Стирание данных с компьютера Mac с чипом Apple с помощью приложения «Дисковая утилита»
Как стереть (отформатировать) встроенный загрузочный диск компьютера Mac с чипом Apple.
Перед стиранием данных с компьютера Mac
- Установите последние обновления macOS.
- Если вы используете ОС macOS Monterey или более поздней версии, следуйте инструкциям по стиранию контента и настроек и не выполняйте действия, описанные в этой статье. Также следует удалить все содержимое и настройки при продаже, передаче или обмене компьютера Mac.
- Устройства Bluetooth будут отключены от Mac (пара между ними будет разорвана). Чтобы выполнить указанные действия с помощью клавиатуры, мыши или трекпада Bluetooth, потребуется подключить устройство с помощью USB-кабеля, если это возможно.
- Создайте резервную копию любых файлов, которые требуется сохранить. При стирании данных с компьютера Mac навсегда удаляются все файлы.
Стирание данных с компьютера Mac при помощи Дисковой утилиты
- Нажмите кнопку питания для включения компьютера Mac и продолжайте удерживать ее нажатой, пока не отобразится окно с параметрами запуска.
 Выберите «Параметры», а затем нажмите «Продолжить».
Выберите «Параметры», а затем нажмите «Продолжить». - Если потребуется, выберите пользователя, пароль которого вы знаете, а затем введите его пароль администратора.
- Если потребуется, введите идентификатор Apple ID и пароль, которые ранее использовались с этим компьютером Mac. Узнайте, что делать, если вы забыли свой идентификатор Apple ID.
- В окне утилит выберите «Дисковая утилита» и нажмите «Продолжить».
- Убедитесь, что в разделе «Внутренние» в боковом меню приложения «Дисковая утилита» отображается том с названием Macintosh HD. Не видите том Macintosh HD?
- Если ранее вы использовали приложение «Дисковая утилита» для добавления томов на загрузочном диске, выберите каждый дополнительный внутренний том в боковом меню, затем нажмите кнопку удаления тома (–) на панели инструментов, чтобы удалить этот том.
На этом этапе игнорируйте любые внутренние тома с названием Macintosh HD или Macintosh HD — Data, а также тома, указанные в разделах «Внешние» и «Образы дисков» в боковом меню. - Теперь выберите том Macintosh HD в боковом меню.
- Нажмите кнопку «Стереть» на панели инструментов, затем укажите имя и формат:
- Имя: Macintosh HD
- Формат: APFS
- Нажмите кнопку «Стереть». Если вы видите кнопку «Стереть группу томов», нажмите ее.
- Если потребуется, введите свой идентификатор Apple ID. Узнайте, что делать, если вы забыли свой идентификатор Apple ID.
- Подтвердите стирание данных с компьютера Mac, нажав «Стереть Mac и перезагрузить».
- После перезапуска компьютера Mac выберите язык, следуя инструкциям на экране.
- Компьютер Mac попытается выполнить активацию, для чего требуется подключение к Интернету. В меню Wi-Fi в строке меню выберите сеть Wi-Fi или подключите сетевой кабель.
- После активации компьютера Mac нажмите «Выйти в утилиты восстановления».
- Если требуется выполнить запуск с только что стертого диска, выберите «Переустановить macOS» в окне утилит, затем нажмите «Продолжить» и следуйте инструкциям на экране, чтобы переустановить macOS.
 Выберите «Параметры», а затем нажмите «Продолжить».
Выберите «Параметры», а затем нажмите «Продолжить».

Если том Macintosh HD не отображается в приложении «Дисковая утилита»
Встроенный загрузочный диск должен быть первым элементом в боковом меню приложения «Дисковая утилита». Он называется Macintosh HD, если только вы не изменили его имя. Если в списке нет этого диска, перейдите в меню Apple > «Выключить», затем отсоедините все вспомогательные устройства от компьютера Mac и проверьте список еще раз.
Если диск по-прежнему не отображается в приложении «Дисковая утилита» или процесс стирания завершается сбоем, возможно, компьютеру Mac требуется обслуживание. Если вам нужна помощь, свяжитесь со службой поддержки Apple.
Дата публикации:
Какие параметры компьютера влияют на скорость сборки Gradle проекта / Хабр
Как вы думаете, какие характеристики сильнее влияют на скорость сборки вашего проекта: частота CPU или частота оперативной памяти? Количество ядер CPU или количество оперативной памяти? Влияет ли скорость постоянной памяти на скорость сборки? Однажды у меня в голове возникли такие вопросы, и я решил найти на них ответы. Лучший способ для этого — провести тесты. Поэтому представляю вам их результаты и попытаюсь их объяснить в меру своих знаний. Если хотите узнать, что больше всего влияет на скорость сборки, ну или, может быть, хотите обновить компьютер для сборки, но не знаете, во что лучше вложится, то добро пожаловать в статью.
Лучший способ для этого — провести тесты. Поэтому представляю вам их результаты и попытаюсь их объяснить в меру своих знаний. Если хотите узнать, что больше всего влияет на скорость сборки, ну или, может быть, хотите обновить компьютер для сборки, но не знаете, во что лучше вложится, то добро пожаловать в статью.
Начнём с того, что «А зачем вообще нам это знать?».
По сути, есть одна основная проблема — непонятно, какое железо стоит брать.
Обычно бюджет покупки ограничен. Будь это покупка компьютера для себя или же для CI. Хочется за свой бюджет получить максимум.
Из чего следуют основные цели статьи:
Понять, какие параметры и как влияют на скорость сборки.
Как следствие, понять, что лучше купить.
Как следствие, понять, как сэкономить.
Ну и косвенно заденем тему разницы во времени сборки между одномодульным и многомодульным проектами.
Для начала, чтобы результаты тестов для нас были простыми и понятными, давайте определим методологию.
Методология
Сразу предупреждаю: циферок будет много. Очень. Но что поделать, такой «жанр».
Компьютер
Начнём со стенда, над которым и будем издеваться.
Собственно, это мой домашний комп. Так что не ищите сакральной логики в подборе компонентов.
CPU: Ryzen 5 3600, 6 ядер, 12 потоков. Максимальная частота в бусте — 4200 МГц.
RAM: две планки по 8 Гб, две планки по 16 Гб. От Crucial.
Накопители: ноутбучный HDD 2.5”, конечно же, обычный HDD 3.5“, Sata SSD, NVMe SSD.
По умолчанию, если в описании теста не указано иное:
Процессор в режиме Auto. Базовая частота — 3600 МГц, буст до — 4200 МГц.
32 Гб оперативной памяти.
Накопитель NVMe SSD.
Ну и в качестве операционной системы у нас Windows 11.
Проект
В целом данные тесты можно спокойно интерпретировать к любым Gradle JVM проектам. В качестве тестового проекта возьмём наше Android приложение Циан.
На момент проведения тестов в нём: 410 Gradle модулей, 443 тысячи строк Kotlin, 113 тысяч строк Java и 175 тысяч строк XML. Что-то мне подсказывает, что мобильные приложения из тонких клиентов свернули куда-то не туда…
Что-то мне подсказывает, что мобильные приложения из тонких клиентов свернули куда-то не туда…
Инструменты измерения
Для проведения тестов будем использовать Gradle Profiler. Это специальный инструмент, который позволяет производить измерения времени сборки и отдельных её этапов. Также он позволяет писать кастомные сценарии. Что нам очень понадобится.
Затем он генерирует красивый отчёт, в котором сам определяет минимальное, максимальное и медианное время сборки и даже график рисует.
Сценарии
Всего их три:
Многомодульная горячая.
Многомодульная холодная.
Одномодульная холодная.
По названиям, естественно, ничего не понятно, поэтому давайте подробнее разберём каждый из них. Начнём с многомодульной горячей.
Горячая сборка приложения
Для её симуляции просто вносим изменения в Kotlin файл одного из фичёвых модулей и перезапускаем сборку. Этот модуль подключён только к главному (app) модулю, как runtimeOnly.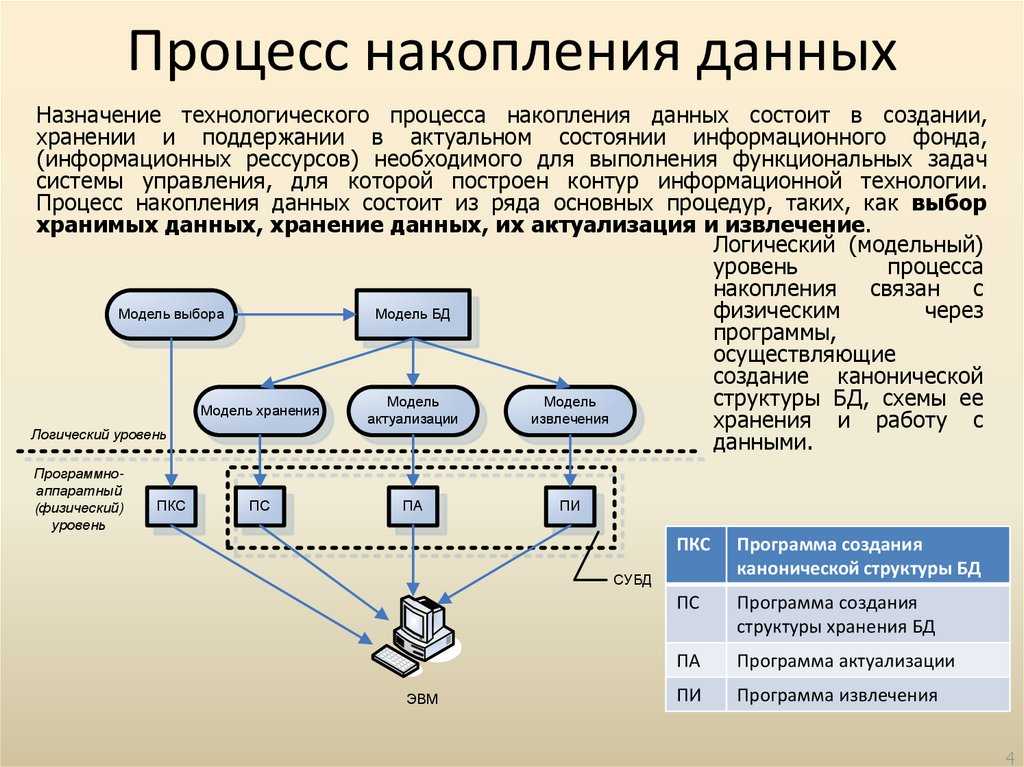
Опасным красным цветом отмечены модули, которые пересоберутся, а зелёным — те, что будут UP-TO-DATE. Выглядит это как-то так:
То есть при изменениях в нём ничего лишнего собираться не будет. Только модуль, в котором произошли изменения и app-модуль. На timeline сборки у нас большинство модулей будут UP-TO-DATE. Так как изменений в части модулей нет, значит и собирать их смысла нет. Модуль с изменениями и app-модуль будут собраны.
По сути, это самый частый сценарий. Я бы назвал его основным.
Холодная сборка приложения
Для её симуляции будем перед сборкой делать clean, а также передадим в Gradle аргумент —no-build-cache. Таким образом, кэши задействованы не будут. Как можно заметить — ни капелюшечки зелёного цвета. Всё красное. В итоге пересоберётся весь проект.
За счёт многомодульности clean и сборка будет осуществляться параллельно, насколько это возможно. Например, последний модуль app обычно собирается в полном одиночестве.
Холодную сборку на локальной машине приходится делать довольно редко. Только когда в проекте что-то поменялось кардинально. Но всё же приходится. Поэтому проверяем.
Только когда в проекте что-то поменялось кардинально. Но всё же приходится. Поэтому проверяем.
Холодная сборка приложения, как будто оно одномодульное
Не все используют многомодульность. А вдруг результаты для одномодульных проектов могут сильно отличаться? Непорядок. Поэтому давайте попытаемся симулировать и такой тип сборки.
Для этого всё также перед сборкой будем делать clean, а также передадим в Gradle аргумент —no-build-cache. Но в дополнение к этому установим всего один Gradle Worker с помощью —max-workers 1 и передадим флаг —no-parallel.
С точки зрения структуры, относительно многомодульной сборки, у нас ничего не меняется.
А вот timeline изменится кардинально. Вместо параллельной сборки у нас все составляющие сборки будут выполняться последовательно.
За счёт этого получается симулировать одномодульное приложение, в котором также всё делается последовательно.
Предупрежу, что будь у нас реальное одномодульное приложение, то оно бы собралось быстрее, чем симуляция, так как не было бы задержек из-за конфигурации и запуска гораздо большего количества task. Но для нас это приемлемо, так как мы будем сравнивать получившиеся результаты только между собой.
Но для нас это приемлемо, так как мы будем сравнивать получившиеся результаты только между собой.
Количество прогонов
Каждый сценарий прогоняется 6 раз: первый раз для «прогрева» и ещё пять раз происходят измерения. В качестве финального результата считаем медианное время сборок.
Это значит, что мы сортируем результат пяти прогонов от меньшего к большему и берём тот, что посередине.
Погрешность
В целом нужно понимать, что у всех железо разное, поэтому не стоит смотреть на абсолютные цифры. Основным критерием будет являться процент, на который стала быстрее собираться сборка. Так как у нас могут быть погрешности, то разницу меньше, чем в 2% не будем учитывать. «2%» — потому что примерно такая разница между значениями, полученными, если последовательно перезапускать сценарии без изменения конфигурации компьютера. Эта минимальная цифра, которую мне удалось достичь. Пришлось побаловаться с настройками Windows, антивируса и служб.Также прикладываю текст файла со сценариями для Gradle Profiler. Мало ли кто-то захочет проверить или повторить тесты.
Мало ли кто-то захочет проверить или повторить тесты.
default-scenarios = ["clean_parallel", "cold_parallel", "hot_parallel", "clean_mono", "cold_mono"]
clean_parallel {
title = "Clean"
cleanup-tasks = ["clean"]
warm-ups = 1
iterations = 5
}
cold_parallel {
title = "Clean AssembleDebug without cache"
tasks = ["assembleDebug"]
warm-ups = 1
cleanup-tasks = ["clean"]
iterations = 5
daemon = none
gradle-args = ["--no-build-cache"]
}
hot_parallel {
title = "AssembleDebug with change kt file"
tasks = ["assembleDebug"]
warm-ups = 1
iterations = 5
apply-abi-change-to = "modules/feature/worktime_settings/impl/src/main/kotlin/ru/cian/worktime/settings/impl/domain/ports/WorkTimeSettingsRepository.kt"
}
clean_mono {
title = "Clean mono"
cleanup-tasks = ["clean"]
gradle-args = ["--no-parallel", "--max-workers", "1"]
warm-ups = 1
iterations = 5
}
cold_mono {
title = "Clean AssembleDebug without cache mono"
tasks = ["assembleDebug"]
gradle-args = ["--no-build-cache", "--no-parallel", "--max-workers", "1"]
warm-ups = 1
cleanup-tasks = ["clean"]
iterations = 5
daemon = none
}
Gradle Properties
Я постарался не включать настройки, которые бы сильно влияли на погрешность, хоть и ускоряли бы время сборки.
Начнём с настроек, которые не будут меняться:
org.gradle.daemon=false org.gradle.caching=false org.gradle.configureondemand=false kotlin.daemon.jvm.options=-Xmx4g kotlin.incremental=true kapt.use.worker.api=true kapt.incremental.apt=true kapt.include.compile.classpath=false
Собственно, это флаги отключения демона, кэшей и включения инкрементальной сборки для лучшей параллельности. Ничего особо интересного.
Поэтому посмотрим на те настройки, что будут менятся:
org.gradle.jvmargs=-Xmx24g -XX:+UseParallelGC org.gradle.workers.max=12
Начнём с org.gradle.jvmargs.
-XX:+UseParallelGC неплохо ускоряет время работы GC. Всё, что он делает, это включает параллельный GC. Делает он это стабильно, так что он, по сути, тоже постоянный.
А вот -Xmx24g уже нет. Это количество оперативной памяти, которое мы выделяем куче для сборщика Gradle.
А почему не выдать ему всю доступную оперативную память и не париться? Не стоит забывать, что сама операционка жрёт оперативу, как беременная лошадь. Плюс у сборщика Gradle есть не только куча, но и стек. Он так-то тоже место занимает. Так ещё и компилятор Kotlin отжирает немножко. И при выставлении слишком большого значения сборка, наоборот, сильно замедлится, так как начнёт использоваться swap.
Экспериментально-эмпирическим методом выяснено, что наш проект не собирается с -Xmx4g. Собирается при -Xmx5g, но много времени тратится на GC. Ну а при -Xmx6g он вообще «сладкая булочка» работает стабильно и быстро. Поэтому минимально приемлемым является именно 6 Гб.
Идеальным для тестов вариантом стала сложнейшая формула: «общее количество оперативы» минус 8 Гб. Которые как раз и уйдут на ОС, stack и т.п. Так как в тестах мы будем использовать либо 16 Гб, либо 32 Гб, то это параметр будет либо -Xmx8g либо -Xmx24g соответственно.
Напоследок про org.gradle.workers.max. С ним всё просто. Это количество Gradle Worker, которые будет использовать Gradle. Выставлять будем по принципу: количество Gradle Worker равно количеству потоков процессора.
Это количество Gradle Worker, которые будет использовать Gradle. Выставлять будем по принципу: количество Gradle Worker равно количеству потоков процессора.
Что измеряем?
А что же мы в итоге будем измерять? Я долго думал, как можно поиздеваться над компьютером, и в голову мне пришли следующие варианты:
частота ядер CPU;
количество ядер/потоков CPU;
количество оперативной памяти;
частота оперативной памяти;
скорость чтения/записи постоянной памяти.
По итогу мы увидим общее время сборки, а также время её составляющих:
время конфигурации;
время clean, для холодных сборок;
время, которое затрачивает GC на очистку памяти во время сборки;
время самой сборки.
Пример
Ну и чтобы потом не путаться, взглянем на пример результатов теста.
Слева перечислены варианты теста. В самом верху — цветовая легенда, чтобы не запутаться. Справа — общее время сборки для варианта. По центру — timeline варианта. Он разбит по цветам, соответствующим легенде. И тут же рядом — количество процентов, на которое сборка стала собираться быстрее относительно первого варианта.
Справа — общее время сборки для варианта. По центру — timeline варианта. Он разбит по цветам, соответствующим легенде. И тут же рядом — количество процентов, на которое сборка стала собираться быстрее относительно первого варианта.
Приступим, наконец, к тестам.
Частота ядер
Тут всё просто. В BIOS убираем Turbo Boost и фиксируем частоту процессора. У нас будет: 3000 МГц в качестве минимума, 3600 МГц, что на 20% больше минимума, и 4200 МГц, что аж на 40% больше минимума.
Посмотрим на результаты:
И мы получаем +14.2% на 3600 МГц и +23.7% на 4200 МГц. Результат очень даже значительный.
Видно, что в холодной сборке большую часть времени занимает build (кто бы мог подумать). Следом по времени идёт GC. Затем конфигурация. И в самом конце плетётся clean.
Прирост от наращивания частоты большой, но можно заметить, что при переходе с 3000 МГц на 3600 МГц (прирост на 20%) мы ускорились на 14.2%. А вот при переходе с 3000 МГц на 4200 МГц (прирост на 40%) мы ускорились лишь на 23. 7%. То есть зависимость частоты от скорости сборки нелинейная.
7%. То есть зависимость частоты от скорости сборки нелинейная.
+15.7% на 3600 МГц и +25.8% на 4200 МГц. Прирост даже выше, чем в многомодульном варианте.
Но сразу бросается в глаза, что «типа одномодульная» сборка в абсолютных цифрах медленней в три с половиной раза. Применяя сложные технологии интерполяции и экстраполяции запатентованным алгоритмом «Пальцем в небо», мы можем предположить, что одномодульная сборка медленней где-то втрое. Разница колоссальная. Но в то же время…
Может возникнуть вопрос: «А почему не в 12 раз? Мы использовали для одномодульной сборки 1 Worker, а для многомодульной — 12. «Где мой прирост в 1200% Лебовски?». Всё дело в том, что Gradle довольно умненький, и его Tasks хорошо параллелятся. Даже при одном Worker он занимает все 12 потоков процессора. Пусть и всего на 30-40%. Поэтому вся суть ускорения сборки от многомодульности раскрывается в горячей сборке. К слову о ней.
+17.9% на 3600 МГц и +24.7% на 4200 МГц. Моё почтение. В абсолютных цифрах это в 40 раз быстрее одномодульной холодной.
Сразу о слоне в комнате показателях теста: конфигурация занимает почти половину времени. Сама сборка 40% и 15% отбирает GC. Поэтому Configuration Cache и флаг
org.gradle.configureondemand=true
так важны в горячих сборках.
Выводы
Разница между 3Ггц и 4.2 Ггц — 25% при приросте частоты на 40%. Прирост нелинейный.
Холодная многомодульная сборка быстрее одномодульной не в 12 раз, а в 3 раза. Если вы думали иначе, то передумайте. Вся скорость многомодульности в горячих сборках.
Горячая сборка очень любит Configuration Cache.
Количество ядер
В BIOS возвращаем Turbo Boost и ставим частоту на Auto (на удивление, это почти не влияет на погрешность). Вместо этого балуемся с количеством физических ядер, выбирая между четырьмя и шестью. Так как у нас есть SMT (аналог Hyper-Threading от Intel) который на каждое физическое ядро создаёт два логических потока, то и число потоков у нас варьируется от 8 до 12. То есть увеличивается на 50%.
То есть увеличивается на 50%.
Прирост, конечно, меньше, чем в случае с частотой. Но тоже очень хороший. Правда есть один нюанс… В данном случае сильно важно, насколько хорошо у вас всё разнесено на модули. Так как время сборки каждого отдельного модуля может отличаться. Есть модули, от которых зависит много других модулей, и если они имеют большой размер, либо большое количество кодогенерации, то прирост будет небольшим. Так как часть Gradle Worker будут простаивать в ожидании, когда же соберётся такой модуль. Создавая «бутылочное горлышко». Да и базовые модули никто не отменял. Для примера давайте взглянем, как соберётся проект на трёх Gradle Worker.
И тот же проект на шести Gradle Worker.
Итоговое время, безусловно, уменьшилось. В то же время количество и размеры простоев увеличились. В итоге, чем больше Gradle Worker и ядер, тем сильно меньше пользы приносит каждый из них. Поэтому чем меньше в вашем проекте таких блокирующих модулей, тем больший эффект вам даст прирост количества ядер.
Напомню, что у нас больше 400 модулей и прям огромных монолитов нет. А прирост всего навсего 19.3%.
Ожидаемо, что прирост в одномодульной сборке от количества ядер сильно меньше, чем для многомодульной, всего около пяти процентов. При увеличении числа ядер на 50% я напомню. Всё логично, так как меньше параллельных задач. Небольшой прирост опять же есть из-за того, что Gradle молодчина и пытается параллелить задачи даже в одномодульном режиме.
В горячей сборке тоже прирост не такой большой, как в холодной. Так как параллелить тоже особо нечего. Мы ведь изменили только один модуль. Есть, конечно, Gradle Task, которые не зависят друг от друга, и их можно выполнить параллельно, но, как мы видим, их не слишком много.
Также хорошо видно, что время GC существенно уменьшилось, и основной прирост в скорости именно от этого. У нас включён параллельный GC. И что логично, чем больше у параллельного GC есть потоков, тем лучше.
Выводы
Количество ядер сильно влияет только в многомодульной сборке.
Чем лучше распараллелен проект, тем больший прирост.
Слишком много ядер для сборки не нужно. Лучше вложится в частоту, там прирост будет выше.
Непонятный факт
Можно заметить, что сборка с частотой, выставленной в Auto режиме, в котором частоты должны доходить до 4200 МГц, собиралась 10:32, но когда мы руками выставляли 4200 МГц, то результат был 8:46. На деле результат в Auto режиме находится между 3000 МГц и 3600 МГц. Что как бы подозрительно.
Чтобы понять, в чём причина, я ещё раз прогнал тесты, и результат не поменялся.
Тогда я предположил, что, возможно, проблема в Turbo Boost, который выставляет слишком низкие частоты. Но прогон тестов с включенным мониторингом показал, что это не так. Частоты почти всегда были выше 4000 МГц.
Дополнительно проверил и в Doom 2016. Для полной надёжности результатов, наиграв несколько часов. Исключительно в научных целях, конечно же. В игре тоже с частотами всё было в порядке.
Самое занятное, что со временем я обновил процессор до Ryzen 7 5800X. У него тоже прослеживается подобное. На фиксированной частоте 4200 МГц результат получается лучше, чем в режиме Auto, в котором, судя по показаниям мониторинга, частоты доходят до 4700 МГц. Найти объяснение этому я так и не смог. Возможно, проблема в Turbo Boost, AMD, возможно, в Windows 11, в планировщике ядер, а может, и сам Gradle подлянки устраивает. Эта тема требует отдельного изучения.
У него тоже прослеживается подобное. На фиксированной частоте 4200 МГц результат получается лучше, чем в режиме Auto, в котором, судя по показаниям мониторинга, частоты доходят до 4700 МГц. Найти объяснение этому я так и не смог. Возможно, проблема в Turbo Boost, AMD, возможно, в Windows 11, в планировщике ядер, а может, и сам Gradle подлянки устраивает. Эта тема требует отдельного изучения.
Заканчиваем мучить процессор и переходим к памяти.
Количество памяти
Всё просто. Берём два комплекта памяти. На 16 Гб и на 32 Гб. Выставляем им одинаковые настройки: частоты, тайминги и напряжение. В моём случае это были два комплекта от одного производителя и из одной линейки. Поэтому ничего делать и не пришлось.
Прирост весьма хорош. В основном от уменьшения времени GC. В целом понятно, что из-за большего объёма оперативной памяти у GC меньше причин срабатывать. Время непосредственно же build тоже стало меньше, но совсем на чуть-чуть.
Для одномодульной сборки показатели не очень впечатляющие. Где-то на границе погрешности. По всей видимости из-за того, что сборка более последовательная. Столько оперативной памяти ей и не нужно.
Где-то на границе погрешности. По всей видимости из-за того, что сборка более последовательная. Столько оперативной памяти ей и не нужно.
В горячей сборке тоже особого прироста нет. При изменениях в одном модуле много оперативной памяти не нужно, так как количество кода, который надо скомпилировать, тоже не велико. Опять же, весь прирост от GC.
Выводы
На локальной машине 16 Гб пока достаточно для проектов, сопоставимых с нашим. Если вы, конечно, не любитель держать приложения и вкладки браузера вечно открытыми.
Одномодульному проекту вообще плевать.
На CI Gradle можно дать больше памяти, так как всяческие проверки дополнительно подъедают память.
Частота памяти
Для комплекта на 32 Гб выбираем 2400МГц, 3000 МГц, что на 25% больше, и 3600 МГц, что аж на 50% больше. И самое главное — обязательно фиксируем тайминги. И вы подумали «Что ещё за тайминги и зачем их обязательно фиксировать?».
Самое простое объяснение, которое я слышал, звучит примерно так: «Представьте что оперативная память — это набор шкафов с книгами. Когда оперативной памяти нужно обратиться к своей ячейке, это равнозначно тому, что вам надо достать книгу из шкафа. У вас есть номер шкафа (номер чипа памяти), номер полки (номер строки) и номер книги на полке (номер столбца).».
Когда оперативной памяти нужно обратиться к своей ячейке, это равнозначно тому, что вам надо достать книгу из шкафа. У вас есть номер шкафа (номер чипа памяти), номер полки (номер строки) и номер книги на полке (номер столбца).».
Чтобы прочитать какую-либо книгу, вам потребуется:
Подойти к шкафу.
Пододвинуть лестницу к нужной полке.
Взять книгу.
Вернуть лестницу в начальное положение.
Каждое из этих действий отнимает разное количество времени. Подойти к шкафу — 17 секунд, сдвинуть лестницу — 20 секунд, вернуть обратно лестницу — опять же 20 секунд. Ну и, собственно, найти книгу на полке — 42 секунды.
В итоге ваш тайминг 17-20-20-42.
Также и в оперативной памяти. Только компьютер оперирует не секундами, а тактами. Вот тут в дело и вступает частота. Частота — это количество тактов в секунду.
И вот тут начинается интересное. Если тайминг не зафиксирован, то материнская плата сама его выбирает. Зачастую с запасом. И когда мы подняли частоту, то может выбрать, например, не 15, а 16.
Зачастую с запасом. И когда мы подняли частоту, то может выбрать, например, не 15, а 16.
В итоге, просто подняв частоту, мы не увидим существенного прироста.
Ведь 15/3000МГц = 16/3200МГц = 5 наносекунд.
Поэтому обязательно фиксируем их.
В итоге фиксируем тайминги на 20-20-20-42, и сабтайминги на то значение, при котором модули нормально работают на частоте 3600 МГц. Ну и дальше уменьшаем частоту до 3000 МГц и далее до 2400 МГц.
Пропускная способность памяти получилась следующей (медианное из 5-ти прогонов):
2400 МГц. Чтение 25586 MB/s. Запись 20170 MB/s.
3000 МГц. Чтение 36587 MB/s. Запись 25885 MB/s.
3600 МГц. Чтение 42427 MB/s. Запись 31510 MB/s.
Ну-у-у. Честно говоря, результата то почти и нет. Видимо, Gradle не так сильно важна скорость памяти. Так как «голода памяти» не наступает, и процессор всегда занят делом. Я бы списал это на погрешность, но результат стабильный. Могу предположить, что для процессоров с большим количеством ядер частота памяти будет иметь чуть большее значение.
Опять же небольшой прирост. Ничего интересного.
В процентах это, конечно, неплохо, но в абсолютных значениях — около 5 секунд, что опять же не впечатляет.
Выводы
Наверное, самый разочаровывающий тест. Не знаю почему, но я ожидал гораздо-гораздо большего. Ведь в тех же играх за счёт частоты оперативной памяти удалось получить до 15% прироста.
В целом можно понять две вещи:
Скорость накопителя
Возвращаем частоты и тайминги на значения по умолчанию и начинаем тест. Возьмём все типы накопителей, что есть у меня дома:
HDD 2.5”. Даже не помню, откуда он у меня. Возможно, из старого ноутбука, а возможно, он и не мой.
HDD 3.5”. Использовался как файлопомойка.
Sata SSD. Купил ради тестов, а потом запихал в Playstation 2, чтобы меньше шумела. Вот такой вот я странный.
NVMe SSD. Основной мой накопитель.
RAM Storage. Специальный гость. Делал с помощью программы ImDisk.

Чуть подробнее про RAM Storage. По сути, мы выделяем в оперативной памяти область, к которой мы будем обращаться как к накопителю. В теории оперативная память сильно быстрее, чем любой накопитель.
Ну и сравнительная таблица скоростей (всё в Мб/с):
Sequence Read | Random Read | Sequence Write | Random Write | |
HDD 2.5” | 80.845 | 0.629 | 67.491 | 0.727 |
HDD 3.5” | 155.733 | 1.614 | 142.615 | 1.619 |
Sata SSD | 446.519 | 163.999 | 353.164 | 126. |
NVMe SSD | 3567.495 | 1542.787 | 2325.665 | 1577.327 |
RAM Storage | 7841.693 | 1056.208 | 12537.931 | 658.770 |
 276
276Как мы видим, на деле всё чуть сложнее… Сначала от накопителя к накопителю скорость только растёт, но на RAM Storage вся логика ломается.
Скорость последовательного чтения ниже, чем скорость записи, а случайное чтение и запись медленнее, чем на NVMe SSD. Это связано как с самой эмуляцией, так и с файловой системой. К тому же работа с оперативной памятью ведётся постоянно. Из-за этого, пока процессору будут нужны какие-либо данные из оперативной памяти, наш RAM Storage будет подтормаживать.
Дальше всё просто. Запускаем ОС не с того накопителя, на котором находится проект. Не забывая при этом добавить папки с проектом в исключения индексатора и антивируса, как это рекомендует Google.
Не забывая при этом добавить папки с проектом в исключения индексатора и антивируса, как это рекомендует Google. Иначе придётся делать тест заново, так как результаты будут непонятными.
Погнали.
Похоже, что для холодной сборки многомодульных проектов использовать HDD категорически нельзя. Видимо, слишком большой объём данных нужно получить с накопителя. Так ещё и при сборке записываются сотни и тысячи мелких файлов, с которыми у HDD не очень. В итоге вся сборка упирается в него. Таким образом, HDD становится бутылочным горлышком. А вот разница между Sata SSD, NVMe SSD и RAM Storage не столь драматичная. Да, прирост есть, но не такой большой.
Разница между NVMe и RAM Storage — 22 секунды. Неплохо, но учитываем разницу в стоимости за 1 Гб… Да и разница в тестах оперативной памяти между 16 Гб и 32 Гб была в районе 30 секунд. Так что лучше пустить оперативу по прямому назначению.
Холодная одномодульная сборка меньше выигрывает от замены накопителя, но опять же от Sata SSD прирост прям хороший. Дальше прирост уже не такой заметный.
Дальше прирост уже не такой заметный.
Для горячей сборки от смены накопителя не меняется ничего. По всей видимости, слишком малый объём данных считывается и записывается, чтобы скорость накопителя начала как-то влиять. Все результаты в рамках погрешности.
Выводы
HDD пока! Похоже, тесты показывают, что HDD в 2022 году лучше уже не использовать. Вместо него стоит взять SSD. Слишком уж много потенциальных плюсов он даёт.
Достаточно и обычного SSD. Относительно него от NVMe прирост не слишком большой, но и по цене они почти равны. Так что, всё решает наличие NVMe M2 слота.
RAM Storage для сборок — ненужный шик.
Самый-самый последний тест
Напоследок давайте попробуем сравнить наши результаты с результатами на Apple silicon.
К сожалению, я не настолько богат, чтобы сравнивать M2 с каким-нибудь Intel 12900K. Но я могу сравнить то железо, к которому у меня есть доступ.
Поэтому сравним:
Мой домашний комп на Ryzen 3600 c 32 Гб RAM.
MacBook Pro на M1 с 16 Гб RAM.
MacBook Pro на M1 Pro с 32 Гб RAM.

Как минимум мы поймём, как себя ведёт Apple silicon в разных видах сборки по сравнению с обычным домашним компьютером.
В данном виде сборки очень решает именно многопоточная производительность. Тут M1 немного проигрывает обычному компьютеру. А вот M1 Pro прямо разрывает всех напрочь. Напомню, что мы сравниваем, по сути, процессор в ноутбуке с десктопным вариантом.
M1 Pro так оторвался от обычного M1 за счёт того, что у него в два раза больше производительных ядер.
И мой любимый компьютер остаётся позади обычного M1… Зато он умеет запускать любые игры. Шах и мат Apple silicon. M1 таким похвастаться не может.
А если серьёзно, то в данном виде сборки производительность на 1 ядро является ключевым фактором. Ну и, как видно по тестам, у Apple silicon с этим всё прекрасно. При этом разница между M1 и M1 Pro — в районе погрешности. Что и логично, так как в M1 Pro просто больше производительных ядер. При этом они такие же, как и в обычном M1.
При этом они такие же, как и в обычном M1.
И опять Apple silicon быстрее. Вдвое. Сюда бы ещё Configuration Cache докинуть, вообще сказка будет.
Конечно, по итогу вопрос в стоимости. Но если у вас есть куча денег или лишняя почка, может, даже не своя, то выглядит так, что Apple среди рабочих ноутбуков впереди планеты всей. Так как не стоит забывать, что у него ещё и энергоэффективность на высоте.
Субъективное мнение
Вообще, выводы вы можете сделать самостоятельно. Все цифры в статье. Касаемо того, что думаю по поводу этого я…
Я был немного разочарован. Что 8 лет назад, когда я начинал карьеру, что сейчас — основным параметром является частота. Да, количество потоков тоже важно, но оно так и не стало решающим фактором.
Давайте подумаем, на что обратить внимание при сборке ПК.
В целом такая сильная зависимость от частоты ставит под сомнение сборку на ноутбуках без хорошего охлаждения, а таких большинство. Так как из-за нагрева процессор начнёт тротлить, сбрасывая частоты Turbo Boost. Если хотите использовать ноутбук — возможно стоит посмотреть в сторону Mainframer Ну, либо можно использовать технику на Apple silicon. Она очень хорошо показывают себя в сборке проектов. Но тут и бюджеты другие.
Если хотите использовать ноутбук — возможно стоит посмотреть в сторону Mainframer Ну, либо можно использовать технику на Apple silicon. Она очень хорошо показывают себя в сборке проектов. Но тут и бюджеты другие.
Самые топовые процессоры вроде Ryzen 7950X с его 32 потоками станут нужны, только если у вас проект очень хорошо разбит на модули и вам действительно есть чем их загрузить. В целом же — середнячки и чуть выше — наше всё.
Не стоит, конечно, забывать и поколения процессора. Какой-нибудь Ryzen 5 1600 будет сильно отставать от Ryzen 5 5600 на той же частоте. К сожалению, провести такие тесты, не имея у себя зоопарк из процессоров и материнских плат, нельзя. Так что извиняйте.
Касаемо CI, тут точно надо отказываться от HDD, если они у вас остались. Ну и если будет выбор между процессором с большой частотой и процессором с большим количеством ядер, то, думаю, лучше посмотреть в сторону более частотного процессора.
Если у вас есть идеи, что же можно ещё протестировать в конфигурации компьютера, то смело предлагайте в комментариях.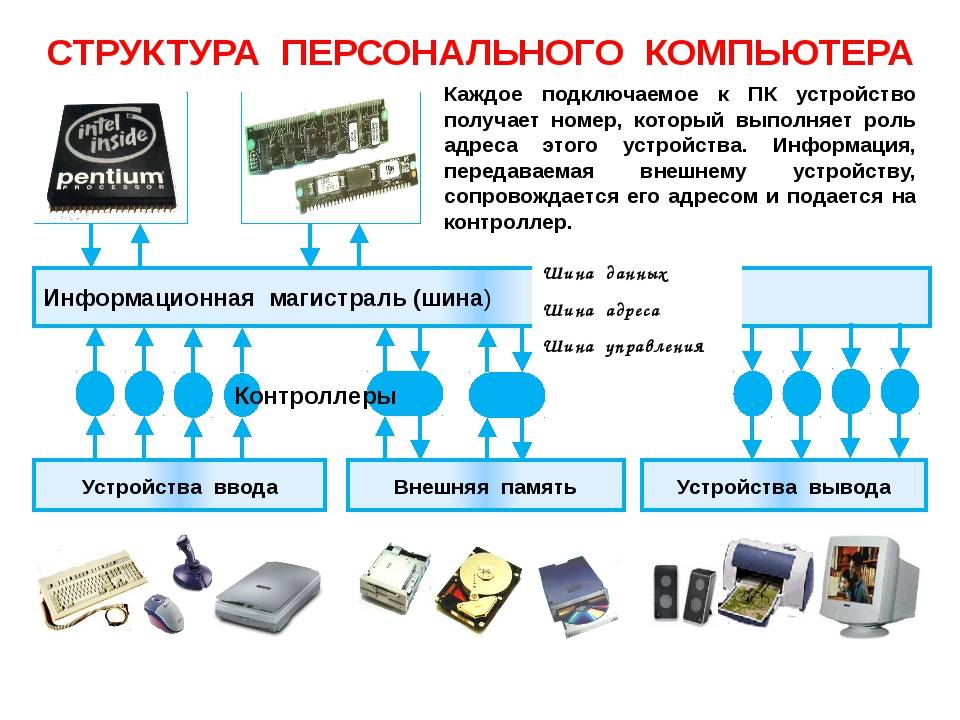
Что такое данные?
Обновлено: 18.11.2022 автором Computer Hope
В общем, данные — это любой набор символов, который собирается и транслируется для какой-либо цели, обычно для анализа. Если данные не помещаются в контекст, они ничего не делают с человеком или компьютером.
Существует несколько типов данных. Некоторые более распространенные типы данных включают следующее:
- Односимвольный
- Логическое значение (истина или ложь)
- Текст (строка)
- Число (целое или с плавающей запятой)
- Изображение
- Звук
- Видео
В памяти компьютера цифровые данные представляют собой последовательность битов (двоичных цифр) со значением, равным единице или нулю. Данные обрабатываются центральным процессором, который использует логические операции для создания новых данных (выходных) из исходных данных (входных).
- Примеры компьютерных данных.
- Кто создает данные?
- Как данные хранятся на компьютере?
- Мобильные данные.
- Грамматическое употребление.
- Как вы произносите данные?
- Связанная информация.

Примеры компьютерных данных
Джо, Смит, 1234 Circle, SLC, UT, 8404,8015553211
0143 0157 0155 0160 0165 0164 0145 0162 0040 0150 0157 0160 0145
011000110110111101101101011100000111010101110100011001010111001000100000010000001101000000101
Кто создает данные?
Данные могут быть созданы на компьютере пользователем, программным обеспечением или оборудованием, подключенным к компьютеру. В случае пользователя данные вводятся с использованием устройства ввода, такого как клавиатура. С помощью программного обеспечения программа может создавать данные от пользователей, взаимодействующих с программой, или из другого источника ввода (например, инициированное оповещение). Наконец, аппаратное обеспечение также может создавать данные из предупреждения, полученного датчиком или другим входом.
Как данные хранятся на компьютере?
Данные и информация хранятся на компьютере с использованием жесткого диска или другого запоминающего устройства.
Мобильные данные
Для смартфонов и других мобильных устройств данные описывают любые данные, передаваемые устройством через Интернет по беспроводной сети. См. определение нашего тарифного плана для получения дополнительной информации.
- Сколько данных я использую на своем смартфоне?
Грамматическое употребление
Слово «данные» технически является существительным во множественном числе, например, «данные обрабатываются». Форма данных в единственном числе datum , от латинского слова, означающего «что-то данное».
Хотя использование данных в качестве существительного во множественном числе является технически правильным, в современном использовании данные также принимаются как существительное в единственном числе, например, «Данные обрабатываются».
Как вы произносите данные?
Произношение слова «данные» может варьироваться в зависимости от части мира человека, произносящего это слово. Во всем мире это произносится как дай-та, дат-та, дах-та или дар-та. В Америке это обычно произносится как дай-та и дат-та.
В Америке это обычно произносится как дай-та и дат-та.
Поскольку произношение данных зависит от региона, все более ранние произношения считаются правильными. Тем не менее, мы рекомендуем использовать произношение, используемое в вашем районе проживания.
- В чем разница между данными и информацией?
- Как компьютер преобразует данные в информацию?
Термины искусственного интеллекта, калибровка, данные, сбор данных, термины базы данных, манипулирование данными, извлечение данных, обработка данных, восстановление данных, информация, инструкции, массаж, необработанные данные, санированные данные, исходные данные, термины электронной таблицы
Интервью с COMPUTER DATA
Бретт Хендерсон, он же COMPUTER DATA, исполнитель электронной музыки и владелец Pure Bread Records из Сан-Франциско. COMPUTER DATA, пожалуй, наиболее известен своей эмоционально заряженной, теплой и не угрожающей дискографией хаус-музыки, которая совсем недавно попала на британский лейбл Shall Not Fade с EP под названием «Ego». Как ди-джей, COMPUTER DATA является местным игроком на сцене Сан-Франциско и начал строить свое имя в более глобальном масштабе до того, как разразилась пандемия, выступая вместе с такими, как Chaos In The CBD и Kornél Kovács в начале год Noise Pop Festival; а также Крис Лейк и Патрик Топпинг для фестиваля CRSSD в марте. Бретт нашел время, чтобы поговорить с нами после нескольких бурных месяцев, когда он смотрит на горизонт для себя и своего звука в 2021 году.
Как ди-джей, COMPUTER DATA является местным игроком на сцене Сан-Франциско и начал строить свое имя в более глобальном масштабе до того, как разразилась пандемия, выступая вместе с такими, как Chaos In The CBD и Kornél Kovács в начале год Noise Pop Festival; а также Крис Лейк и Патрик Топпинг для фестиваля CRSSD в марте. Бретт нашел время, чтобы поговорить с нами после нескольких бурных месяцев, когда он смотрит на горизонт для себя и своего звука в 2021 году.
С тех пор, как все это началось, здесь, в США, и особенно в Калифорнии, все стало только хуже. Это по-прежнему сильно тормозило мою креативность и продуктивность. В августе я начал возвращаться к нормальной жизни, а потом здесь, в Калифорнии, случились огромные лесные пожары. Постоянный дым действительно портит мою астму, и довольно удручающе наблюдать за всем этим опустошением, происходящим в сообществах, в которых я вырос. В прошлом месяце я взял дорожный велосипед и начал кататься с друзьями, это упражнение определенно помогает мне немного очистить голову, но мы постоянно смотрим на карты AQI, чтобы увидеть, когда действительно безопасно выходить на улицу.
Постоянный дым действительно портит мою астму, и довольно удручающе наблюдать за всем этим опустошением, происходящим в сообществах, в которых я вырос. В прошлом месяце я взял дорожный велосипед и начал кататься с друзьями, это упражнение определенно помогает мне немного очистить голову, но мы постоянно смотрим на карты AQI, чтобы увидеть, когда действительно безопасно выходить на улицу.
Когда я пишу это сегодня (28 сентября), за последние 24 часа в округе Сонома, к северу от района залива, начался сильный лесной пожар. Это район, в котором я жил несколько лет назад и который очень близок моему сердцу. Невероятно грустно видеть, как это опустошение снова происходит с сообществом, которое было уничтожено еще в 2017 году во время пожара в Таббсе. Сейчас у меня определенно не все в порядке, и в эти дни трудно сохранять надежду на будущее из-за отсутствия реакции на COVID-19 на национальном уровне и уровне штата здесь, в США.
 soundcloud.com/player/?url=https%3A//api.soundcloud.com/tracks/851517556&color=%23ff5500&auto_play=false&hide_related=false&show_comments=true&show_user=true&show_reposts=false&show_teaser=true»/>
soundcloud.com/player/?url=https%3A//api.soundcloud.com/tracks/851517556&color=%23ff5500&auto_play=false&hide_related=false&show_comments=true&show_user=true&show_reposts=false&show_teaser=true»/> Shall Not Fade · SNF Mix 007 // Компьютерные данные
Я хотел бы знать, как началось ваше музыкальное путешествие и как вы нашли способ создавать музыку, которую делаете сегодня? Мой творческий путь в музыке начался примерно в 2014 году. Я был первокурсником в университете, когда мне поставили диагноз эозинофильный гранулематоз с полиангиитом (EGPA/Churg-Strauss), редкое аутоиммунное заболевание, вызывающее хаос на моем теле. Я взял годичный отпуск в университете, чтобы пройти курс лечения, и в конце концов смог достичь ремиссии. В этот период у меня было много свободного времени, и я действительно изо всех сил пытался справиться со своей болезнью. У меня не было много способов выразить себя словами, и я действительно не знал, как это сделать, поэтому я начал учить себя Ableton каждую ночь в надежде избавиться от звуков в моей голове.
У меня не было много способов выразить себя словами, и я действительно не знал, как это сделать, поэтому я начал учить себя Ableton каждую ночь в надежде избавиться от звуков в моей голове.
Моя музыка всегда была своего рода чистым эмоциональным выходом и средством самовыражения для меня. В детстве я играл на барабанах и всегда питал глубокую привязанность к сочной электронной музыке, особенно к синтезаторам. Я никогда не ожидал, что кому-то понравится то, что я делаю, и был поражен тем, что люди находили отклик в моей музыке. Мои ранние вещи были очень медленными, но со временем я как бы привык к своему «звучанию» и действительно наслаждался музыкой, более ориентированной на хаус/техно, которую я делал. Я полюбил то, что делаю, и понял, что это то, чему я хочу посвятить свою жизнь. То, как люди присылают мне искренние сообщения о моей музыке и о том, как она повлияла на них, действительно открыло для меня новую перспективу. Идея работать в технологической индустрии на каком-то душераздирающем концерте разработки программного обеспечения меня больше не привлекала. Мне не суждено прожить долгую жизнь, и смириться с этим означало, что я хочу оказать положительное влияние на то время, которое у меня есть здесь.
Мне не суждено прожить долгую жизнь, и смириться с этим означало, что я хочу оказать положительное влияние на то время, которое у меня есть здесь.
Что касается диджеинга, то я всегда был большим поклонником хауса и техно, но никогда не относился к этому серьезно, пока не закончил школу. У меня было собственное радиошоу в KUSF (Колледжное радио Университета Сан-Франциско), которое стало для меня отличной платформой для того, чтобы поделиться своей музыкой и улучшить свои навыки микширования. Как только я начал получать настоящие концерты, мое производство определенно сместилось в сторону создания более «дружественных для ди-джеев» треков. Для меня это всегда было скорее побочным хобби, которое превратилось в центр моей карьеры, и мне это очень нравится.
Как только я начал получать настоящий доход от музыки, я смог начать покупать оборудование и просто продолжал работать над расширением своего звучания. Я в значительной степени перестал писать музыку «в коробке» и переключился на аппаратную установку.
Музыка стала моей основной работой вот уже почти 2 года, это была невероятная борьба, но я продолжу.
Ваш последний EP « Ego » только что вышел на лейбле Shall Not Fade. Некоторые треки, которые там появляются, такие как «M-type» и «Parametric», возможно, более «глубокие» и «клубные» по сравнению с большинством ваших ранних релизов.Можете ли вы рассказать нам, что побудило вас написать более тяжелые треки для этого релиза?
Мое намерение с «Ego» определенно состояло в том, чтобы создать более ориентированный на клубы релиз, так как я часто чувствую себя странно, играя многие свои треки в клубной обстановке по сравнению с моими типичными диджейскими сетами. Многое из того, что было раньше, просто не работает на больших звуковых системах в такой среде, а в 2019 году я написал массу музыки, которая больше подходила для клубной обстановки, так что «Ego» было вырезано из этого огромного пространства. пул треков, которые я сделал в течение года. Мне нравится играть быстро и жестко, когда я диджей, есть что-то захватывающее в том, чтобы нагнетать энергию в толпе, и я хотел включить эту энергию в свои собственные постановки и использовать ее в своих сетах. Если быть честным, многие из моих «тяжелых» произведений обычно являются проявлением гнева или боли в той или иной форме, и отсюда берутся такие вещи, как «M-type».
пул треков, которые я сделал в течение года. Мне нравится играть быстро и жестко, когда я диджей, есть что-то захватывающее в том, чтобы нагнетать энергию в толпе, и я хотел включить эту энергию в свои собственные постановки и использовать ее в своих сетах. Если быть честным, многие из моих «тяжелых» произведений обычно являются проявлением гнева или боли в той или иной форме, и отсюда берутся такие вещи, как «M-type».
КОМПЬЮТЕРНЫЕ ДАННЫЕ · Ego EP [PALMS033]
Каким, по вашему мнению, вы видите будущее сцены в вашем городе Сан-Франциско или, тем более, мировой сцены в целом?Усилит ли выход из этой пандемии сцену или она уже пострадала?
Я не могу сказать много положительного о текущей сцене здесь, в Сан-Франциско/районе залива, я думаю, что большая часть жизни и души, которая когда-то была, уже угасла к тому времени, когда я смог принять участие в ней. это, даже до COVID-19. НФ страдает от наличия небольшого сообщества художников, которые по-настоящему увлечены своей работой, и они часто не могут позволить себе выжить в НФ, и их постоянно затмевают промоутеры, привносящие мейнстримную сцену, апеллирующую к культуре «технарей», в которой доминируют последние 10 лет или около того здесь. Я отчаянно надеюсь, что андеграундная сцена здесь выживет, но я не думаю, что COVID-19 действительно внесет какие-то изменения, когда индустрия возобновится. У нас есть много промоутеров и владельцев, которые не заботятся о поддержке местных талантов или укрытии местной сцены, и пока эти чуваки не уйдут, я не думаю, что это изменится.
это, даже до COVID-19. НФ страдает от наличия небольшого сообщества художников, которые по-настоящему увлечены своей работой, и они часто не могут позволить себе выжить в НФ, и их постоянно затмевают промоутеры, привносящие мейнстримную сцену, апеллирующую к культуре «технарей», в которой доминируют последние 10 лет или около того здесь. Я отчаянно надеюсь, что андеграундная сцена здесь выживет, но я не думаю, что COVID-19 действительно внесет какие-то изменения, когда индустрия возобновится. У нас есть много промоутеров и владельцев, которые не заботятся о поддержке местных талантов или укрытии местной сцены, и пока эти чуваки не уйдут, я не думаю, что это изменится.
В глобальной перспективе я надеюсь, что музыкальная индустрия претерпит серьезные изменения, и вся навязчивая идея «инстаграм-диджеев» утихнет. Я бы хотел, чтобы люди, которые на самом деле больше заботятся о своей музыке, чем о своем профиле в Instagram, добились успеха, но вряд ли это изменится в ближайшее время. Невероятно неприятно видеть, как ди-джеи из мультимиллионерских трастовых фондов продолжают играть опасные и эгоистичные «чумные рейвы» по всему миру прямо сейчас, когда большинство из нас в «андеграунде» изо всех сил пытаются выжить. Если бы никто не присутствовал на них, я бы сказал, что сцена улучшается, но это не так, и трудно увидеть какие-либо признаки или реальные значимые изменения.
Невероятно неприятно видеть, как ди-джеи из мультимиллионерских трастовых фондов продолжают играть опасные и эгоистичные «чумные рейвы» по всему миру прямо сейчас, когда большинство из нас в «андеграунде» изо всех сил пытаются выжить. Если бы никто не присутствовал на них, я бы сказал, что сцена улучшается, но это не так, и трудно увидеть какие-либо признаки или реальные значимые изменения.
Считаете ли вы, что ваша музыка все еще резонирует с идеей о том, что это низкокачественная хаус-музыка, или этот термин утратил часть своей ценности?
Я всегда думал, что термин «Lo-Fi House» является широким многожанровым охватывающим дескриптором, который значительно потерял свое значение с годами. Большинство людей, которые были в авангарде сцены «Lo-Fi House», развили свое звучание далеко от того, как оно изначально определялось. Я думаю, что лоу-фай-хаус совпал с возрождением использования аналогового оборудования для создания электронной музыки и превратился в этот общий термин для описания огромного количества продюсеров/стилей, которые вписываются в такого рода коробку с «сырым звуком». Я не думаю, что правильно приравнивать такой трек, как «параметрический», к «исцеляющему», так как мой продакшн определенно стал немного более хай-файным. Я бы не назвал то, что я выпустил в этом году, «лоу-фай хаус», но я не думаю, что оно сильно отклоняется от моего звучания несколько лет назад, может быть, это более утонченная грязь.
Я думаю, что лоу-фай-хаус совпал с возрождением использования аналогового оборудования для создания электронной музыки и превратился в этот общий термин для описания огромного количества продюсеров/стилей, которые вписываются в такого рода коробку с «сырым звуком». Я не думаю, что правильно приравнивать такой трек, как «параметрический», к «исцеляющему», так как мой продакшн определенно стал немного более хай-файным. Я бы не назвал то, что я выпустил в этом году, «лоу-фай хаус», но я не думаю, что оно сильно отклоняется от моего звучания несколько лет назад, может быть, это более утонченная грязь.
Есть ли какие-то конкретные австралийские исполнители, которые привлекли ваше внимание или являются вашими любимыми?
Я всегда любил Mall Grab, DJ Boring и Subjoi. Они уже некоторое время занимаются своим делом и всегда убивают его. В прошлом году я был очень популярен у Лу Карша/Reptant, невероятного кислотного продюсера из Мельбурна. У вас, ребята, есть отличные таланты, такие ди-джеи, как Дженнифер Лавлесс, уже некоторое время находятся на моем радаре.
Они уже некоторое время занимаются своим делом и всегда убивают его. В прошлом году я был очень популярен у Лу Карша/Reptant, невероятного кислотного продюсера из Мельбурна. У вас, ребята, есть отличные таланты, такие ди-джеи, как Дженнифер Лавлесс, уже некоторое время находятся на моем радаре.
16 октября у меня вышел ремикс на трек моего друга Monolithic – «Mercury Vapor», а в ноябре — сингл на юбилейном LP Shall Not Fade! Я работаю над некоторыми дополнительными ремиксами, которые также выйдут позже в этом году.
Я начал работу над своим дебютным LP несколько месяцев назад, посмотрим, удастся ли мне закончить его до конца года. Кроме этого, я надеюсь вернуться к стримингу некоторых продакшенов и диджейских сетов.
Наконец, пандемия закончилась, это ваш первый сет, и вы играете сет на рассвете.
Ваш комментарий будет первым