Как открыть xml в ворде
Для просмотра файла XML встроенными в систему средствами можно воспользоваться любым доступным текстовым редактором (например, «Блокнотом»). Кликните правой клавишей мыши на документе, а в появившемся контекстном меню выберите строчку «Открыть с помощью» – «Блокнот». Данный способ просмотра отличается тем, что перед вами откроется содержимое XML со всеми тегами и указанными параметрами. В «Блокноте» вы сможете отредактировать нужный код и сохранить его в тот же первоначальный файл.
Просмотр в качестве таблицы стилей
Если вы хотите просмотреть файл XML как таблицу стилей и готовый к отображению документ, воспользуйтесь приложением Microsoft Excel, которое позволяет отобразить нужный файл в виде таблицы с заданными в коде атрибутами. Чтобы открыть XML в Excel, кликните правой кнопкой мыши на файле, а затем перейдите в «Открыть с помощью» – Microsoft Excel. Недостатком использования данного способа открытия файла XML является невозможность его отображения при превышении лимита строк в настройках программы.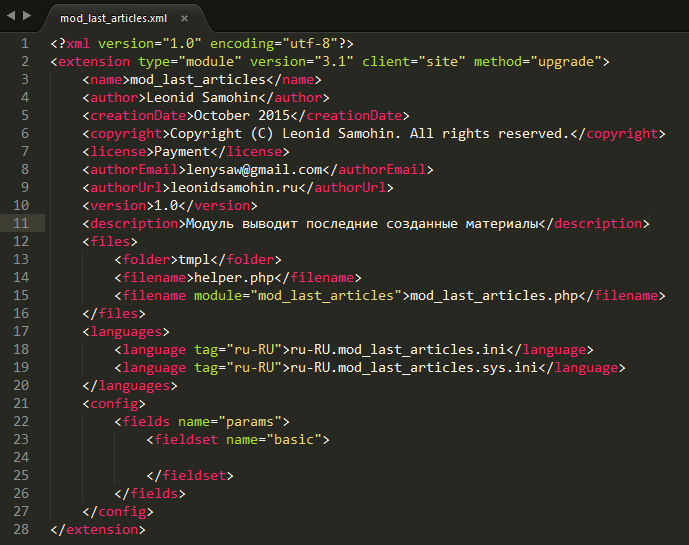
Просмотр файла XML в браузере также позволяет получить отображение документа и его кода. Практически любая версия современного браузера (Internet Explorer, Firefox, Opera, Safari, Chrome) поддерживает отображение файлов XML. Чтобы осуществить просмотр документа, вызовите контекстное меню «Открыть с помощью». Перед вами откроется вкладка браузера, в которой вы увидите нужную информацию или код.
Альтернативные редакторы
Для редактирования XML-кода вы можете воспользоваться программой Notepad++. Ее отличительной особенностью является реализация поддержки подсветки кода. Программа выделит используемые теги цветом. Если вы пропустите, например, закрывающий дескриптор, программа выделит нужный кусок кода и вы сможете его заметить и отредактировать. Альтернативой Notepad++ можно отметить AkelPAD, представляющий аналогичный набор инструментов для работы с языками разметки.
Просмотр XML в других системах
В операционных системах Linux и Mac OS программа также может быть открыта при помощи любого текстового редактора. Libre Office Calc является аналогом программы Excel, а потому также способен отображать строки из документа в своем окне. Что касается Mac OS, вы можете воспользоваться как Libre Office, так и Excel в версии для данной операционной системы. Как и в остальных системах Mac OS поддерживает открытие XML при помощи текстовых редакторов.
Libre Office Calc является аналогом программы Excel, а потому также способен отображать строки из документа в своем окне. Что касается Mac OS, вы можете воспользоваться как Libre Office, так и Excel в версии для данной операционной системы. Как и в остальных системах Mac OS поддерживает открытие XML при помощи текстовых редакторов.
Несомненно, рано или поздно пользователи сталкиваются с разновидностью файлов, имеющих расширение.xml. Не все, правда, четко себе представляют, что это такое и Попробуем разобраться в основных вопросах, ответы на которые и дадут понимание структуры файла и возможности его открытия.
Начнем с азов, ведь без понимания того, что именно представляет собой XML-файл, невозможно будет осуществить выбор программы для его открытия или редактирования.
Вообще, расширение.xml соответствует универсальному типу документов, созданных при помощи специального расширяемого языка разметки, который несколько напоминает инструменты известного языка HTML с той лишь разницей, что в таком документе свойства объекта или его описание определяются атрибутами и тегами, задаваемыми вручную.
Встретить XML-файлы сегодня можно где угодно. Это могут быть единые базы данных, специализированные списки настроек программ и приложений или даже целые веб-страницы. Кроме того, такие файлы применяются для создания, например, кино- или музыкальных каталогов. При этом, скажем, каждому фильму соответствует один файл, в котором содержатся атрибуты, указывающие на жанр, год выпуска, киностудию, имя режиссера и вообще – на любую информацию, касающуюся данной картины. В описании ограничений нет.
Кроме того, прежде чем решать, чем можно открыть XML-файл, следует заметить, что этот стандарт был разработан в качестве универсального для получения возможности обмена данными между программами. Иными словами, сегодня нет единого для всех случаев приложения, которое открывало бы такой файл по двойному клику.
простейшее решение
Как уже понятно, стандартный метод открытия может ни к чему и не привести. Связано это только с тем, что на компьютере может быть установлено несколько программ, способных это сделать.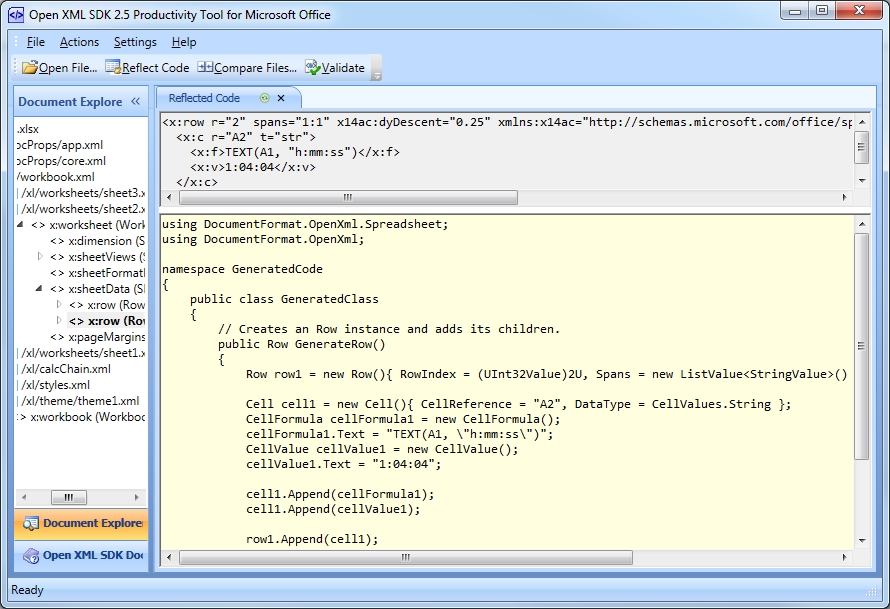 В лучшем случае система предложит выбрать наиболее подходящее приложение, предоставив пользователю список программ на выбор.
В лучшем случае система предложит выбрать наиболее подходящее приложение, предоставив пользователю список программ на выбор.
С Интернетом все понятно. На сайте этих файлов не видно, и апплет, открывающий их, работает в фоновом режиме, который пользователь не видит. Что же до вопроса о том, чем открывать XML-файлы проще всего, то здесь прекрасно подойдет самый обычный «Блокнот». Да-да! Именно он.
Просто кликаем на файле правой кнопкой и выбираем из меню команду «Открыть с помощью. », после чего выбираем стандартный «Блокнот». В общем-то, такое простое открытие обусловлено тем, что файлы такого типа, равно как и HTML-документы, содержат исключительно текстовую информацию.
Но вот если пользователь не знает основ языка eXtensible Markup Language, редактированием с последующим сохранением лучше не заниматься. Впоследствии специализированные модули (особенно если исходный файл содержит список настроек какой-либо программы) выдадут ошибку применения содержимого в самом приложении, то есть компонент окажется либо поврежденным, либо недоступным.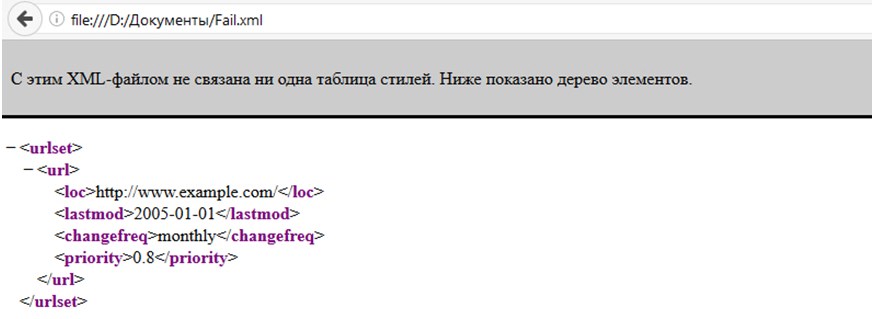
Программы, открывающие файлы XML
Теперь посмотрим, какие именно приложения могут работать с файлами такого типа. В данном случае имеются в виду операции создания, редактирования и открытия.
Как уже говорилось, XML – это текстовый формат, а значит, вопрос о том, чем открывать XML-файлы, сводится исключительно к выбору редактора, распознающего такие данные.
Наиболее подходящими для таких целей станут программы в виде «Блокнота» (Notepad++ или что-то еще), обычный редактор Microsoft Word или ему подобный Word Pad, специализированные утилиты с углубленной поддержкой синтаксиса языка вроде XML Marker, XML Pad, Oxygen XML Editor, EditiX Lite Version и многие другие.
Кстати, стоит обратить внимание, что решить проблему, чем открыть файл XML на компьютере, можно даже при помощи табличного редактора Excel, входящего в стандартный офисный набор. Правда, файлы большого объема могут не открыться. Тут попросту существует ограничение по количеству строк.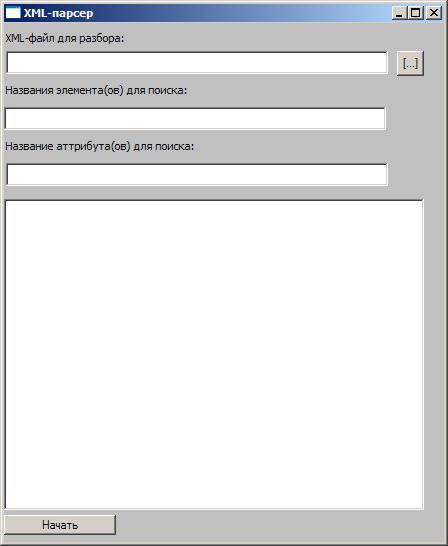
Наконец, для обычного просмотра, а не для редактирования содержимого, открыть файлы такого типа можно в любом Интернет-браузере вроде Internet Explorer, Opera, Google Chrome и т.д.
Открытие XML-вложений электронной почты
Но вот зачастую наблюдается проблема открытия файлов такого типа, когда они содержатся во вложениях электронной почты, причем в клиентах, установленных в системе (например, Outlook Express или Microsoft Outlook). Сейчас речь не идет о почтовых серверах.
Такие приложения способны выдавать ошибки открытия (чтения), поскольку вложение сначала сохраняется в специальной папке в виде временного файла, и обращение при открытии производится именно к нему. Чтобы выйти из такого затруднительного, как кажется многим, положения, достаточно предварительно сохранить вложение с оригинальным расширением в любом удобном месте, используя для этого выпадающее меню, вызываемое правым кликом на файле, вложенном в электронное сообщение. После этого проблем с открытием в том же «Блокноте» быть не должно.
Заключение
Вот, собственно, и все, что касается вопроса о том, чем открывать XML-файлы. Если подводить некий итог, можно отметить, что вся процедура осуществляется совершенно элементарно с использованием любого, даже самого примитивного текстового редактора или Интернет-браузера. Но если требуется произвести его редактирование, лучше использовать специальные утилиты, которые способны проверять синтаксис языка в автоматическом режиме, а то ведь при нарушении структуры того же тега файл может оказаться просто бессмысленным набором символов, а программа, использующая его в качестве дополнительного средства сохранения настроек, и вовсе перестанет работать.
XML расшифровывается как eXtensible Markup Language, что в переводе на русский означает буквально следующее: расширяемый язык разметки. Это довольно простой язык, который можно использовать для создания или обработки документов, нацеленных на использование во всемирной паутине. XML чем-то похож на другой популярный язык — HTML, но отличается тем, что позволяет задавать свои теги и использовать их впоследствии.
Документ, построенный в XML, представляет из себя дерево элементов, некоторые из которых могут содержать определенное значение или обладать некими атрибутами. Для того, что бы с ним работать, достаточно знать начальные навыки программирования. Надеюсь, теперь вы понимаете, почему данный формат столь популярен в интернете? Кстати, чаще всего он используется в шаблонах сайтов, для работы с картой веб-ресурса, для обмена информации с сервером и т.д.
Блокнот
Вообще-то файл можно открыть абсолютно любым текстовым редактором, но с некоторыми оговорками. Первым редактором, который приходит на ум, является самый обыкновенный блокнот (стандартное приложение Windows). Пробуем открыть им документ и… Видим какие-то кракозября. На самом деле если присмотреться, то можно выяснить, что кодировка текста абсолютно верная, просто все записи были совмещены в одну, поэтому разобраться в них крайне проблематично.
Microsoft Word
Следующим в нашем списке будет от Microsoft. Я открыл в нем файл и весь список данных был моментально преобразован в таблицу. Правда, насколько мне известно, старые версии программы не поддерживают возможность преобразование XML, то есть показывают его ровно в том же самом виде, что и обычный блокнот.
Я открыл в нем файл и весь список данных был моментально преобразован в таблицу. Правда, насколько мне известно, старые версии программы не поддерживают возможность преобразование XML, то есть показывают его ровно в том же самом виде, что и обычный блокнот.
Microsoft Excel
Excel показался более интересным, поскольку «раскладывает» файл в очень удобную таблицу, работать с которой — одно удовольствие. Единственный минус, который я заметил — долгая загрузка программы вместе с файлом. Видимо, это также зависит от размера последнего.
Notepad++
Самая удобная программа на мой взгляд — это Notepad++. Данный текстовый редактор является одним из наиболее быстрых в мире на текущий момент и способен открывать даже большие документы в считанные секунды. Он моментально преобразует содержание XML в таблицу, работать с которой становится очень удобно и просто. Notepad++ написан на языке C++ и обладает открытым исходным кодом. Функциональность его поистине огромна, а если ее вдруг станет не хватать, тогда на помощь придут дополнительные модули и плагины.
Онлайн-сервис
В интернете мне удалось найти сервис для работы с данным форматом, причем на нем можно не только просматривать документ, но даже редактировать его. Сервис расположен по следующему адресу: xmlgrid.net.
На сегодняшний день существует просто огромное количество редакторов XML на любой вкус. Большинство из них бесплатные, однако некоторые разработчики просят определенную плату за свои труды. Я считаю, что если вы являетесь неискушенным пользователем, то вам вполне хватит простенького редактора типа упоминавшегося выше Notepad++. Однако если функциональности программы не хватает, стоит обратить внимание на платные приложения.
XML является расширяемым языком разметки. Смысл здесь заключается в том, чтобы предоставить удобный инструмент для представления и хранения структурированных данных. С помощью этого языка вы можете какие-то структуры данных сохранить в понятном и читаемом удобном виде. XML является стандартным языком, то есть его понимают многие приложения, что позволяет использовать его на разных платформах. Именно стандартность этого языка позволяет удобно пользоваться его возможностями.
Именно стандартность этого языка позволяет удобно пользоваться его возможностями.
Второе назначение заключается в том, что вы легко можете использовать документы в формате XML для обмена информацией между разными программами. В том числе между утилитами, которые расположены на разных компьютерах. Ну и наконец, он используется для создания всевозможных специализированных языков разметки (для создания практически всех возможных страниц в интернете).
Многие люди полагают, что в последнем случае используется HTML, хотя на самом деле дела обстоят иначе: используется XML. HTML же, в свою очередь, является расширением языка последнего. Кроме того, существует огромное количество других языков разметки для представления медицинских, финансовых, математических и других данных. И все они строятся на основе XML. Поэтому понимание его принципов любому программисту сегодня, конечно, необходимо. Вместе с тем появилось огромное количество приложений, поэтому множество вариантов развития есть для этого языка. Например, появился XPath, представляющий собой язык запросов к элементам документа. Где же всё-таки применяется такое расширение?
Например, появился XPath, представляющий собой язык запросов к элементам документа. Где же всё-таки применяется такое расширение?
- XHTML – это основной практически способ представления информации в интернете. То есть любая страница, открываемая в браузере, представлена в этом виде.
- WSDL – это язык, описывающий взаимодействия с различными веб-сервисами (программа, которая расположена где-то в интернете). То есть вы можете выполнить какие-нибудь операции для вашей программы. Простыми словами, он описывает, как именно нужно организовать взаимодействие с веб-сервисами. Данные при этом должны быть формата XML.
- SVG – язык разметки масштабируемой векторной графики. На самом деле, это тоже расширение XML. Он позволяет описывать различные картинки в векторном формате , которые можно достаточно часто встретить в интернете. При этом само изображение описано в виде какого-либо документа XML.
- Ещё одно расширение – OWL – позволяет описывать структуры знаний. Используется в различных каталогах, чтобы описывать взаимодействие между различными классами объектов.


Вообще, этих расширений большое множество, поэтому все их рассматривать мы не будем. Здесь главное понять принцип, что XML является неким «прародителем» остальных. То есть эти приложения всего лишь облегчают работу с данными, не являясь при этом отдельной системой.
Чем открыть расширение XML?
Такой файл может создаваться совершенно разными программами, и он используется для обмена данными или для создания баз данных . Этот файл представляет собой текстовый документ, где все данные разделены с помощью тегов. Он очень похож на HTML, только теги задаёт сам пользователь, их количество не ограничено. Но как открыть XML-файл в читаемом виде?
Рассмотрим несколько возможных способов:
Редактировать файл можно очень легко в любом из доступных вам инструментов, описанных выше. То есть можно использовать и блокноты, и Excel. Но конечно же, лучше использовать специализированное программное обеспечение, например, XML Marker. Его можно бесплатно скачать, затем установить на свой компьютер или ноутбук.
Расширение.xml присуще файлам с текстовыми данными в формате XML.
Изначально язык создавался для использования во «всемирной паутине». Разработчики хотели сделать из него достойную замену HTML, но задумка у них не получилась. В результате XML оказался на своем теперешнем месте. Расширяемым языком разметки eXtensible Markup Language описывается документ и софт (реже), который выполняет чтение таких файлов.
Язык XML имеет простой синтаксис. Его удобно использовать в процессе создания документов для быстрой обработки в программах качественного чтения в интернете. Разработчики выбирают этот язык за его простоту, расширяемость, удобство. Заметим, что XML базируется на кодировках Юникод. Язык имеет способность к свободному расширению разметки (ограничения есть только в синтаксических правилах языка), поэтому он и называется расширяемым. Разработчик сможет применить его для решения почти любых задач.
Сейчас XML приобрел огромную популярность в Интернете. Нередко это расширение используется в документообороте. Заметим, что именно XML стал «прародителем» многих современных форматов, например, (знаком любителям электронных книг) или YML.
Заметим, что именно XML стал «прародителем» многих современных форматов, например, (знаком любителям электронных книг) или YML.
Как совершить процесс открытия?
Многие спрашивают, какие есть программы для чтения файлов XML формата, открыть его можно в браузере. Для этого можно использовать, например, Mozilla Firefox (в этом случае нужно выбрать версию с плагином XML Viewer) или Internet Explorer. Чтобы просмотреть файл, который имеет расширение.xml, на своем компьютере через браузер, нужно запустить его, нажать комбинацию клавиш «Ctrl+O» (если ваш ПК управляется операционной системой MacOS, то нужно использовать сочетание клавиш «Command+O»). После этого вы выбираете тот xml-файл, который вам необходим, и нажимаете «ENTER». Любой документ, который имеет расширение.xml, также открывается с помощью текстового редактора. Например, в просмотре и редактировании вам поможет notepad. Разработчики такого расширения рекомендуют открывать xml-файл с использованием такого софта, для которого он был создан.
Подробнее ознакомиться со списком программ, которые помогут вам открыть файлы с расширением XML на компьютере, вы сможете на нашем сайте.
Примечание: Мы стараемся как можно оперативнее обеспечивать вас актуальными справочными материалами на вашем языке. Эта страница переведена автоматически, поэтому ее текст может содержать неточности и грамматические ошибки. Для нас важно, чтобы эта статья была вам полезна. Просим вас уделить пару секунд и сообщить, помогла ли она вам, с помощью кнопок внизу страницы. Для удобства также приводим ссылку на оригинал (на английском языке).
Вероятно, вы слышали о языке XML и вам известно множество причин, по которым его необходимо использовать в вашей организации. Но что именно представляет собой XML? В этой статье объясняется, что такое XML и как он работает.
В этой статье
Пометки, разметка и теги
Чтобы понять XML, полезно вспомнить о том, как можно помечать данные. Документы создавались людьми в течение многих столетий, и на протяжении всего этого времени люди делали в них пометки. Например, учителя часто делают пометки в работах учащихся, указывая на необходимость переместить абзацы, сделать предложение более ясным, исправить орфографические ошибки и т. д. Посредством пометок в документе можно определить структуру, смысл и внешний вид информации. Если вы когда-либо использовали исправления в Microsoft Office Word, то вы знакомы с компьютеризованной формой добавления пометок.
Например, учителя часто делают пометки в работах учащихся, указывая на необходимость переместить абзацы, сделать предложение более ясным, исправить орфографические ошибки и т. д. Посредством пометок в документе можно определить структуру, смысл и внешний вид информации. Если вы когда-либо использовали исправления в Microsoft Office Word, то вы знакомы с компьютеризованной формой добавления пометок.
В мире информационных технологий термин «пометка» превратился в термин «разметка». При разметке используются коды, называемые тегами (или иногда токенами), для определения структуры, визуального оформления и — в случае XML — смысла данных.
Текст этой статьи в формате HTML является хорошим примером применения компьютерной разметки. Если в Microsoft Internet Explorer щелкнуть эту страницу правой кнопкой мыши и выбрать команду Просмотр HTML-кода, вы увидите читаемый текст и теги HTML, например
. В HTML- и XML-документах теги легко распознать, поскольку они заключены в угловые скобки.
 В исходном тексте этой статьи теги HTML выполняют множество функций, например определяют начало и конец каждого абзаца (
В исходном тексте этой статьи теги HTML выполняют множество функций, например определяют начало и конец каждого абзаца () и местоположение рисунков.
Отличительные черты XML
Документы в форматах HTML и XML содержат данные, заключенные в теги, но на этом сходство между двумя языками заканчивается. В формате HTML теги определяют оформление данных — расположение заголовков, начало абзаца и т. д. В формате XML теги определяют структуру и смысл данных — то, чем они являются.
При описании структуры и смысла данных становится возможным их повторное использование несколькими способами. Например, если у вас есть блок данных о продажах, каждый элемент в котором четко определен, то можно загрузить в отчет о продажах только необходимые элементы, а другие данные передать в бухгалтерскую базу данных. Иначе говоря, можно использовать одну систему для генерации данных и пометки их тегами в формате XML, а затем обрабатывать эти данные в любых других системах вне зависимости от клиентской платформы или операционной системы. Благодаря такой совместимости XML является основой одной из самых популярных технологий обмена данными.
Благодаря такой совместимости XML является основой одной из самых популярных технологий обмена данными.
Учитывайте при работе следующее:
HTML нельзя использовать вместо XML. Однако XML-данные можно заключать в HTML-теги и отображать на веб-страницах.
Возможности HTML ограничены предопределенным набором тегов, общим для всех пользователей.
Правила XML разрешают создавать любые теги, требуемые для описания данных и их структуры. Допустим, что вам необходимо хранить и совместно использовать сведения о домашних животных. Для этого можно создать следующий XML-код:
Как видно, по тегам XML понятно, какие данные вы просматриваете. Например, ясно, что это данные о коте, и можно легко определить его имя, возраст и т. д. Благодаря возможности создавать теги, определяющие почти любую структуру данных, язык XML является расширяемым.
Но не путайте теги в данном примере с тегами в HTML-файле. Например, если приведенный выше текст в формате XML вставить в HTML-файл и открыть его в браузере, то результаты будут выглядеть следующим образом:
Izzy Siamese 6 yes no Izz138bod Colin Wilcox
Веб-браузер проигнорирует теги XML и отобразит только данные.
Правильно сформированные данные
Вероятно, вы слышали, как кто-то из ИТ-специалистов говорил о «правильно сформированном» XML-файле. Правильно сформированный XML-файл должен соответствовать очень строгим правилам. Если он не соответствует этим правилам, XML не работает. Например, в предыдущем примере каждый открывающий тег имеет соответствующий закрывающий тег, поэтому в данном примере соблюдено одно из правил правильно сформированного XML-файла. Если же удалить из файла какой-либо тег и попытаться открыть его в одной из программ Office, то появится сообщение об ошибке и использовать такой файл будет невозможно.
Правила создания правильно сформированного XML-файла знать необязательно (хотя понять их нетрудно), но следует помнить, что использовать в других приложениях и системах можно лишь правильно сформированные XML-данные. Если XML-файл не открывается, то он, вероятно, неправильно сформирован.
XML не зависит от платформы, и это значит, что любая программа, созданная для использования XML, может читать и обрабатывать XML-данные независимо от оборудования или операционной системы. Например, при применении правильных тегов XML можно использовать программу на настольном компьютере для открытия и обработки данных, полученных с мейнфрейма. И, независимо от того, кто создал XML-данные, с ними данными можно работать в различных приложениях Office. Благодаря своей совместимости XML стал одной из самых популярных технологий обмена данными между базами данных и пользовательскими компьютерами.
Например, при применении правильных тегов XML можно использовать программу на настольном компьютере для открытия и обработки данных, полученных с мейнфрейма. И, независимо от того, кто создал XML-данные, с ними данными можно работать в различных приложениях Office. Благодаря своей совместимости XML стал одной из самых популярных технологий обмена данными между базами данных и пользовательскими компьютерами.
В дополнение к правильно сформированным данным с тегами XML-системы обычно используют два дополнительных компонента: схемы и преобразования. В следующих разделах описывается, как они работают.
Схемы
Не пугайтесь термина «схема». Схема — это просто XML-файл, содержащий правила для содержимого XML-файла данных. Файлы схем обычно имеют расширение XSD, тогда как для файлов данных XML используется расширение XML.
Схемы позволяют программам проверять данные. Они формируют структуру данных и обеспечивают их понятность создателю и другим людям. Например, если пользователь вводит недопустимые данные, например текст в поле даты, программа может предложить ему исправить их. Если данные в XML-файле соответствуют правилам в схеме, для их чтения, интерпретации и обработки можно использовать любую программу, поддерживающую XML. Например, как показано на приведенном ниже рисунке, Excel может проверять данные на соответствие схеме CAT.
Если данные в XML-файле соответствуют правилам в схеме, для их чтения, интерпретации и обработки можно использовать любую программу, поддерживающую XML. Например, как показано на приведенном ниже рисунке, Excel может проверять данные на соответствие схеме CAT.
Схемы могут быть сложными, и в данной статье невозможно объяснить, как их создавать. (Кроме того, скорее всего, в вашей организации есть ИТ-специалисты, которые знают, как это делать.) Однако полезно знать, как выглядят схемы. Следующая схема определяет правила для набора тегов . :
Не беспокойтесь, если в примере не все понятно. Просто обратите внимание на следующее:
Строковые элементы в приведенном примере схемы называются объявлениями. Если бы требовались дополнительные сведения о животном, например его цвет или особые признаки, то специалисты отдела ИТ добавили бы к схеме соответствующие объявления. Систему XML можно изменять по мере развития потребностей бизнеса.
Объявления являются мощным средством управления структурой данных. Например, объявление означает, что теги, такие как и
Например, объявление означает, что теги, такие как и
, должны следовать в указанном выше порядке. С помощью объявлений можно также проверять типы данных, вводимых пользователем. Например, приведенная выше схема требует ввода положительного целого числа для возраста кота и логических значений (TRUE или FALSE) для тегов ALTERED и DECLAWED.
Если данные в XML-файле соответствуют правилам схемы, то такие данные называют допустимыми. Процесс контроля соответствия XML-файла данных правилам схемы называют (достаточно логично) проверкой. Большим преимуществом использования схем является возможность предотвратить с их помощью повреждение данных. Схемы также облегчают поиск поврежденных данных, поскольку при возникновении такой проблемы обработка XML-файла останавливается.
Преобразования
Как говорилось выше, XML также позволяет эффективно использовать и повторно использовать данные. Механизм повторного использования данных называется преобразованием XSLT (или просто преобразованием).
Вы (или ваш ИТ-отдел) можете также использовать преобразования для обмена данными между серверными системами, например между базами данных. Предположим, что в базе данных А данные о продажах хранятся в таблице, удобной для отдела продаж. В базе данных Б хранятся данные о доходах и расходах в таблице, специально разработанной для бухгалтерии. База данных Б может использовать преобразование, чтобы принять данные от базы данных A и поместить их в соответствующие таблицы.
Сочетание файла данных, схемы и преобразования образует базовую систему XML. На следующем рисунке показана работа подобных систем. Файл данных проверяется на соответствие правилам схемы, а затем передается любым пригодным способом для преобразования. В этом случае преобразование размещает данные в таблице на веб-странице.
В следующем примере представлено преобразование, которое загружает данные в таблицу на веб-странице. Суть примера не в том, чтобы объяснить, как создавать преобразования, а в том, чтобы показать одну из форм, которую они могут принимать.
В этом примере показано, как может выглядеть текст одного из типов преобразования, но помните, что вы можете ограничиться четким описанием того, что вам нужно от данных, и это описание может быть сделано на вашем родном языке. Например, вы можете пойти в отдел ИТ и сказать, что необходимо напечатать данные о продажах для конкретных регионов за последние два года, и что эти сведения должны выглядеть так-то и так-то. После этого специалисты отдела могут написать (или изменить) преобразование, чтобы выполнить вашу просьбу.
Корпорация Майкрософт и растущее число других компаний создают преобразования для различных задач, что делает использование XML еще более удобным. В будущем, скорее всего, можно будет скачать преобразование, отвечающее вашим потребностям без дополнительной настройки или с небольшими изменениями. Это означает, что со временем использование XML будет требовать все меньше и меньше затрат.
XML в системе Microsoft Office
Профессиональные выпуски Office обеспечивают расширенную поддержку XML. Начиная с 2007 Microsoft Office System, Microsoft Office использует форматы файлов на основе XML, например DOCX, XLSX и PPTX. Так как XML хранит данные в текстовом формате, а не в собственном двоичном формате, клиенты могут определять собственные схемы и использовать ваши данные разными способами, без необходимости платить ройалтиес. Дополнительные сведения о новых форматах см. в статье форматы Open XML и расширения имен файлов. Ниже приведены другие преимущества.
Начиная с 2007 Microsoft Office System, Microsoft Office использует форматы файлов на основе XML, например DOCX, XLSX и PPTX. Так как XML хранит данные в текстовом формате, а не в собственном двоичном формате, клиенты могут определять собственные схемы и использовать ваши данные разными способами, без необходимости платить ройалтиес. Дополнительные сведения о новых форматах см. в статье форматы Open XML и расширения имен файлов. Ниже приведены другие преимущества.
Меньший размер файлов. Новый формат использует ZIP и другие технологии сжатия, поэтому размер файла на 75 процентов меньше, чем в двоичных форматах, применяемых в более ранних версиях Office.
Более простое восстановление данных и повышенная безопасность. XML — это читаемость, поэтому если файл поврежден, вы можете открыть его в Microsoft Notepad или в другом текстовом средстве чтения и восстановить по крайней мере часть ваших данных. Кроме того, новые файлы более безопасны, поскольку они не могут содержать код Visual Basic для приложений (VBA). Если для создания шаблонов используется новый формат, все элементы ActiveX и макросы VBA располагаются в отдельном, более безопасном разделе файла. Кроме того, для удаления личных данных можно использовать инструменты, такие как инспектор документов. Дополнительные сведения об использовании инспектора документов см. в статье Удаление скрытых и персональных данных путем проверки документов.
Если для создания шаблонов используется новый формат, все элементы ActiveX и макросы VBA располагаются в отдельном, более безопасном разделе файла. Кроме того, для удаления личных данных можно использовать инструменты, такие как инспектор документов. Дополнительные сведения об использовании инспектора документов см. в статье Удаление скрытых и персональных данных путем проверки документов.
Все это замечательно, но что делать, если у вас есть XML-данные без схемы? Это зависит от того, какую программу Office вы используете. Например, при открытии XML-файла без схемы в приложении Excel оно предполагает, что схема существует, и дает возможность загрузить данные в XML-таблицу. Вы можете использовать XML-списки и таблицы для сортировки, фильтрации и вычисления данных.
Включение средств XML в Office
По умолчанию вкладка «Разработчик» не отображается. Ее необходимо добавить на ленту для использования команд XML в Office.
В Office 2016, Office 2013 или Office 2010: Отображение вкладки «Разработчик».
Не все, но очень многие пользователи современных компьютерных систем зачастую сталкиваются с непонятными файлами формата XML. Что это за данные и зачем они нужны, знает еще меньше юзеров. Ну а какой программой открыть файл XML, понимают вообще единицы. Хотя в этом вопросе все достаточно просто, тем не менее иногда возникают и проблемы. Посмотрим, что к чему.
Формат XML – что это такое?
Начнем с того, что XML-формат представляет собой тип данных, создаваемых при помощи специального языка Extensible Markup Language с использованием команд, включающих в себя описательную часть свойств или настроек какого-то объекта на основе тегов и атрибутов.
Если говорить простым языком, XML-формат является текстовым и чем-то напоминает гипертекстовую разметку HTML, которая широко используется в Интернете. Поэтому предварительным решением проблемы того, как открыть XML-файл в читаемом виде, может стать использование практически любого, пусть даже самого примитивного текстового редактора или просмотрщика. Но тут не все так просто, поскольку сами файлы могут иметь совершенно разное предназначение.
Для чего используются файлы XML?
Прежде чем дать ответ на вопрос о том, как открыть файл XML в нормальном виде, узнаем, для чего же нужны такие типы данных.
Во-первых, они могут содержать достаточно большие объемы информации, например, о музыкальных или видеоколлекциях, размещаемых в сети Интернет. Сами файлы несколько напоминают ID3-теги, которые используются в файлах MP3 и содержат данные о названии исполнителя, альбома, годе выпуска, жанре и т. д. Что же касается именно формата XML, у таких файлов возможность добавления данных практически не ограничена, а представляемая информация может касаться не только единичного объекта (трека или фильма), но и целой их совокупности (альбомы, коллекции и т. д.). Единственное ограничение – лимит максимально возможного количества строк в тексте. Именно это зачастую и вызывает проблемы при открытии.
Во-вторых, такие файлы очень часто имеют привязку к специализированным программам, а текстовая информация содержит данные о некоторых важных настройках самого приложения или же о параметрах, задаваемых пользователем. Например, в любой музыкальной программе можно установить собственные параметры для какой-то одной или нескольких дорожек, после чего сохранить их в виде пользовательского шаблона. И сохранение, как уже, наверное, понятно, происходит именно в формате XML.
Например, в любой музыкальной программе можно установить собственные параметры для какой-то одной или нескольких дорожек, после чего сохранить их в виде пользовательского шаблона. И сохранение, как уже, наверное, понятно, происходит именно в формате XML.
Как открыть файл XML в нормальном виде: простейший метод
Теперь посмотрим на самый легкий вариант открытия файлов такого типа. Для примера возьмем Windows-системы. Как правило, ассоциация для этого формата по умолчанию не задана. Как следствие – невозможность открытия файла двойным кликом.
С другой стороны, даже если применить такую методику, любая модификация Windows изначально предоставит список из нескольких наиболее подходящих приложений или предложит пользователю самому указать исполняемый EXE-файл путем обзора.
Первое, что приходит на ум в связи с тем, что формат это текстовый, – выбор редактора именно такого типа. В списке программ одним из первых (если не самым первым) предлагается стандартный «Блокнот» – приложение, входящее в обязательный набор любой модификации Windows.
Впрочем, если решать проблему с тем, как открыть файл XML в нормальном виде, сначала можно запустить сам «Блокнот», а потом использовать команду открытия из меню файла или стандартное для всех приложений сочетание Ctrl + O. Само собой разумеется, если такой вариант удобен, в меню выбора программ можно задать использование данного метода для всех файлов такого типа или в меню свойств файла самому выбрать искомую программу, которая впоследствии и будет открывать этот формат по умолчанию (двойным кликом).
Можно, конечно, для просмотра использовать и любой интернет-браузер, но вот редактировать данные не получится – только просмотреть в виде текста, не более того.
Как открыть XML-файл в читаемом виде: оптимальные программы
Впрочем, только лишь простым текстовым редактором дело не ограничивается. Точно так же просто можно использовать и более мощные текстовые процессоры наподобие Microsoft Word. Файл XML в Word будет иметь точно такой же вид, как и любой другой, например, формата TXT.
Но стоит обратить внимание на тот момент, что выравнивание в Word, собственно как и форматирование, несколько отличается от стандартного «Блокнота». Да, просмотреть или отредактировать данные можно, но структура документа со всевозможными специальными отступами (особенно при наличии достаточно длинных строк) может быть нарушена.
А вот чего уж точно многие не знают, так это того, что проблему, как открыть файл XML в нормальном виде, можно решить даже с помощью табличного процессора MS Excel. Правда, тут-то и начинает действовать ограничение по строкам. Иными словами, если документ содержит слишком много данных, информация отобразится не полностью.
Но если говорить о том, как открыть файл XML в нормальном виде, что ни на есть читабельном и редактируемом, то лучше использовать оригинальные программы, которые позволяют создавать данные такого типа, но не всевозможные блокноты, а специальные приложения с поддержкой синтаксиса языка. Среди них особо можно отметить такие как Oxygen XML Editor, EditiX, XML Marker и им подобные.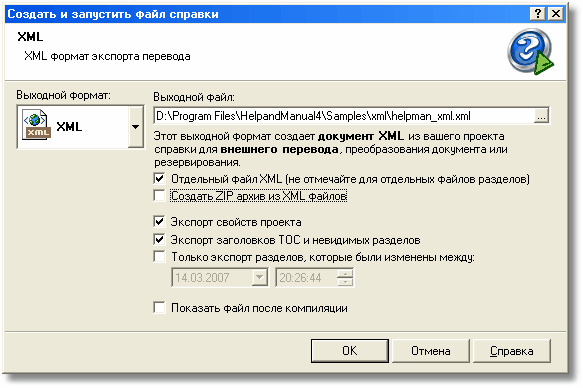 Тут нужно четко понимать, что такие приложения изначально «заточены» под язык и имеют намного больше возможностей по сравнению с остальными текстовыми редакторами, пусть даже самыми «навороченными».
Тут нужно четко понимать, что такие приложения изначально «заточены» под язык и имеют намного больше возможностей по сравнению с остальными текстовыми редакторами, пусть даже самыми «навороченными».
Ошибка открытия формата XML
Итак, с вопросом о том, как открыть файл XML в нормальном виде, мы немного разобрались. Теперь разберем некоторые ошибки при попытке открытия таких данных для просмотра или редактирования. Как правило, используемое приложение может выдавать сообщение о том, что ему не удается открыть XML-файл, поскольку нарушена целостность искомого объекта. Причин для этого может быть сколько угодно (например, незавершенная или внезапно прерванная закачка из Интернета).
Еще сбои могут возникать, когда он содержит некорректные теги и атрибуты. В некоторых случаях сбои могут наблюдаться в том случае, если XML-файл является вложением электронной почты. При попытке открытия в стандартных программах вроде Outlook Express сначала происходит сохранение файла в виде временных данных, имеющих формат TMP, а программа, отвечающая за открытие искомого оригинального файла, такое расширение не понимает. Поэтому лучше сначала сохранить вложение в оригинальном виде, а открывать уже после.
Поэтому лучше сначала сохранить вложение в оригинальном виде, а открывать уже после.
Что предпочесть для работы с XML-файлами?
Вот мы и разобрались, как открыть файл XML в нормальном виде. Что использовать? В самом простом варианте для просмотра подойдет любой текстовый редактор или тот же табличный процессор. Но если требуется редактирование, да еще и с поддержкой синтаксиса, во избежание возможных ошибок при вводе команд без специализированных приложений не обойтись.
Чем открыть sig файлы Госуслуги
Электронный документ формата sig – это файл с вложенной в него цифровой подписью. Она подтверждает подлинность документа, прикрепляется в конце. Чтобы распаковать sig, пользователям необходимо знать несколько правил и способов. Узнать, как открыть sig документ с Госуслуг, поможет эта статья.
Какие файлы можно скачать и загрузить на портале Госуслуг
На официальной странице Госуслуг можно скачать четыре вида подписей:
- графическая – такой вид применяется для фото, графиков и иных изобразительных материалов;
- шрифт Брайля;
- почтовая – имеет контактные данные;
- цифровая – используется при составлении электронных договоров, для дистанционного получения государственных услуг, электронной коммерции и т. д. (основное предназначение – аналог реальной подписи, подтверждающий подлинность документа).
 д. (основное предназначение – аналог реальной подписи, подтверждающий подлинность документа).
д. (основное предназначение – аналог реальной подписи, подтверждающий подлинность документа).Как открыть файлы типа sig
Процедура распаковки напрямую зависит от типа вложенной в документ авторской подписи. Если документ с рассматриваемым расширением пришел в электронном виде через email, то в прикрепленном файле содержатся персональные и контактные данные об адресате. Например, название предприятия или организации, подчинение структуры, ее регистрационные данные, занимаемая должность адресанта, ФИО и т. д. Подобного рода подписи можно распаковать с помощью онлайн-сервисов.
Что такое расширение sig
Название формата sig — сокращенный вариант английского слова signature, который в переводе означает «подпись». Параметры документа можно определить по ярлыку — в нем будет изображение или текст. В информации указывается:
- адрес адресанта или адресата;
- закодированный публичный ключ, который подтверждает подлинность присланного документа или папки;
- имя и реквизиты самого отправителя или компании.

Как открыть файл: инструкция
Чем открыть sig-файлы Госуслуги? Пользователи, у которых установлена операционная система Windows, могут просто открывать такой формат при стандартном наборе программного обеспечения. Для распаковки файла чаще всего используются средства Microsoft Outlook или обычный блокнот.
Что касается операционной системы Mac, то произвести распаковку подписи помогут следующие программы:
- The Print View;
- The Print Shop;
- Print Master.
На официальной странице ЕПГУ есть рубрика, посвященная теме, как из Росреестра распаковать Excel-документ с расширением sig. Как открыть sig справку с Госуслуг? Для этого необходимо иметь на ПК или смартфоне установочные программы, отвечающие за чтение электронных документов, которые имеют название, оканчивающееся на XML и SIG.
Открытие справки проходит по следующей схеме:
- Открыть окно для проверки эл. подписи.
- Нажать активную кнопку «Открыть».
- В открывшейся адресной строке указать место, куда автоматически сохранится файл при его открытии
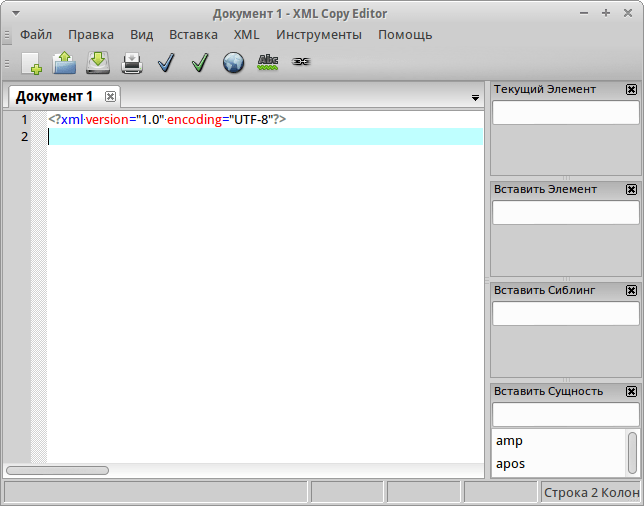
Также подпись можно конвертировать в документ с расширением pdf, воспользовавшись интернет-сервисом ru.pdf24.org.
Проверить подлинность подписи можно непосредственно на сайте Госуслуги. Для того, чтобы удостовериться в подлинности пришедшего письма на личном ПК, необходимо дополнительно на него установить платное программное обеспечение (каждое ПО обладает 30-дневной бесплатной демо-версией, которая позволяет во всех деталях изучить функционал). Распаковать sig можно с помощью:
- Crypto Pro;
- Крипто АРМ.
Другие форматы файлов
Кроме элементов с расширением sig на сайте gosuslugi.ru можно еще открыть документы с другими расширениями. В связи с этим возникают следующие вопросы:
- Как открыть файл xml с Госуслуг? На сайте выбрать поле «Электронный документ» – «Обзор» – выбор документа, который требуется открыть – «Проверить» – «Напечатать» или «Сохранить».
- Как сжать файл jpg для Госуслуг? Один из самых простых и доступных способов – это экспортировать изображение в GIMP на компьютере. Нажать правой кнопкой мыши на изображении – «Экспортировать как» – ввести имя изображения с необходимым расширением через точку – «Экспортировать».
- Как создать многостраничный tiff-файл для Госуслуг? С помощью онлайн-конвертеров или программного обеспечения. Самым простым и доступным является IrfanView.

Частые ошибки при открытии файлов
Если на ПК нет программных файлов, их нужно установить или воспользоваться онлайн-сервисами. В процессе распаковки документа пользователь может столкнуться со следующими проблемами:
- повреждение полученного файла во время неправильной отсылки или при получении (нестабильный интернет, вирусы и прочее). Если такая ситуация произошла, надо обратиться с данным вопросом в службу техподдержки официального сайта Госуслуги. Если не поступило никакого предложения решения проблемы, необходимо обратиться в ведомство, которое предоставило справку. Если за выдачу ее взималась государственная пошлина, файл должен быть автоматически заменен на читаемый.
- несуществующая подпись. В этом случае стоит также обратиться в учреждение, где была заказана цифровая подпись.
 Если за выдачу ее взималась государственная пошлина, файл должен быть автоматически заменен на читаемый.
Если за выдачу ее взималась государственная пошлина, файл должен быть автоматически заменен на читаемый.Если следовать инструкции «Как открыть файл-sig Госуслуги», то проблем и трудностей в процессе возникать не должно. Если при открытии файла появится сообщение об ошибке, пользователь может обратиться в службу поддержки Госуслуг.
Проверка электронного документа: простой способ открыть XML-файл
Росреестр проверка электронного документа и простой способ открыть XML-файл
Внедрение службой Росреестра электронного сервиса по регистрации прав собственности и обременений недвижимости, а также предоставления сведений об объектах, активность мошенников на рынке недвижимости значительно сократилась, теперь стало гораздо проще избежать обмана, ведь Вы можете в любое время узнать, кто хозяин того или иного строения.
Также можно увидеть и обременения, может оказаться, что приобретаемое жилье является предметом аренды или залога. Развитие электронных сервисов достигло такого уровня, что практически любые операции с недвижимым имуществом можно совершить, не выходя из дома. Также существует сервис проверки готовности документа. Изучим, как это можно сделать.
Развитие электронных сервисов достигло такого уровня, что практически любые операции с недвижимым имуществом можно совершить, не выходя из дома. Также существует сервис проверки готовности документа. Изучим, как это можно сделать.
Как проверить электронный документ Росреестра?
Для проверки цифрового файла на официальном сайте есть специальный сервис, который Вы легко можете найти в списке функций. С его помощью можно проверить подлинность кадастровой выписки и актуальность подписи лица, уполномоченного проводить регистрацию сделок.
Это весьма удобно, поскольку так Вы сможете обезопасить себя от подлога документов при покупке. Для проверки, достаточно лишь загрузить файл в систему и через некоторое время Вы получите результат.
Это важно!
Совсем недавно, заключение экспертизы формировалось в простом pdf-формате, легко читаемом даже на самых старых компьютерах. Его можно было без проблем открыть и распечатать на любом принтере, однако, сейчас желанный файл выгружается в таких форматах, как xml и xml.
 sig, их уже просто так не открыть, однако, это было сделано не из вредности, а в целях сохранения конфиденциальности.
sig, их уже просто так не открыть, однако, это было сделано не из вредности, а в целях сохранения конфиденциальности.Как открыть файл Росреестра в формате xml и xml.sig?
Для этого нужно будет вернуться в уже знакомый нам раздел проверки документов и нажать на кнопку проверки. Далее, заверяем выписку ЭЦП и жмем на кнопку «Показать файл» затем, находим особую кнопку показа в человеческом формате и выбираем ее. Для проведения этих процедур на компьютере должны находиться два файла – .xml и .sig, иначе Вы рискуете получить ошибку.
В результате этих действий, Вы получите выписку из ЕГРП, содержащую все основные сведения об объекте, которую можно уже либо сохранить в нормальном формате, либо сразу отправить в печать.
Это важно!
Бывают ситуации, когда план помещений отсутствует. При этом Вы увидите сообщение об ошибке. Паниковать не стоит, просто проверьте, что картинка с планом и файл выписки располагаются в одной папке.
 Ни в коем случае не вносите изменения в имена файлов.
Ни в коем случае не вносите изменения в имена файлов.Несмотря на кажущуюся сложность, освоить этот метод достаточно просто, кроме того, благодаря ему, Вам не придется посещать офис ведомства и отстаивать километры очередей. Сайт работает бесперебойно, открывается на любом компьютере и имеет службу поддержки для тех, кто заблудился в интерфейсе.
Интерфейс, кстати, интуитивно понятен и доступен каждому, кто хотя бы раз в жизни видел компьютер, поэтому проблем с ним у Вас возникнуть не должно.
Как получить сведения о недвижимости?
Помимо указанного способа, интересующую Вас информацию можно получить и через другие сервисы Росреестра, например, онлайн сведения об объектах недвижимости, где Вы, буквально моментально сможете узнать основные параметры здания, площадь, кадастровый номер, право собственности. Это даст Вам первичные сведения для работы, кроме того, сервис не требует платы за пользование.
Также можно воспользоваться публичной кадастровой картой, на которой можно найти любой земельный участок, при условии, что он стоит на кадастровом учете, это также полезный сервис, возможности которого позволяют не попасть в руки злоумышленников.
Дорогие посетители!
У Вас остались вопросы по услугам Росреестра и недвижимости? Мы понимаем, что каждый случай уникален и мы описываем не полное решение Вашей жилищной или земельной проблемы.
Мы рекомендуем обратиться к опытным и квалифицированным юристам по недвижимости.
Понравилась статья? Поделиться с друзьями:
Для чего нужны файлы c расширением *.CPI, *.THM, *.XML, создающиеся при записи видео в формате AVCHD/MPEG4/XAVC S и импорте в PlayMemoriesHome?
Видеокамеры и фотоаппараты, имеющие режим записи видео помимо записи непосредственно видеофайлов также создают определённую стандартами AVCHD и пр. файловую структуру на носителе. Она характеризуется обязательными набором и структурой папок, а также вспомогательными файлами, необходимыми для правильного показа видеофайлов и фото самой камерой встроенными средствами воспроизведения, организации файлов при импорте на ПК, создания AVCHD видеодисков на DVD и Blu-Ray дисках. При импорте фото и видео с камеры при помощи PlayMemories Home они отображаются в программе в удобном и организованном виде.
При импорте фото и видео с камеры при помощи PlayMemories Home они отображаются в программе в удобном и организованном виде.
Информация ниже будет полезна для тех случаев, если требуется скопировать или воспроизвести видеоролики другими способами или приложениями (например, своим медиа-проигрывателем или видеоредактором, файловым проводником)
Где располагаются сами видеоролики на носителе?
Главный признак, отличающий собственно видеофайлы от вспомогательных файлов — это размер. Видеофайлы имеют обычно размеры в несколько десятков, сотен мегебайт или несколько гигабайт. Вспомогательные файлы редко бывают больше 30 мегабайт.
- При записи в формате AVCHD видеоролики имеют расширение *.MTS и пишутся в папку \PRIVATE\AVCHD\BDMV\STREAM
- При записи в формате MPEG4 (например, Action Cam), видеоролики имеют расширение *.MP4 и пишутся в папку \MP_ROOT и подпапки. В зависимости от количества записанных роликов и того, извлекался ли носитель из камеры, может последовательно создаваться несколько подпапок вида 1xxANV01 со cквозной нумерацией.
- При записи в формате XAVC S видеоролики имеют расширение *.MP4 и пишутся в папку \PRIVATE\M4ROOT\CLIP
- Если на камере включена функция записи прокси, то прокси-клипы записываются в формате *.MP4 в папку \PRIVATE\M4ROOT\SUB
 В зависимости от количества записанных роликов и того, извлекался ли носитель из камеры, может последовательно создаваться несколько подпапок вида 1xxANV01 со cквозной нумерацией.
В зависимости от количества записанных роликов и того, извлекался ли носитель из камеры, может последовательно создаваться несколько подпапок вида 1xxANV01 со cквозной нумерацией.Большинство современных видеоредакторов и проигрывателей на компьютерах поддерживают прямое воспроизведение или импорт таких файлов простым щелчком мыши. Никакие вспомогательные данные и файлы для этого обычно не нужны.
ВАЖНО! Не рекомендуем удалять или перемещать эти файлы на носителе c помощью файлового менеджера компьютера, если вы планируете дальше использовать носитель (и записанные ранее на нём фото и видео) в камере. Это может привести к ошибкам в работе камеры с накопителем: сбоям воспроизведения, записи и определения свобного места. Также не рекомендуем форматировать носитель на компьютере. Если требуется удалить ненужные фото и видеоролики с носителя, воспользуйтесь встроенными функциями удаления (выбора конкретных ненужных фото и видео) и форматирования (полная очистка накопителя) в меню камеры.
Также не рекомендуем форматировать носитель на компьютере. Если требуется удалить ненужные фото и видеоролики с носителя, воспользуйтесь встроенными функциями удаления (выбора конкретных ненужных фото и видео) и форматирования (полная очистка накопителя) в меню камеры.
Для чего остальные типы файлов?
- *.CPI — эти файлы создаются при записи видео в формате AVCHD и содержат мета-данные (информацию) о параметрах видео- и аудиопотоков видеофайла MTS с таким же именем. Эти файлы могут использоваться домашними медиа-плеерами и при записи AVCHD видеодисков на DVD и Blu-Ray.
- *.THM — создаются при записи видео в формате MPEG4 (например, камерами Action Cam). Содержат миниатюрный эскиз видеоролика с таким же названием. Используется для быстрого отображения эскизов роликов при импорте в PlayMemories Home и при беспроводной передаче на мобильное устройство с помощью PlayMemories Mobile.
- *.XML — создаются при записи видео в формате XAVC S. Содержат подробные мета-данные о камере, параметрах съёмки и пр. видеофайла с таким же названием. Могут использоваться программами для монтажа и каталогизации видео.
- Файлы в скрытой папке \AVF_INFO — служебные файлы, составляющие базу данных о роликах и снимках на носителе для работы функции воспроизведения на камере.

Если Вы скопировали содержимое накопителя на компьютер с помощью файлового менеджера, и используете для воспроизведения файлов обычные медиа-проигрыватели (типа VLC Player или Windows Media Player), эти служебные файлы на компьютере можно безопасно удалить.
Но! Если изображения импортировались программой PlayMemories Home или аналогичным ПО для импорта и каталогизации контента, удалять их c компьютера не рекомендуется, так как это может нарушить отображение и воспроизведение файлов в этих программах. Cм. При импортировании изображений с помощью приложения PlayMemories Home создаются файлы с расширением MODD, MOFF и THM. Можно ли их удалить?
Можно ли их удалить?
ВАЖНО! Не рекомендуем удалять или перемещать эти файлы на носителе, если вы планируете дальше использовать его (и записанные ранее на нём фото и видео) в камере. Это может привести к тому, что камера «не будет видеть» и воспроизводить записанные ранее на карту ролики.
XML — Зрители — CoderLessons.com
В этой главе описываются различные методы просмотра XML-документа . Документ XML можно просмотреть с помощью простого текстового редактора или любого браузера. Большинство основных браузеров поддерживают XML. Файлы XML можно открыть в браузере, просто дважды щелкнув документ XML (если это локальный файл) или введя URL-адрес в адресной строке (если файл расположен на сервере), так же, как мы открываем другие файлы в браузере. Файлы XML сохраняются с расширением «.xml» .
Давайте рассмотрим различные методы, с помощью которых мы можем просматривать XML-файл. Следующий пример (sample.xml) используется для просмотра всех разделов этой главы.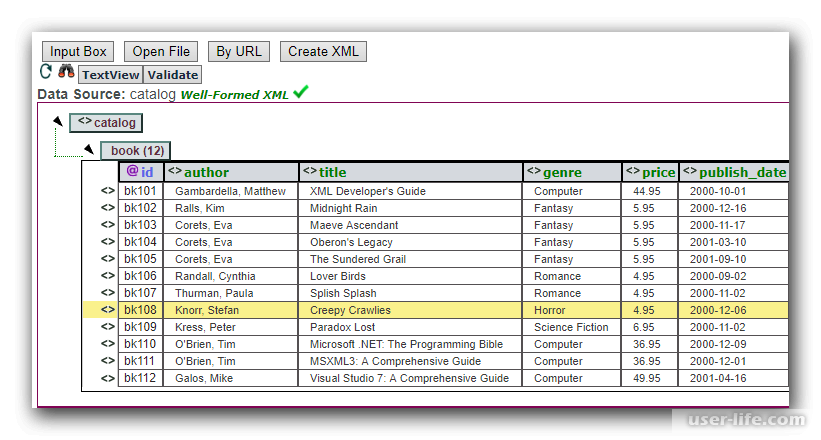
<?xml version = "1.0"?> <contact-info> <name>Tanmay Patil</name> <company>TutorialsPoint</company> <phone>(011) 123-4567</phone> </contact-info>
Текстовые редакторы
Любой простой текстовый редактор, такой как Блокнот, TextPad или TextEdit, можно использовать для создания или просмотра документа XML, как показано ниже —
Браузер Firefox
Откройте приведенный выше код XML в Chrome, дважды щелкнув файл. Код XML отображает кодирование цветом, что делает код читабельным. Он показывает знак плюс (+) или минус (-) с левой стороны в элементе XML. Когда мы нажимаем знак минус (-), код скрывается. Когда мы нажимаем знак плюс (+), строки кода расширяются. Вывод в Firefox, как показано ниже —
Браузер Chrome
Откройте приведенный выше код XML в браузере Chrome. Код отображается как показано ниже —
Ошибки в XML-документе
Если в вашем XML-коде отсутствуют какие-либо теги, в браузере отображается сообщение. Давайте попробуем открыть следующий файл XML в Chrome —
<?xml version = "1.0"?> <contact-info> <name>Tanmay Patil</name> <company>TutorialsPoint</company> <phone>(011) 123-4567</phone> </contact-info>
В приведенном выше коде начальный и конечный теги не совпадают (см. Тег contact_info), поэтому браузер отображает сообщение об ошибке, как показано ниже:
Как искать и заменять текст в XML-файле с помощью Python?
Как выполнить поиск определенного текстового шаблона во всем файле xml , а затем заменить каждое вхождение этого текста новым текстовым шаблоном в Python 3.5?
Все остальное (формат, атрибуты, комментарии и т. Д.) Необходимо оставить, как в исходном XML-файле.
Я использую Python 3.5.1 в Windows (win32).
В частности, я хотел бы заменить каждое вхождение «ИМЯ ФУНКЦИИ» на «ЭТО РАБОТАЕТ» и заменить каждое вхождение «НОМЕР ФУНКЦИИ» на «12345».
Я пытался изучить Python и xml.etree.ElementTree, но не могу этого понять. Я уже рассматривал «Найти и заменить строку в файле .xml в Python», «Найти и заменить строку в файле в Python» и «Как найти и заменить текст в файле с помощью Python?» и другие существующие вопросы и ответы на этом сайте, но не могу понять этого — я не опытный программист, поэтому, пожалуйста, дайте мне знать, если потребуется дополнительная информация. Ваша помощь очень ценится !!!
Вот копия того, как выглядит xml-код, когда я открываю его в Блокноте (за исключением того, что я добавил пробелы для отступа каждой строки и нажимал return для некоторых строк, когда вставлял его в этот вопрос):
<тема-описание>
НОМЕР ФУНКЦИИ FID
НАЗВАНИЕ ФУНКЦИИ
Общие особенности
НОМЕР ФУНКЦИИ FID
НОМЕР ФУНКЦИИ - НАЗВАНИЕ ФУНКЦИИ
<блок>
РЕЦЕНЗЕНТЫ: Я угадала НАЗВАНИЕ ФУНКЦИИ
<пара>
Эта функция применима к следующим платформам: НАЗВАНИЕ ФУНКЦИИ
<пара>
РЕЦЕНЗЕНТЫ: Что мы здесь написали? См. Шаблон (ссылка в электронном письме с обзором) для получения дополнительной информации.
<пара />
<подблок>
Какое НАЗВАНИЕ ФУНКЦИИ мы здесь указываем?
<подблок>
Какое НАЗВАНИЕ ФУНКЦИИ мы указываем здесь?
Эта функция применяется к следующему: НОМЕР ФУНКЦИИ и текст.
<подблок>
Какое НАЗВАНИЕ ФУНКЦИИ мы указываем здесь?
РЕЦЕНЗЕНТЫ: Какой НОМЕР ФУНКЦИИ мы здесь укажем?
<пара>
<комментарий />
Вот последний код, который я пытаюсь заставить работать:
из xml.etree импортировать ElementTree как et
tree = et.parse ('Atemplate2.xml')
tree.find ('description-topic / access-info / index-term-set / index-term / primary /'). text = '12345'
tree.write ('Atemplate2.xml')
Я получаю следующую ошибку: Отслеживание (последний вызов последний): Файл «ajktest18.py», строка 15, в tree.find (‘description-topic / access-info / index-term-set / index-term / primary /’). text = ‘12345’
AttributeError: объект «NoneType» не имеет атрибута «текст»
Я бы предпочел иметь возможность искать и изменять любые вхождения во всем файле, но я не могу понять, как получить хотя бы одно конкретное вхождение текста, который я ищу.
Вот код, который я пытался использовать, чтобы найти путь:
импортировать xml.etree.ElementTree как ET
tree = ET.parse ('Atemplate.xml')
корень = tree.getroot ()
печать (root.tag, root.attrib, root.text)
для ребенка в корне:
печать (child.tag, child.attrib, child.text)
для метки в root.iter ('label'):
печать (label.tag, label.attrib, label.text)
для заголовка в root.iter ('title'):
печать (title.attrib)
Я также пробовал следующий код:
с открытым ('Atemplate2.xml ') как f:
tree = ET.parse (f)
корень = tree.getroot ()
для элемента в root.getiterator ():
пытаться:
elem.text = elem.text.replace ('НАЗВАНИЕ ФУНКЦИИ', 'ЭТО РАБОТАЕТ')
elem.text = elem.text.replace ('НОМЕР ФУНКЦИИ', '12345')
кроме AttributeError:
проходить
tree.write ('output.xml')
, но это дает следующую ошибку:
Файл "", строка 2, в
tree = ET.parse (f)
Файл "C: \ MyPath \ Python35-32 \ lib \ xml \ etree \ ElementTree.py ", строка 1182, в синтаксическом анализе
tree.parse (источник, парсер)
Файл "C: \ MyPath \ Python35-32 \ lib \ xml \ etree \ ElementTree.py", строка 594, в синтаксическом анализе
self._root = parser._parse_whole (источник)
Файл "C: \ MyPath \ Python35-32 \ lib \ encodings \ cp1252.py", строка 23, в декодировании
return codecs.charmap_decode (input, self.errors, decoding_table) [0]
UnicodeDecodeError: кодек charmap не может декодировать байт 0x9d в позиции 1119: символы отображаются на
# #ОКОНЧАТЕЛЬНОЕ ОБНОВЛЕНИЕ — Вот код, который у меня в итоге сработал (спасибо, Джарад!):
импорт lxml.etree как ET
# использование lxml вместо xml сохраняет комментарии
# добавление кодировки при открытии и записи файла необходимо, чтобы избежать ошибки карты символов
с open ('filename.xml', encoding = "utf8") как f:
tree = ET.parse (f)
корень = tree.getroot ()
для элемента в root.getiterator ():
пытаться:
elem.text = elem.text.replace ('НАЗВАНИЕ ФУНКЦИИ', 'ЭТО РАБОТАЕТ')
elem.text = elem.text.replace ('НОМЕР ФУНКЦИИ', '123456')
кроме AttributeError:
проходить
# tree.write ('output.xml', encoding = "utf8")
# Добавление xml_declaration и метода помогло сохранить информацию заголовка в верхней части файла.tree.write ('output.xml', xml_declaration = True, method = 'xml', encoding = "utf8")
Анализируйте и редактируйте XML с помощью диспетчера XML UltraEdit
Анализ XML может занять много времени, особенно если у вас есть огромный набор данных или много вложенных узлов. Менеджер XML UltraEdit позволяет вам перемещаться по дереву XML, искать, перемещать узлы вверх и вниз, копировать или вырезать узлы и даже с легкостью дублировать. В этом полезном совете мы рассмотрим, как использовать менеджер XML в UltraEdit.
Откройте менеджер XML
Если диспетчер XML еще не отображается, вы можете открыть его, установив флажок Диспетчер XML на вкладке «Макет» ленты.
Если активный файл является допустимым файлом XML, менеджер XML проанализирует файл и отобразит его различные узлы и информацию.
Навигация в менеджере XML
Менеджер XML предоставляет несколько методов навигации между узлами.
Узлы развертывания / свертывания
На самом базовом уровне можно развернуть и свернуть узлы в диспетчере XML с помощью значков + и –.
Search
Вы заметите текстовое поле в верхней части менеджера XML. Вы можете ввести здесь что-нибудь и нажать Введите , чтобы найти эту строку в данных XML. Менеджер XML перейдет к первому узлу, соответствующему строке поиска. Если есть несколько совпадений, вы можете снова нажать Enter , чтобы перейти к следующему вхождению.
Навигация по файлу
Конечно, менеджер XML анализирует файл XML, но вы также можете перемещаться по файлу, дважды щелкая элементы в менеджере XML.
Редактирование файлов XML с помощью менеджера XML
Вы также можете использовать диспетчер XML для изменения и редактирования файлов XML.
Выберите узел
Если вы хотите выделить фактический текст всего узла, удерживайте нажатой клавишу Shift и дважды щелкните в менеджере XML.Это выделит весь узел в редакторе. Вы можете начать вводить текст, чтобы перезаписать его или удалить.
Перетаскивание
Вы можете изменить положение узлов XML в файле XML, щелкнув их в диспетчере XML и перетащив их в новое место.
Узел будет перемещен в позицию после узла , на который вы его поместили.
В контекстном меню диспетчера XML доступно несколько других параметров.Чтобы увидеть параметры, просто щелкните правой кнопкой мыши в диспетчере XML. Вы увидите следующие варианты:
вверх / вниз
Перемещает выбранный узел вниз в дереве XML, фактически изменяя файл XML.
Копирование / выбор
Копирует или выбирает текст узла XML.
Копировать XPath
Копирует XPath выбранного узла XML в буфер обмена. На приведенном выше снимке экрана XPath / datasets / dataset будет скопирован в буфер обмена.
Форматировать документ
Переформатирует (красиво печатает) активный файл XML, добавляя соответствующие разрывы строк и отступы.
Анализировать документ
Анализирует (или повторно анализирует) структуру XML и данные активного файла, которые заполняют диспетчер XML.
разрез
Вырезает текст выбранного узла XML из файла в буфер обмена.
Заменить буфером обмена
Заменяет выбранный узел содержимым буфера обмена.
Вставить перед
Вставляет узел в буфер обмена перед активным узлом.
Вставить после
Вставляет узел в буфер обмена после активного узла.
Дубликат
Дублирует выбранный узел под активным узлом в дереве документа.
Другие подсказки
Добавление поддержки для других типов файлов
Менеджер XML анализирует любой файл, синтаксис которого выделен как XML.UltraEdit предполагает, что файл является XML, и выделяет его как таковой, если 1) он имеет расширение файла «.xml» или 2) первая строка файла содержит идентификатор XML, например . Если в вашем файле нет ни одного из них, вам нужно либо добавить XML-идентификатор , либо добавить расширение файла к определению «Расширения файла» в XML-файле Word. Учебное пособие о том, как это сделать, доступно в этой полезной подсказке.
Если вы не хотите, чтобы тип файла постоянно анализировался как XML, вы можете временно просмотреть файл с выделением синтаксиса XML, выбрав этот тип языка в раскрывающейся строке состояния.
Исправление ошибок в файлах XML
Менеджер XML ожидает, что для анализа файла будет действительный и правильно сформированный XML-документ. Если у вас есть какие-либо ошибки в вашем XML, менеджер XML укажет, что это такое и где они находятся. Вы дважды щелкаете по ошибке, чтобы перейти к ней в файле.
Настроить менеджер XML
Вы можете настроить некоторые действия менеджера XML, щелкнув Настройки на вкладке «Дополнительно», а затем перейдя в ветвь Менеджер XML .
Работа с XML-файлами наборов данных сервера — Центр поддержки SurveyCTO
Это считается «продвинутым» навыком для работы с наборами данных сервера. Если вы не знакомы с наборами данных сервера, ознакомьтесь со статьей поддержки по использованию данных из другой формы, раздел 1 . Публикация данных в набор данных сервера.
В большинстве случаев, когда вы хотите изменить поведение набора данных сервера, вы будете Редактировать его на вкладке «Дизайн» консоли сервера.Однако есть некоторые свойства, которые нельзя изменить на вкладке «Дизайн». Когда бы вы ни захотели изменить эти свойства, вам придется удалить текущий набор данных сервера и создать новый. Вы можете воссоздать набор данных с нуля, но вы также можете отредактировать предыдущий XML-файл определения набора данных.
Что такое определение набора данных сервера?
Определение набора данных сервера определяет его свойства и поведение, включая идентификатор набора данных, заголовки столбцов, ссылки на формы, публикацию набора данных и многое другое.Однако он не хранит данные набора данных. Вы можете изменить набор данных сервера, загрузив определение набора данных и данные, удалив набор данных с сервера, отредактировав определение набора данных, а затем повторно загрузив определение набора данных и данные (мы обсудим это подробно позже).
Это изменения набора данных, при которых единственным вариантом является редактирование набора данных сервера с помощью его файла XML:
- Массовое добавление серии сопоставлений публикации наборов данных
- Изменение идентификатора набора данных (обсуждается в Сценарии 1 ниже)
- Изменить порядок столбцов
- Удаление ненужного столбца
- Если коллега отправляет вам определение набора данных, которое содержит ссылки на определения форм, которые не развернуты на вашем сервере, вы можете изменить XML-файл, удалив эти ссылки, чтобы его можно было успешно загрузить (обсуждается в Сценарий 2 ниже)
| Если вы уже начали сбор данных с помощью формы, которая использует этот набор данных сервера (например, при использовании данных из другой формы), не рекомендуется вносить изменения в набор данных сервера вручную.Если вы будете осторожны, это можно сделать безопасно, но это все равно может нарушить рабочие процессы сбора данных (например, форма попытается загрузить данные набора данных, но набора данных сервера там нет). Если вы можете терпеть набор данных сервера без этих изменений, подумайте о том, чтобы оставить его в таком состоянии, вместо того, чтобы вручную вносить изменения в определение набора данных XML. |
Структура файла XML
Это краткий обзор функций XML, которые вам понадобятся в SurveyCTO, но есть много других ресурсов, которые вы можете использовать для более подробного изучения файлов XML.
Определение набора данных сервера — это файл XML. Взгляните на этот базовый XML-файл для набора данных сервера (вы также можете скачать его здесь):
| Обычно файлы XML проще просматривать в редакторе кода, таком как Notepad ++ для Windows или BBEdit для Mac. Это также упростит определение номеров строк, на которые часто ссылаются в этой статье. Но вы также можете использовать что-то более простое, например Блокнот для Windows или TextEdit для Mac.(Если вам удобны более продвинутые инструменты, вы можете использовать Visual Studio Code.) |
Теги
Одна из самых важных частей XML — это теги. Они определяют, когда элемент запускается и останавливается. Имена тегов вводятся между угловыми скобками < и > . Например, в приведенном выше примере тег находится в строке 2.
Элементы
XML-элемента содержат данные. Элементы начинаются с начального тега и заканчиваются конечным тегом, и они включают все, что находится между ними.Основное визуальное различие между начальным тегом и конечным тегом заключается в том, что конечный тег начинается с косой черты / после первой угловой скобки. Например, тег в строке 14 является конечным тегом элемента , который начинается в строке 2. Этот начальный тег, этот конечный тег и все, что между ними, является частью этого элемент.
Вы также можете иметь элементы внутри элементов. Например, в элементе , охватывающем строки 2–14, есть другой элемент с именем , охватывающий строки 3–10.Вы заметите, что он заканчивается в строке 10, поскольку там используется закрывающий тег с косой чертой в начале.
Элементы также могут быть пустыми, то есть у них нет содержимого. Они определяются наличием косой черты в конце тега, прямо перед угловой скобкой, а не в начале. Например, тег в строке 8 заканчивается косой чертой, поскольку это пустой тег, поскольку для этого набора данных сервера не определены ссылки на формы.
Текст элемента
Элементы также могут содержать текст. Например, элемент в строке 4 содержит текст «example_server_dataset», поскольку это идентификатор формы набора данных сервера.
XML-файлы определения набора данных
В этом разделе содержится ссылка на набор данных сервера, использованный в статье о примере управления делами, в частности на XML-файл определения набора данных, который можно загрузить, щелкнув здесь .
Набор данных сервера определяется в файле XML с помощью элементов.Если вы измените элементы, вы измените внешний вид и поведение набора данных сервера.
Основы
id : уникальный идентификатор набора данных сервера. Используется в выражениях pulldata () и search () при предварительной загрузке данных для идентификации набора данных.
title : Удобный заголовок набора данных сервера.
datasetType : Тип набора данных. Это никогда не должно изменяться.
fieldNames : список заголовков столбцов, разделенных запятыми.Если вы хотите изменить порядок столбцов или удалить столбец, вы можете сделать это здесь. Например, если вы загрузили приведенный выше пример набора данных сервера под XML-файловые структуры на свой сервер, заголовки столбцов будут в следующем порядке: id_key, имя, возраст, пол, семейное положение . Однако, если вы хотите, чтобы пол был указан перед возрастом, вы можете изменить его на id_key, имя, пол, возраст, семейный статус .
Ссылки на формы
XML-файл также определяет, какие формы присоединяются к набору данных сервера, определенному в элементе .
Каждая форма, прикрепленная к набору данных сервера (т.е. каждая форма, которая предварительно загружает данные из набора данных сервера), определяется в элементе . Для каждой прикрепленной формы есть элемент (отличный от тега с буквой «s»), а внутри этих элементов находится элемент . Внутри этого элемента находится идентификатор формы, прикрепленной к набору данных сервера.
Например, в примере XML-файла определения набора данных, если вы взглянете на строки 10, 13 и 16, вы увидите, что определения форм с идентификаторами «Complaint_followup», «school_form» и «water_usage» имеют этот набор данных сервера прикреплен к ним для предварительной загрузки.
Каналы передачи данных
Публикация набора данных определяется в элементе . Здесь определяется как публикация в наборе данных сервера (например, публикация из формы), так и публикация из набора данных сервера (например, во внешний лист Google).
Для каждой формы, которая публикует набор данных сервера или из него, в элементе . В этом элементе есть множество других элементов, используемых для определения публикации:
dataLinkClass : это тип файла, который подключается к набору данных сервера для публикации. Например, значение будет «FORM», если данные публикуются из формы, «SPREADSHEET», если они публикуются в таблице Google, и так далее.
dataLinkType : публикуются ли данные с по набор данных сервера (ВХОДЯЩИЙ) или публикуются из набора данных сервера в другое место (ИСХОДЯЩИЙ).
linkObjectId : идентификатор файла или формы, которые публикуются в или из. Если это форма, то это будет идентификатор формы; если это таблица Google, это будет идентификатор файла на Google Диске.
fieldMap : какие поля или столбцы должны публиковаться в какие столбцы.Это формат JSON, поэтому он начинается и заканчивается фигурной скобкой, каждое сопоставление полей разделяется запятой, а какие поля публикуются, где указывается двоеточием. Например, взгляните на это сопоставление полей из строки 32 примера, где форма с идентификатором «Complaint_followup» публикуется в наборе данных сервера (были добавлены пробелы, чтобы ее было легче читать):
{"caseid": "id", "new_visit_num": "visit_num", "new_severity": "severity", "new_severity_en": "severity_enumerator"} Здесь поле «caseid» формы публикуется в столбце «id», поле «new_visit_num» публикуется в столбце «visit_num» и так далее.
joiningField : поле, используемое для идентификации строк. При настройке публикации набора данных на сервере это поле формы для идентификации уникальных записей . Например, в строке 33 примера определено как «caseid». Таким образом, на основе сопоставления полей при отправке формы, если значение поля «caseid» совпадает со значением в столбце «id» набора данных сервера, новые данные будут опубликованы в этой строке. Если значение поля «caseid» не существует в столбце «id», данные будут добавлены как новая строка.Это должно быть поле, определенное в fieldMap .
релевантное поле : поле, используемое для определения того, когда данные должны быть опубликованы. Если это поле имеет значение 1, то оно инициирует публикацию; в противном случае данные не будут опубликованы. При настройке публикации набора данных на сервере это поле указано в поле Включить отправку формы, если это поле равно 1 . Это не обязательно должно быть поле, определенное в fieldMap .
| Вы не можете загрузить XML-файл набора данных сервера на сервер, пока есть ссылки на формы или ссылки на данные для форм, которые не развернуты.Итак, когда вы знаете, как определять ссылки на формы и данные, вы можете удалить их из файла XML перед загрузкой файла. В качестве примера см. Сценарий 2 ниже. |
Варианты ведения дел
Они определены в теге . Чтобы узнать больше об управлении делами, ознакомьтесь с нашим руководством по ведению дел, особенно в части 3.
displayMode : Как меню управления делами будет отображаться сборщикам данных в виде «дерева» или «таблицы».
showFinalizedSentWhenTree : Если это значение «истина», а displayMode - «дерево», когда формы помечены как завершенные или отправленные, то список завершенных и отправленных форм будет выделен зеленым цветом. Если это значение «false», то они не будут отображаться вообще. Это ничего не делает, если displayMode является «table».
showColumnsWhenTable : Когда displayMode имеет значение «table», это список столбцов, который будет отображаться в меню управления делами.Имя каждого столбца должно быть между тегами , поэтому между тегами и .
Изменение файла XML
Вообще говоря, намного проще изменить набор данных сервера на вкладке «Дизайн» консоли сервера. Но вы также можете изменить поведение набора данных сервера, изменив файл XML. Чтобы изменить набор данных, сначала загрузите XML-определение набора данных и данные, удалите набор данных с сервера, внесите необходимые изменения в XML-файл, а затем загрузите XML-файл на сервер вместе с CSV-файлом.Вот эти шаги в разбивке:
- На вкладке «Дизайн» консоли сервера перейдите к набору данных сервера, который вы хотите изменить.
- Для этого набора данных сервера щелкните Загрузить , затем щелкните одновременно Загрузить данные и Определение набора данных , чтобы загрузить данные и определение набора данных. Убедитесь, что данные набора данных CSV и определение набора данных XML были успешно загружены.
- После того, как вы подтвердите, что у вас есть и определение набора данных, и данные, удалите набор данных с сервера.
- Откройте файл XML в текстовом редакторе.
- При необходимости измените файл XML.
- Сохраните файл.
- На вкладке «Дизайн» серверной консоли щелкните слева + (плюс), затем Добавить набор данных сервера .
- Щелкните вкладку Новый набор данных из определения .
- Менее Выберите файл определения для загрузки , щелкните Выберите файл , выберите и откройте XML-файл определения набора данных.
- Нажмите Загрузить определение набора данных .
- Во всплывающем окне с сообщением «Набор данных успешно создан» нажмите OK .
- Когда определение набора данных было успешно загружено, нажмите его кнопку Загрузить .
- В разделе Файл с новым содержимым набора данных (файл .csv) щелкните Выберите файл .
- Выберите и откройте файл данных набора данных CSV.
- Оставьте Приложить выбранным и нажмите Загрузить .
- Во всплывающем окне «Набор данных успешно изменен» нажмите OK .
Чтобы узнать больше о загрузке и выгрузке наборов данных сервера, ознакомьтесь с нашей статьей поддержки о работе между серверами.
| Убедитесь, что вы не удалили определение набора данных, пока сбор данных еще активен. Дождитесь периода «отдыха», когда счетчики больше не будут отправлять данные на сервер, поскольку в противном случае не будет набора данных сервера для публикации. Вы также можете сообщить всем счетчикам, чтобы они прекратили отправку данных (или остановили сбор данных в целом) в указанное время, чтобы вы могли использовать это время для удаления старого набора данных сервера и загрузки нового. |
Упражнения
Здесь мы проведем вас через некоторые упражнения, чтобы вы могли практиковать то, что вы узнали. Это оба реальных сценария, с которыми вы можете столкнуться с набором данных сервера.
Сценарий 1. Изменение идентификатора набора данных сервера
У вас есть набор данных сервера с идентификатором «example_server_dataset», но вы хотите изменить его на «респондент_данные». Таким образом, когда вы ссылаетесь на него в выражении pulldata () или search () определения формы, вам будет легче понять, о чем идет речь.Щелкните здесь, чтобы загрузить определение набора данных.
- Откройте XML-файл набора данных сервера в текстовом редакторе.
- Выберите содержимое между тегами
- Измените это на «респондент_данные».
- Сохраните файл.
- Загрузите определение набора данных на свой сервер.
- Убедитесь, что ID набора данных, который вы только что загрузили, теперь имеет значение «респондент_данные».
Совет. Хотя это единственный способ изменить идентификатор набора данных, вы можете легко изменить заголовок набора данных с помощью кнопки Переименовать набора данных сервера на вкладке «Дизайн».
Сценарий 2. Удаление прикрепленной формы
Коллега отправил вам определение набора данных, которое будет использоваться в будущем опросе (чтобы загрузить файл, откройте ссылку и щелкните значок загрузки в правом верхнем углу). Однако это определение формы содержит для определения формы, которое не развернуто на вашем собственном сервере. Вы не можете загрузить набор данных на свой сервер, пока эта ссылка на форму не будет удалена (или пока на вашем сервере не будет развернуто определение формы с этим идентификатором формы).Загрузите определение набора данных здесь.
- Откройте XML-файл набора данных сервера в текстовом редакторе.
- Прокрутите до элемента
- Выберите элемент
- Удалить этот раздел.
- Сохраните файл и загрузите его на свой сервер.
Пустой элемент считается в точности таким же, как .При желании вы можете заменить пустые теги на более упрощенный пустой тег, но это не обязательно. |
Есть ли у вас мысли по поводу этой статьи поддержки? Нам бы очень хотелось их услышать! Не стесняйтесь заполнить эту форму обратной связи.
Углубленный взгляд на JSON и XML, часть 1: История каждого
Практически все компьютерные приложения, которые мы используем сегодня, от настольных компьютеров до Интернета и мобильных устройств, полагаются на один из двух основных стандартов сообщений: JSON и XML.Сегодня JSON является наиболее широко используемым форматом, но он обогнал XML только за последние пять лет. Быстрый поиск в Интернете по запросу «JSON vs. XML» принесет бесчисленное количество статей и сообщений в блогах, в которых сравниваются эти два стандарта, что приводит к постоянно растущему предубеждению, восхваляющему простоту JSON и критикующему многословие XML. Во многих статьях утверждается, что JSON превосходит XML из-за своей краткой семантики, и не признают XML как неэффективного и сбивающего с толку стандарта прошлого. На первый взгляд, JSON кажется наиболее популярным. Так что, JSON лучше, чем XML? Битва «JSON vs.XML »может обращаться к JSON на поверхности, но на глубине это больше, чем кажется на первый взгляд.
В части 1 этой статьи мы будем:
- Присмотритесь к истории Интернета, чтобы раскрыть первоначальное предназначение XML и JSON.
- Рассмотрим эволюцию программных тенденций в последние годы, чтобы понять, почему JSON стал более популярным, чем XML.
История JSON и XML
Чтобы раскрыть причину популярности JSON по сравнению с XML, давайте исследуем историю Интернета и его эволюцию от Интернета 1.0 для Web 2.0 повлияли на тенденции развития.
Интернет 1.0: HTML
Начало 1990-х было рассветом Web 1.0. HTML был представлен в 1991 году и был широко принят университетами, предприятиями и государственными организациями в качестве языка Интернета. HTML произошел от SGML, или «стандартного обобщенного языка разметки», изобретенного IBM в 1970-х годах. В дополнение к массовому внедрению , HTML получил массовую адаптацию - расширения были встроены для поддержки мультимедиа, анимации, онлайн-приложений, электронной коммерции и многого другого.Будучи производным от SGML, HTML не обладал строгой спецификацией, чтобы компании не могли свободно расширять его для выполнения требований, выходящих за рамки первоначальной концепции. Соревнование между Netscape и Microsoft за самый популярный веб-браузер привело к быстрому прогрессу, но также привело к неумолимой фрагментации стандарта. Жестокая конкуренция привела к «катастрофе расхождения», поскольку расширение HTML двумя компаниями заставило браузеры поддерживать свои собственные уникальные версии HTML.Эта катастрофа расхождения стала огромной проблемой для веб-приложений, поскольку разработчики изо всех сил пытались написать совместимый код для браузеров.
Интернет 1.1: XML + HTML = XHTML
В конце 1990-х группа людей, включая Джона Босака, Тима Брея, Джеймса Кларка и других, придумала XML: «расширяемый язык разметки». Как и SGML, XML сам по себе не является языком разметки, а является спецификацией для определения языков разметки. XML был развитием SGML и был разработан, чтобы предоставить средства для определения и обеспечения соблюдения структурированного контента.Считающийся «святым Граалем вычислений» 1 язык XML пытался «решить проблему универсального обмена данными между разнородными системами» (д-р Чарльз Гольдфарб) 2 . Вместо продолжающейся фрагментации HTML был сформирован Комитет по всемирной паутине (W3C), чтобы способствовать совместимости и соглашению между отраслью при принятии новых стандартов для всемирной паутины. 3 W3C приступил к преобразованию HTML в приложение XML, в результате чего получился XHTML.
XHTML был большой инициативой, которая привлекла внимание к XML, но это лишь небольшая часть того, что такое XML.
XML предоставил отрасли возможность со строгой семантикой указать настраиваемые языки разметки для любого приложения. С ключевым словом «строгая семантика» XML определил стандарт, который мог утверждать целостность данных в любом XML-документе на любом подъязыке XML. Для компаний-разработчиков программного обеспечения, разрабатывающих распределенные корпоративные приложения, которые взаимодействуют с разнородными системами, язык разметки, который мог утверждать целостность своих данных, имел большое значение.Определяя структурированный контент с помощью XML, компании использовали возможности этой технологии для взаимодействия с любой платформой, обеспечения целостности данных при каждом обмене данными и систематического снижения риска программного обеспечения своих систем. Для отрасли XML предоставил технологию для хранения, передачи и проверки любых данных в форме, которую приложения на любой платформе могут легко читать и обрабатывать. Что касается HTML, XML обещал решить «катастрофу дивергенции».
Java и.НЕТТО
В начале 2000-х годов Интернетом управляли две компании: Sun и Microsoft. В то время ландшафт языков программирования сильно склонялся к серверной стороне. Общая архитектура для веб-приложений основывалась на серверах, отображающих HTML-страницы на серверной части для доставки в браузер. Этот подход выдвинул на первый план внутренние технологии, которые, в свою очередь, популяризировали ведущие серверные платформы: Java и C # .NET. Java, разработанная Sun Microsystems, возглавила новое поколение объектно-ориентированных языков программирования, которые решили проблему кросс-архитектуры с помощью своего нового подхода «напиши один раз, запускай где угодно» 4 .Microsoft последовала за .NET, C # и Common Language Runtime (CLR) и обратила внимание на XML как на подход к выбору решения загадки совместимости данных. Microsoft стала главным сторонником XML, выбрав XML как неотъемлемую часть своей выдающейся инициативы .NET. Рекламируемые как «платформа для веб-служб XML» 5 .NET-приложения были спроектированы так, чтобы использовать XML для связи с другими платформами. Выбранный в качестве стандарта обмена данными Microsoft, XML был интегрирован в ее флагманские серверные продукты, такие как SQL Server и Exchange.
Интернет 1.2: AJAX
Доставка предварительно обработанных HTML-страниц в браузер не масштабировалась, и Интернету требовалась альтернатива. С каждым действием пользователя, требующим загрузки новой страницы с сервера, нагрузка на процесс и потребление полосы пропускания становились проблемой, поскольку все больше людей раздували Интернет.
Netscape и Microsoft пытались решить эту проблему с помощью асинхронной доставки контента: ActiveX и JavaScript. В 1998 году группа Microsoft Outlook Web Access разработала концепцию ActiveX 6 , которая позже была реализована в Mozilla, Safari, Opera и других браузерах на JavaScript как объект XMLHttpRequest .
AJAX родился на основе ActiveX от Microsoft и JavaScript от Netscape.
Термин AJAX - сокращение от «Асинхронный JavaScript и XML» - стал обозначать широкий спектр веб-технологий, которые можно использовать для реализации веб-приложений, которые взаимодействуют с серверами в фоновом режиме, не требуя перезагрузки страницы. В статье, в которой был введен термин AJAX, 7 8 Джесси Джеймс Гарретт изложил основные концепции:
- HTML (или XHTML) и CSS для презентации.
- Объектная модель документа (DOM) для динамического отображения данных и взаимодействия с ними.
- XML для обмена данными и XSLT для управления ими.
- Объект
XMLHttpRequestдля асинхронной связи. - JavaScript для объединения этих технологий.
Благодаря тому, что асинхронная доставка контента снижает нагрузку на сервер и значительно экономит полосу пропускания, AJAX кардинально изменил правила игры. Введение XMLHttpRequest в браузеры позволило разработчикам реализовать более сложную логику во внешнем интерфейсе.Google широко развернул совместимый со стандартами кроссбраузерный AJAX с Gmail в 2004 году и Google Maps в 2005 году. 9 А в октябре 2004 года публичная бета-версия Kayak.com стала одной из первых крупномасштабных версий использования AJAX в электронной коммерции. . 10
Интернет 2.0: одностраничные приложения
Принятие AJAX в качестве масштабируемой архитектуры для веб-приложений привело к возникновению Web 2.0: одностраничного приложения (SPA). 11 Вместо перезагрузки всей страницы при каждом взаимодействии с пользователем, SPA динамически перезаписывают текущую страницу в браузере.В дополнение к значительному снижению нагрузки на сервер и использования полосы пропускания подход SPA позволил веб-приложениям напоминать настольные приложения благодаря плавному и непрерывному взаимодействию с пользователем.
В апреле 2002 года Стюарт Моррис написал один из первых СПА на slashdotslash.com 12 , а позже в том же году Лукас Бирдо, Кевин Хакман, Майкл Пичи и Эван Йе описали реализацию одностраничного приложения в патенте США 8,136,109. . 13 В патенте описаны веб-браузеры, использующие JavaScript для отображения пользовательского интерфейса, выполнения логики приложения и связи с веб-сервером.
Gmail, Google Карты и общедоступная бета-версия Kayak от Google открыли новую эру в разработке веб-приложений. Браузеры с поддержкой AJAX давали разработчикам возможность писать многофункциональные приложения для Интернета. Простая семантика JavaScript сделала возможной разработку приложений для программистов любого уровня подготовки. Барьер для входа в разработку программного обеспечения был значительно сокращен, и отдельные разработчики по всему миру начали вносить свой вклад, создавая собственные библиотеки и фреймворки. Популярные библиотеки, такие как jQuery, которые нормализуют поведение AJAX в браузерах разных производителей, продолжили революцию AJAX.
Расцвет JSON
В апреле 2001 года Дуглас Крокфорд и Чип Морнингстар отправили первое сообщение в формате JSON с компьютера в гараже Morningstar’s Bay Area. Крокфорд и Морнингстар пытались создавать приложения AJAX задолго до появления термина «AJAX», но поддержка браузером того, чего они пытались достичь, была не очень хороша. Они хотели передать данные в свое приложение после загрузки страницы, но не нашли способа, чтобы это работало во всех браузерах.
В 2001 году разработка AJAX только начиналась, а в Internet Explorer 5 и Netscape 4 еще не было интероперабельной формы объекта XMLHttpRequest . Таким образом, Крокфорд и Морнингстар использовали другой подход, который работал в обоих браузерах.
Первое сообщение JSON выглядело так:
Это сообщение на самом деле является HTML-документом, содержащим некоторый JavaScript, и лишь небольшая часть сообщения похожа на JSON в том виде, в каком мы его знаем сегодня.Крокфорд и Морнингстар смогли загрузить данные асинхронно, указав