархической структуре.Данные сохраняются в файлах и папках и представляются как системе, хранящей их, так и системе, извлекающей их, в одном и том же формате. Доступ к данным можно получить с помощью протокола сетевой файловой системы (NFS) для Unix или Linux или протокола блока сообщений сервера (SMB) для Microsoft Windows.
NFS, первоначально разработанная Sun Microsystems, позволяет клиенту хранить и просматривать файлы на сервере, как если бы они находились на клиентском компьютере. Вся файловая система или ее часть могут быть смонтированы на сервере, где она доступна клиентам с назначенными привилегиями для файла.SMB использует пакеты данных, отправляемые клиентом на сервер, который отвечает на запрос. Большинство сетевых хранилищ (NAS) поддерживают NFS и SMB, которые формально назывались общей файловой системой Интернета.
Файловое и блочное хранилищеВ то время как системы хранения на уровне блоков записывают и извлекают данные из определенных блоков, хранилище на уровне файлов запрашивает данные через интерфейсы представления данных на уровне пользователя. Этот метод связи клиент-сервер происходит, когда клиент использует имя файла данных, расположение каталога, URL-адрес и другую информацию.При хранении на уровне блоков сервер получает запрос на регистрацию, ищет места хранения данных, в которых хранятся данные, и извлекает их с помощью функций уровня хранения. Сервер отправляет файл клиенту не в виде блоков, а в виде байтов файла. Протоколы файлового уровня не могут понимать команды блокировки, а протоколы блоков не могут передавать запросы и ответы на доступ к файлам.
Унифицированное хранилище, также известное как многопротокольное хранилище , предлагает доступ на уровне блоков Fibre Channel и iSCSI, который есть в системах хранения данных (SAN), и доступ на уровне файлов NAS в одном устройстве.Унифицированное хранилище впервые было использовано примерно в 2002 году, и сейчас это обычная архитектура хранилища.
Отдельные продукты для корпоративных файловых хранилищ NAS и SAN могут также предлагать расширенные функции управления данными, такие как дедупликация данных и тонкое выделение ресурсов, которые могут обеспечить большую ценность с виртуальными инфраструктурами.
Рост файловых систем храненияВ последние годы такие тенденции центров обработки данных, как аналитика больших данных и технологии облачного хранения, способствовали быстрому росту компьютерных файловых хранилищ.Еще одним фактором, способствующим этому, является количество приложений, использующих строго файловый доступ, а не доступ к базе данных.
Как правило, файловые системы NAS— наиболее эффективный способ справиться с ростом объема файловых данных. Но слишком много файловых серверов может привести к изоляции, поскольку пользователям может не хватать глобального пространства имен на нескольких платформах. Это заставляет администраторов запускать несколько систем одновременно.
Хотя добавление систем NAS является правильным подходом к борьбе с резким увеличением объема компьютерных файловых хранилищ, предпочтительным методом является использование горизонтально масштабируемой системы NAS, кластерной системы NAS или файловой виртуализации NAS для их одновременного запуска.
См. Также : сетевое хранилище (NAS)
Что такое файловое хранилище и чем оно отличается от объектного хранилища
В чем разница и почему это имеет значение
Данные — это источник жизненной силы любой современной организации. Наша способность к совместному использованию, хранению и использованию имеет решающее значение для развития бизнеса, повышения операционной эффективности, удовлетворенности клиентов и получения конкурентных преимуществ. Это также жизненно важно для расширения прав и возможностей сотрудников, предоставляя им доступ к информации, необходимой им для выполнения своей работы.Это особенно верно в связи с тем, что все больше из нас работают удаленно во время нынешнего кризиса в области здравоохранения.
Все мы знаем, что объем данных стремительно растет — организациям приходится покупать больше хранилищ данных, чем когда-либо прежде. И это большая проблема. Однако каждая организация сталкивается с другой большой проблемой, которая затрагивает всех — руководителей бизнеса, ИТ-специалистов и пользователей, — хотя и влияет на них по-разному. И вот что: не все данные одинаково ценны.
Данные похожи на наличные деньги. Мы обрабатываем, защищаем и используем наличные деньги в нашем кошельке по-разному в зависимости от их стоимости.Мы гораздо внимательнее относимся к тому, как мы заботимся о 100-долларовых счетах и как тратим их, чем о 1-долларовых. То же самое и с данными. Не все из них одинаково важны и, что более важно, его ценность со временем меняется — обычно из-за содержащейся в нем информации, частоты доступа и даже возраста данных. В идеале организации должны иметь платформы хранения, которые созданы для разумной обработки важности данных, а не просто для неразумного хранения битов и байтов. Вот почему поставщики хранилищ данных ввели понятие «Температура данных.”
Для иллюстрации: обычно наблюдается короткий всплеск неистовой активности с вновь созданными данными, но со временем эта активность быстро спадает. Обычно 90% операций ввода-вывода приходится на 10% хранилища данных. Для большинства организаций также верно то, что активно используется только около 20% всех данных. Таким образом, 80% данных просто пугают. Его можно использовать раз в месяц, раз в год или никогда больше. На изображении ниже показано, как температура данных соотносится со своим значением.Горячие данные активно используются и очень ценны для организации. Неактивные данные холодны и менее ценны, но вам все равно придется хранить их для возможного использования в будущем, что может снова сделать их горячими.
Следует отметить, что доступ к данным не обязательно должен быть единственным детерминированным фактором для неактивных / холодных данных. Для неструктурированных данных могут существовать другие бизнес-требования, определяющие, когда данные могут считаться неактивными, такие как возраст данных, стоимость их хранения, уровень защиты, соответствие требованиям и т. Д.
Давайте посмотрим на мир неструктурированных данных, в котором данные более распределены, и на два популярных формата хранения данных: файловую систему и хранилище объектов.
Что такое файловое хранилище?
Файловое хранилище (также известное как файловое хранилище или хранилище на уровне файлов) — это тип хранилища данных, в котором данные хранятся в иерархической структуре файлов и папок. Файл хранится как единое целое без разделения данных на блоки, например в блочном хранилище. Файлы могут храниться в папках, которые затем могут быть помещены в другие папки во вложенной структуре.Путь к каталогу файла и папка, в которой он хранится, необходимы для повторного вызова этого файла из места его хранения. В системах NAS обычно используется файловое хранилище, и они сравнительно дешевле, чем блочные хранилища.
Что такое файловая система храненияЕсли у вас есть компьютер, вы использовали файловую систему. Файловые системы содержат документы, презентации, изображения, все виды ресурсов, которые мы перемещаем на нашем рабочем столе или храним в нашей папке «Документы». Файловые системы дают нам иерархическую систему организации.Это аналогичный подход к использованию картотеки с данными, упорядоченными по именованным каталогам, папкам, подпапкам и файлам. Приложения и пользователи знают, где все находится, по имени и местоположению. Файловые системы отлично подходят для простого входа и выхода, если вы знаете, где находится то, что ищете.
Для хранения файлов, выходящих за рамки обычного настольного компьютера или ноутбука, организации используют решения NAS (сетевое хранилище) и файловые серверы, чтобы обеспечить специализированные и оптимизированные возможности совместного использования файлов в сети.Обычно они обеспечивают поддержку протоколов NFS и SMB для использования в средах Unix, Linux и Windows. Они отлично подходят для хранения или совместного использования файлов и документов.
NASобычно подходит для хранения или совместного использования файлов и документов, а также для управления доступом. Но, как вы знаете по собственному рабочему столу, вы работаете только с несколькими файлами за раз. Большинство файлов на жестком диске холодные или холодные. Если это верно для файлового сервера или NAS, системе не хватает памяти или падает производительность — как и у вашего ноутбука.В таких случаях ИТ-организации могут рассматривать хранилище объектов как средство хранения холодных (или неактивных) данных.
Что такое объектное хранилище?
Объектное хранилище (также известное как объектное хранилище) — это тип хранилища данных, используемый для обработки больших объемов неструктурированных данных, где данные объединяются вместе с тегами метаданных и уникальным идентификатором. Каждый из этих автономных наборов объектных данных помещается в плоское адресное пространство, известное как пул хранения. В отличие от файлового хранилища, объектное хранилище не имеет иерархической структуры.Метаданные содержат описание данных, а уникальный идентификатор используется для легкого извлечения объекта вместо имени файла и пути к файлу. Облачное хранилище S3 — это популярный вариант хранилища объектов в дополнение к развертыванию локального хранилища объектов.
Понимание системы хранения объектовОбъектное хранилище — это более свежий подход, который не навязывает файловую систему данным. Вместо этого используются метаданные для описания всех деталей о базовых данных. Это может включать имя, дату создания, местоположение, владельца и многое другое.Таблицы используются для того, чтобы можно было хранить, отслеживать и извлекать данные на основе этих метаданных.
Работает так же, как и услуга парковщика на автостоянке. Представьте себе миллионы машин на огромной парковке. Служащий предоставит вам парковочный талон в обмен на вашу машину, а затем припаркует ее для вас. Вам не нужно знать, где он припаркован, просто он безопасен и будет доступен, когда он вам понадобится. Оператор может получить его в любое время на основе информации (или метаданных) о парковочном талоне, независимо от размера парковки.
Объектное хранилище отличается низкой стоимостью, большой масштабируемостью и возможностями глобального доступа. Компромиссы включают задержку и производительность, но со временем они улучшаются. Для пользователей, которым почти никогда не нужен доступ к старым файлам и документам, он почти невидим. Но для организаций, которым необходимо хранить все необходимое для соблюдения нормативных требований или правовой защиты, хранение объектов имеет важное значение.
Помещение нужных данных в нужное место в нужное время
Главный вывод: разные данные имеют большую или меньшую ценность в зависимости от времени, пользователей и важности.Это означает, что наиболее подходящее хранилище для любых конкретных данных будет зависеть от того, насколько они ценны в данный момент и от конкретных потребностей приложений или конечных пользователей, использующих их, или от его важности для бизнеса. И администратору хранилища практически невозможно определить это изо дня в день. В конце концов, ваша организация создает миллионы документов каждый год. Можете ли вы представить себе, как администратор хранилища копается в каждом документе, пытаясь решить, является ли он горячим, теплым или холодным, или вручную применяет различные условия релевантности для бизнеса и решает, какие данные размещать на каком устройстве хранения?
Проблема в том, что до сих пор у нас не было хорошего способа убедиться, что данные — будь то на устройствах NAS или в хранилищах объектов — были в нужном месте в нужное время, тем более что потребности постоянно меняются, файловые и объектные платформы могут поступать от разных поставщиков или использовать разные наборы инструментов, и перенос вручную друг с другом является проблемой.
Вот здесь и появляется современное программно-определяемое решение для хранения данных, такое как vFilO от DataCore.
- Он использует автоматическое размещение на основе AI / ML для перемещения данных в наиболее подходящее хранилище в зависимости от температуры доступа. vFilO проверяет тепловой шаблон данных, хранящихся на устройстве хранения, а затем определяет, следует ли хранить данные на устройстве NAS премиум-класса или переместить их в более дешевые альтернативы (например, хранилища объектов). vFilO проверяет не только частоту доступа к данным, но и другие настраиваемые критерии, основанные на важности бизнеса, которые может установить администратор хранилища, например возраст файла, местоположение, отказоустойчивость и т. д.Это означает, что вы можете сбалансировать производительность, емкость, операционную эффективность и факторы стоимости. Высокопроизводительное и дорогое хранилище может быть зарезервировано для горячих данных, в то время как критически важные (или неактивные) данные могут быть перенесены в дешевое хранилище или облако.
- Вы можете задействовать всю доступную емкость в организации, открывая карманы неиспользуемого хранилища, о котором вы даже не подозревали. Это означает, что вы можете отложить дорогостоящие обновления или вообще их избежать.
- Благодаря глобальному пространству имен легко находить нужные данные, когда они нужны.Все данные файлов и объектов теперь доступны с центральной консоли, независимо от того, на каком устройстве / типе хранилища они находятся. Используя поиск и поиск на основе метаданных, vFilO ускоряет процесс поиска и доступа к данным на различных типах устройств хранения (файловых или объект, хранящийся локально или в облаке).
Почему эти факторы так важны для руководителей бизнеса, ИТ-администраторов и пользователей прямо сейчас?
- Потому что они обеспечивают быстрый и беспрепятственный доступ к данным в любое время и из любого места, помогая стимулировать инновации и получать конкурентное преимущество.
- Потому что вы можете сбалансировать и точно настроить производительность, емкость, операционную эффективность и стоимость для всего ландшафта системы хранения.
- Потому что они дают вам полную видимость и контроль, чтобы адаптироваться к радикально новым экономическим реалиям и даже к новой парадигме в значительной степени удаленной рабочей силы.
В качестве альтернативы, почему бы не позвонить DataCore, чтобы обсудить ваши конкретные требования?
Полезные ресурсы:
Объектное хранилищеи файловое хранилище: в чем разница?
Хранилище объектов существует только с середины 90-х годов.Поскольку это относительно новый ребенок в блоке, может возникнуть некоторая путаница в том, чем он отличается от других типов хранилищ, таких как блочное или файловое хранилище. Этот пост является первым в серии, посвященной этим ключевым различиям, с упором на объектное хранилище и файловое хранилище.
Что такое объектное хранилище?
Объектно-ориентированное хранилище, по сути, связывает сами данные с тегами метаданных и уникальным идентификатором. Метаданные можно настраивать, что означает, что вы можете ввести гораздо больше идентифицирующей информации для каждого фрагмента данных.Эти объекты хранятся в плоском адресном пространстве, что упрощает поиск и извлечение ваших данных в разных регионах.
Это плоское адресное пространство также способствует масштабируемости. Просто добавив дополнительные узлы, вы можете масштабировать их до петабайт и более.
Учебник по хранилищу файлов
Файловое хранилище существует гораздо дольше, чем объектное хранилище, и с ним знакомо большинство людей. Вы называете свои файлы / данные, помещаете их в папки и можете вкладывать их в другие папки, чтобы сформировать заданный путь.Таким образом файлы организованы в иерархию с каталогами и подкаталогами. С каждым файлом также связан ограниченный набор метаданных, таких как имя файла, дата его создания и дата последнего изменения.
До определенного момента это работает очень хорошо, но по мере увеличения емкости файловая модель становится обременительной по двум причинам. Во-первых, производительность страдает сверх определенной емкости. Сама система NAS имеет ограниченную вычислительную мощность, что делает процессор узким местом.Производительность также страдает из-за огромной базы данных — таблиц поиска файлов — которые сопровождают рост емкости.
Объектное хранилище и файловое хранилище
Теперь, когда вы знакомы с основами объектно-ориентированного хранилища и файлового хранилища, давайте рассмотрим некоторые ключевые различия между ними.
Для начала, объектное хранилище преодолевает многие ограничения, с которыми сталкивается файловое хранилище. Думайте о файловом хранилище как о складе. Когда вы впервые кладете туда коробку с файлами, кажется, что у вас много места.Но по мере роста ваших потребностей в данных вы заполните хранилище до предела, прежде чем это заметите. С другой стороны, хранилище объектов похоже на склад, только без крыши. Вы можете добавлять данные бесконечно — безграничный предел.
Если вы в первую очередь извлекаете файлы меньшего размера или отдельные файлы, то файловое хранилище отличается производительностью, особенно при относительно небольших объемах данных. Однако как только вы начнете масштабировать, вы можете начать задаваться вопросом: «Как мне найти нужный мне файл?»
В этом случае вы можете думать о хранилище объектов как о парковке автомобиля служащим, в то время как файловое хранилище больше похоже на самостоятельную парковку (да, еще одна аналогия, но потерпите меня!).Когда вы загоняете свою машину на небольшой участок, вы точно знаете, где находится ваша машина. Однако представьте, что этот участок был в тысячу раз больше — найти свою машину будет сложнее, не так ли?
Поскольку в хранилище объектов есть настраиваемые метаданные, а все объекты находятся в едином адресном пространстве, это похоже на передачу ключей служащему. Ваш автомобиль будет где-то храниться, и когда он вам понадобится, камердинер предоставит вам автомобиль. Чтобы вернуть машину, может потребоваться немного больше времени, но вам не нужно беспокоиться о том, чтобы искать ее.Все эти функции и преимущества также распространяются на хранилище объектов в облаке.
Хранилище объектов и хранилище файлов
СКАЧАТЬ PDF
Метаданные объектного хранилища
В качестве реального примера того, почему метаданные имеют значение, мы можем взглянуть на рентгеновские снимки. Файл рентгеновского снимка будет иметь ограниченные метаданные, связанные с ним, такие как дата создания, владелец, местоположение и размер. С другой стороны, объект рентгеновского излучения может иметь большое количество разнообразных метаданных.
Метаданные могут включать в себя имя пациента, дату рождения, подробности травмы, часть тела, на которую был проведен рентгеновский снимок — в дополнение к тем же тегам, что и в файле. Это делает невероятно полезным для врачей получать необходимую информацию для справки.
Если вам нужно более прямое параллельное сравнение, взгляните на эту таблицу, в которой сравнивается объектно-ориентированное хранилище и файловое хранилище:
| ХРАНЕНИЕ ОБЪЕКТОВ | ХРАНИЛИЩЕ ФАЙЛОВ | |
|---|---|---|
| ХАРАКТЕРИСТИКИ | Лучше всего подходит для большого контента и высокой пропускной способности потока | Лучше всего подходит для файлов меньшего размера |
| ГЕОГРАФИЯ | Данные могут храниться в нескольких регионах | Как правило, к данным требуется общий доступ локально |
| МАСШТАБИРУЕМОСТЬ | Бесконечно масштабируется до петабайт и выше | Возможно масштабирование до миллионов файлов, но не может обрабатывать больше |
| АНАЛИТИКА | Настраиваемые метаданные, не ограниченные количеством тегов | Ограниченное количество установленных тегов метаданных |
Это был лишь общий обзор различий между хранилищем объектов и хранилищем файлов, но он должен дать вам более четкое представление о преимуществах каждого типа.
Хранилище объектов и хранилище файлов вместе
Теперь Cloudian предлагает способ получить все преимущества объектно-ориентированного хранилища для ваших файлов: Cloudian HyperFile, горизонтально масштабируемая система хранения файлов, которая предоставляет функции NAS вместе с масштабируемостью и стоимостью объектно-ориентированного хранилища.
Для получения дополнительной информации загрузите Руководство покупателя Object Storage.
Объектное хранилище vs блочное хранилище vs файловое хранилище: что выбрать?
Объектное хранилище — Облачное хранилище
Облачное хранилище — это объектное хранилище для двоичных и объектных данных, больших двоичных объектов и неструктурированных данных.Обычно вы используете его для любого приложения, любого типа данных, которые вам нужно хранить, на любой срок. Вы можете добавлять к нему данные или извлекать из него данные так часто, как вам нужно. Сохраненные объекты имеют идентификатор, метаданные, атрибуты и фактические данные. Метаданные могут включать в себя всевозможные сведения о классификации безопасности файла, приложениях, которые могут получить к нему доступ, и аналогичную информацию.
Сценарии использования хранилища объектов включают приложения, которым необходимы данные для обеспечения высокой доступности и надежности, например потоковая передача видео, обслуживание изображений и документов, а также веб-сайты.Он также используется для хранения больших объемов данных в таких случаях, как геномика и аналитика данных. Вы также можете использовать его для хранения резервных копий и архивов в соответствии с нормативными требованиями. Или используйте его для замены старых физических ленточных записей и перемещения их в облачное хранилище. Он также широко используется для аварийного восстановления, поскольку для восстановления после аварии практически не требуется времени, чтобы переключиться на корзину резервного копирования.
Существует 4 класса хранилищ в зависимости от бюджета, доступности и частоты доступа.
1. Стандартные сегменты для высокопроизводительного, частого доступа и высочайшей доступности:
— Региональные / двухрегиональные местоположения для часто используемых данных / потребности в высокой пропускной способности
— Многорегиональные для обслуживания контента по всему миру
2. Непосредственный доступ к данным доступ реже одного раза в месяц
3. Холодная линия для данных, доступ к которым осуществляется примерно реже, чем раз в квартал
4. Архив для данных, которые вы хотите хранить на годы
Использование стандартного хранилища стоит немного дороже, поскольку оно позволяет автоматически резервировать и варианты частого доступа.Непосредственное, холодное и архивное хранилище обеспечивает доступность 99% и значительно дешевле.
Блочное хранилище — постоянный диск и локальный SSD
Постоянный диск и локальный SSD — это варианты блочного хранилища. Они интегрированы с виртуальными машинами Compute Engine и Kubernetes Engine. При блочном хранилище файлы разделяются на блоки данных одинакового размера, каждый со своим адресом, но без дополнительной информации (метаданных), чтобы предоставить больше контекста для того, что это за блок данных. Операционная система может получить прямой доступ к блочному хранилищу в виде подключенного тома диска.
Persistent Disk — это хранилище блоков для виртуальных машин, которое предлагает различные варианты задержки и производительности. В этой статье я подробно рассмотрел постоянный диск. Сценарии использования постоянного диска включают диски для виртуальных машин и общие данные только для чтения на нескольких виртуальных машинах. Он также используется для быстрого и надежного резервного копирования работающих виртуальных машин. Благодаря доступным параметрам высокой производительности постоянный диск также является хорошим вариантом хранения для баз данных.
Локальный твердотельный накопитель также является блочным хранилищем, но по своей природе он недолговечен и поэтому обычно используется для рабочих нагрузок без сохранения состояния, требующих минимальных доступных задержек.Варианты использования включают в себя базы данных, оптимизированные для флэш-памяти, уровни кэширования хоста для аналитики или рабочие диски для любого приложения, а также масштабирование аналитики и рендеринга мультимедиа.
Хранилище файлов — хранилище файлов
Теперь, хранилище файлов! Как полностью управляемое сетевое хранилище (NAS) Filestore предоставляет облачную общую файловую систему для неструктурированных данных. Он предлагает действительно низкую задержку и обеспечивает одновременный доступ к десяткам тысяч клиентов с масштабируемой и предсказуемой производительностью до сотен тысяч операций ввода-вывода в секунду, пропускной способностью до десятков ГБ / с и сотнями ТБ.Вы можете увеличивать и уменьшать емкость по запросу. Типичные варианты использования Filestore включают высокопроизводительные вычисления (HPC), обработку мультимедиа, автоматизацию проектирования электроники (EDA), миграцию приложений, управление веб-контентом, аналитику данных науки о жизни и многое другое!
Заключение
Это был краткий обзор различных вариантов хранения в Google Cloud. Для более подробного изучения каждого из этих вариантов хранения просмотрите эту страницу параметров облачного хранилища или это видео 👇
Обзор хранилища данных и файлов | Разработчики Android
Android использует файловую систему, аналогичную дисковым файловым системам других платформы.В системе предусмотрено несколько вариантов сохранения данных приложения:
- Хранилище для конкретного приложения: Хранить файлы, предназначенные только для использования вашим приложением, либо в выделенных каталогах на внутреннем томе хранения, либо в разных выделенные каталоги во внешнем хранилище. Используйте каталоги внутри внутреннее хранилище для хранения конфиденциальной информации, к которой другие приложения не должны иметь доступа.
- Общее хранилище: Храните файлы, которыми ваше приложение собирается поделиться с другими приложения, включая мультимедиа, документы и другие файлы.
- Предпочтения: Хранить частные примитивные данные в парах «ключ-значение».
- Базы данных: Хранить структурированные данные в частной базе данных с помощью Room библиотека настойчивости.
Характеристики этих опций приведены в следующей таблице:
| Тип содержания | Метод доступа | Необходимые разрешения | Могут ли другие приложения получить доступ? | Файлы удалены при удалении приложения? | |
|---|---|---|---|---|---|
| Зависит от приложения файлы | Файлы, предназначенные только для вашего приложения | Из внутренней памяти, getFilesDir () или getCacheDir () Из внешнего хранилища, | Не требуется для внутренней памяти Не требуется для внешней хранилище, когда ваше приложение используется на устройствах под управлением Android 4.4 (уровень API 19) или выше | № | Есть |
| СМИ | Совместно используемые медиа-файлы (изображения, аудиофайлы, видео) | MediaStore API | READ_EXTERNAL_STORAGE при доступе к файлам других приложений на
Android 11 (уровень API 30) или выше Требуются разрешения для всех файлов на Android 9 (уровень API 28) или нижняя | Да, хотя другому приложению требуется READ_EXTERNAL_STORAGE разрешение | № |
| Документы и другие файлы | Другие типы совместно используемого содержимого, включая загруженные файлы | Платформа доступа к хранилищу | Нет | Да, через системный сборщик файлов | № |
| Приложение предпочтения | Пары ключ-значение | Реактивный ранец Библиотека настроек | Нет | № | Есть |
| База данных | Структурированные данные | Библиотека сохраняемости помещения | Нет | № | Есть |
Решение, которое вы выберете, зависит от ваших конкретных потребностей:
- Сколько места требуется для ваших данных?
- Внутреннее хранилище имеет ограниченное пространство для данных приложений.Используйте другие типы хранилище, если вам нужно сохранить значительный объем данных.
- Насколько надежным должен быть доступ к данным?
- Если для основных функций вашего приложения требуются определенные данные, например, когда ваше приложение запускается, поместите данные в каталог внутреннего хранилища или в базу данных. Файлы для конкретных приложений, которые хранятся во внешнем хранилище, не всегда доступны потому что некоторые устройства позволяют пользователям удалять физическое устройство, которое соответствует внешнее хранилище.
- Какие данные вам нужно хранить?
- Если у вас есть данные, которые имеют значение только для вашего приложения, используйте специфичные для приложения место хранения.Для общего мультимедийного контента используйте общее хранилище, чтобы другие приложения могли получить доступ к контенту. Для структурированных данных используйте любой параметр (для пары «ключ-значение» data) или базу данных (для данных, содержащих более 2 столбцов).
- Должны ли данные быть приватными для вашего приложения?
- При хранении конфиденциальных данных — данных, которые не должны быть доступны из других приложение — использовать внутреннее хранилище, настройки или базу данных. Внутреннее хранилище имеет дополнительное преимущество скрытия данных от пользователей.
Категории мест хранения
Android предоставляет два типа физических хранилищ: внутреннее хранилище , и внешнее хранилище .На большинстве устройств внутреннее хранилище меньше внешнего место хранения. Однако внутреннее хранилище всегда доступно на всех устройствах, что делает его более надежное место для хранения данных, от которых зависит ваше приложение.
Съемные тома, такие как SD-карта, появляются в файловой системе как часть
внешнее хранилище. Android представляет эти устройства с помощью пути, например / SDCard .
Сами приложения по умолчанию хранятся во внутренней памяти. Если ваш размер APK очень большой, однако вы можете указать предпочтение в манифесте вашего приложения файл, чтобы вместо этого установить приложение на внешнее хранилище:
<манифест ...
android: installLocation = "seekExternal" >
...
Разрешения и доступ к внешнему хранилищу
Android определяет следующие разрешения, связанные с хранилищем: READ_EXTERNAL_STORAGE , WRITE_EXTERNAL_STORAGE ,
и УПРАВЛЕНИЕ_ЭКСТЕРНАЛ_ХРАНИЛИЩЕ .
В более ранних версиях Android приложениям нужно было объявить READ_EXTERNAL_STORAGE разрешение на доступ к любому файлу за пределами конкретного приложения
каталоги на внешнем хранилище.
Кроме того, приложениям необходимо было объявить разрешение WRITE_EXTERNAL_STORAGE на запись в
любой файл за пределами каталога конкретного приложения.
Более поздние версии Android больше зависят от назначения файла, чем от его местоположения.
для определения возможности приложения получить доступ к заданному файлу и выполнить запись в него.В
в частности, если ваше приложение нацелено на Android 11 (уровень API 30) или выше, WRITE_EXTERNAL_STORAGE разрешение не влияет на работу вашего приложения
доступ к хранилищу. Эта целевая модель хранения улучшает конфиденциальность пользователей.
потому что приложениям предоставляется доступ только к тем областям файловой системы устройства, которые
они действительно используют.
Android 11 представляет разрешение MANAGE_EXTERNAL_STORAGE , которое обеспечивает
доступ на запись к файлам за пределами каталога приложения и MediaStore .К
узнать больше об этом разрешении и почему большинству приложений не нужно объявлять его
выполнить их варианты использования, см. руководство о том, как управлять всеми
файлы на запоминающем устройстве.
Склад с ограниченным объемом
Чтобы предоставить пользователям больший контроль над своими файлами и ограничить беспорядок в файлах, приложения, которые целевой Android 10 (уровень API 29) и выше получает ограниченный доступ к внешним хранилище или хранилище с областью действия по умолчанию. Такие приложения имеют доступ только к каталог приложения на внешнем хранилище, а также определенные типы носителей созданное приложением.
Примечание: Если ваше приложение запрашивает разрешение, связанное с хранилищем, во время выполнения, диалоговое окно, открытое для пользователя, указывает на то, что ваше приложение запрашивает широкий доступ к внешнее хранилище, даже если включено хранилище с заданной областью. Используйте хранилище с заданной областью, если вашему приложению не требуется доступ к файлу, который хранится за пределами
каталога конкретного приложения и за его пределами
каталога, который MediaStore API могут получить доступ. Если вы храните файлы для конкретных приложений на внешнем хранилище, вы можете
упростить внедрение хранилища с ограниченным объемом, поместив эти файлы в
каталог приложения на внешнем
место хранения.Таким образом, ваше приложение
поддерживает доступ к этим файлам, когда включено хранилище с заданной областью.
Чтобы подготовить приложение к ограниченному хранилищу, просмотрите варианты использования хранилища и лучшие руководство по практике. Если у вашего приложения есть другое применение дело, которое не охвачено хранилищем с ограниченным объемом, зарегистрируйте функцию запрос. Ты можешь временно отказаться от использования ограниченного доступа место хранения.
Просмотр файлов на устройстве
Для просмотра файлов, хранящихся на устройстве, используйте файл устройства Android Studio.
Ваш комментарий будет первым