База данных людей | Онлайн база данных
Обратите внимание, в нашем сервисе нет данных о войне и данных про оккупированные территории. Если Вы ищете родственников, Национальная полиция Украины открыла круглосуточную горячую линию для родственников погибших в результате военных действий. Номер горячей линии – 0 894 201 867.
Scanbe.io агрегирует данные из открытых источников, чтобы дать возможность быстро найти нужного человека в открытых базах данных. Мы ежедневно обрабатываем десятки миллионов записей, чтобы наши пользователи тратили минимум времени на поиск нужной информации. Вы используете один сервис вместо десятков реестров.
Для проверки фона человека по открытым реестрами введите данные человека (фамилия и имя) и сервис найдет совпадения. Вы можете дополнить поиск людей регионом или отчеством человека. Некоторые реестры содержат только фамилию и инициалы человека (например, Богданов И.
Перед использованием сервиса, пожалуйста, ознакомьтесь с перечнем реестров выше и ответами на частые вопросы ниже.
Есть ли в сервисе данные паспортов и идентификационные коды физических лиц?
Данные паспортов и идентификационные коды защищены Законом Украины «Про защиту персональных данных». Сервис использует только открытые данные, которые не защищены Законом Украины «Про защиту персональных данных». Открытые данные не содержат данные паспортов и идентификационные коды. Даты рождения есть в двух реестрах по розыску людей.
Как узнать суммы долгов?
Сервис показывает факт наличия долгов из Единого реестра должников, судебные заседания (с 2015 года) и открытые налоговые долги.
Суммы долгов и алиментов по исполнительному производству — это конфиденциальная информация, которая доступна только участникам исполнительного производства.
Как посмотреть все штрафы человека?
Сервис показывает факт наличия штрафов или долгов из Единого реестра должников. В реестр заносят данные по факту задолженности об уплате, например, штрафов. Если штраф уплачен вовремя, сервис его не покажет.
Как узнать долги человека перед банками?
Долги физических лиц перед банками – это конфиденциальная информация. Сервис не показывает долги частных лиц перед банками.
Вы можете узнать факт наличия долга перед банком в декларациях государственных служащих, которые обязаны декларировать кредиты и другие финансовые обязательства.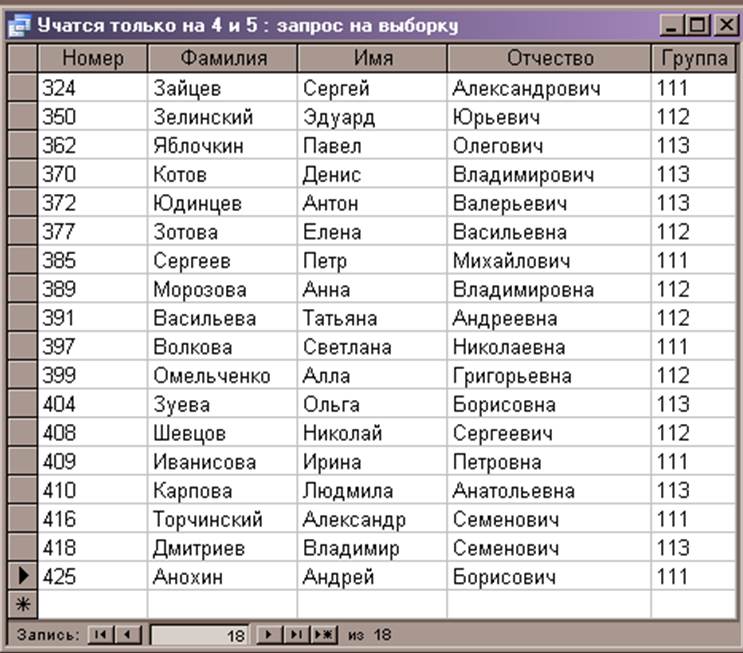 Или из данных судебных заседаний, если банк или другое фин. учреждение подало в суд на человека. Эти данные в сервисе доступны.
Или из данных судебных заседаний, если банк или другое фин. учреждение подало в суд на человека. Эти данные в сервисе доступны.
Я могу узнать платежи или сумму долга перед налоговой?
Сервис показывает открытые данные налоговых долгов из реестра «Информация о субъектах хозяйствования, которые имеют налоговый долг». Текущие платежи перед налоговой — это не публичная информация, ее нет в нашем сервисе.
Вы также можете узнать факт наличия судебного процесса по факту задолженности, если такой судебный процесс есть или был (данные доступны с 2015 года).
Я могу узнать судимости человека?
Данных о судимостях человека в открытом виде нет. Вы можете узнать является ли человек участником судебного процесса (данные доступны с 2015 года).
В базе розыска находятся все люди, которые объявлены в розыск?
Сервис ищет в реестрах «Информация о лицах, скрывающихся от органов власти» и «Информация о без вести пропавших гражданах». Это публичные базы данных для розыска. Базы розыска содержат более 100 тыс. записей (включая историю розыска).
В правоохранительных органах есть непубличные базы розыска, которые используют для оперативных действий. Например, для оперативного поиска преступников. Они не являются публичными, так как могут помешать оперативным мероприятиям. Этих реестров у нас нет.
Ваши услуги платные?
Да, ссылка на отчет приходит на почту сразу после приобретения одного из тарифов. Доступные тарифы на странице Тарифы. Обратите внимание, мы рекомендуем покупать один из тарифов только если найдены совпадения в реестрах.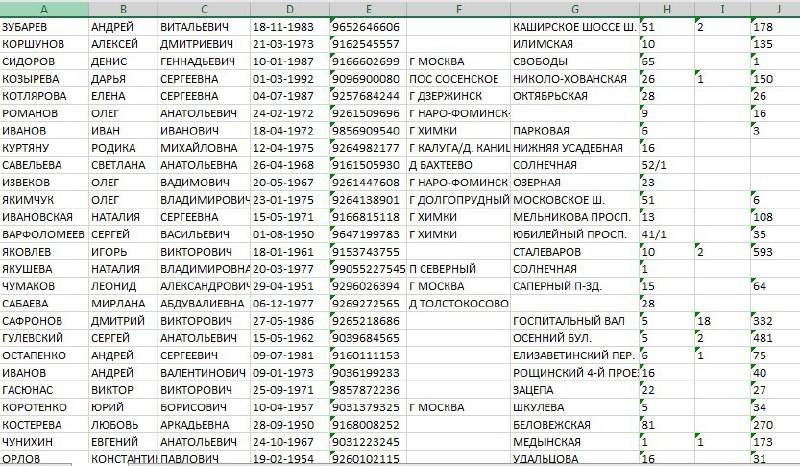
Почему ваши услуги платные?
Scanbe.io агрегирует данные из открытых источников, чтобы дать возможность быстро найти нужного человека в открытых базах данных. Мы ежедневно обрабатываем десятки миллионов записей, работаем над улучшением технологии поиска, скорости обработки данных и удобства сервиса в целом. Чтобы наши пользователи тратили минимум времени на поиск нужной информации.
Над Scanbe.io работает команда, проект нуждается в ресурсах, чтобы оплачивать счета для поддержки и развития сервиса. Поэтому наши услуги платные.
Покажет ли сервис недвижимое имущество человека?
Сервис показывает недвижимое имущество человека (квартиру, дом или земельный участок), которое зарегистрировано после 2003 года. В описи имущества можно увидеть находится ли имущество в ипотеке. Данные поступают из Государственного реестра вещных прав на недвижимое имущество.
В описи имущества можно увидеть находится ли имущество в ипотеке. Данные поступают из Государственного реестра вещных прав на недвижимое имущество.
Вы также можете увидеть задекларированное имущество государственных служащих и совместное владение имуществом с родственниками, партнерами и т.д.
Как узнать замужем/женат человек? Как узнать жив ли человек?
Эта категория данных не является публичной информацией. Обратитесь в органы регистрации актов гражданского состояния.
Есть ли у вас данные прописки человека?
Публикация прописки человека запрещена Законом Украины о «Защите персональных данных», распространение этих данных запрещено. Домашние адреса и прописка не являются открытыми данными, адреса человека доступны в нескольких реестрах:
Реестр недвижимости — если у человека есть недвижимость (с 2003 года),
Реестр физических лиц-предпринимателей,
Реестр юридических лиц (адреса учредителей и конечных бенефициаров).
Есть ли у вас суммы алиментов?
Суммы алиментов не являются открытым данным, у нас нет сумм алиментов. Вы можете проверить является ли человек должником в Едином реестре должников или были у человека судебные процессы (доступно с 2015 года). Если есть исполнительное производство, Вам необходимо обратиться к специалисту, который выполняет данное производство.
Есть ли у вас данные о пересечении границы?
Данные о пересечении границы не являются открытыми, их нет в нашем сервисе.
Возможна фильтрация результатов по дате рождения?
Открытые данные не содержат дат рождений, эти данные защищены Законом Украины «О защите персональных данных», их публикация запрещена.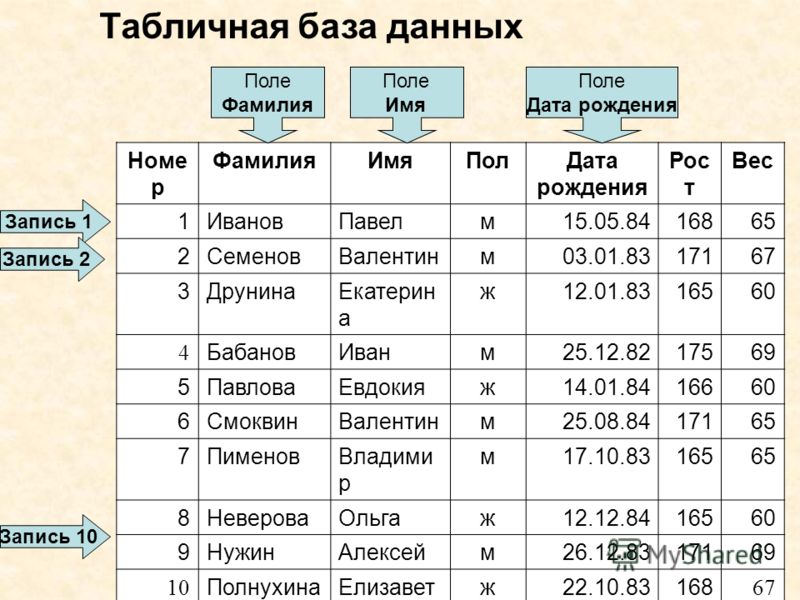 Фильтрация по дате рождения пока невозможна.
Фильтрация по дате рождения пока невозможна.
Вы разблокируете карты и счета?
Мы не администрируем данные по блокировке карт. Вам необходимо обратиться к специалисту, который выполняет данное производство. Вы можете найти исполнительное производство на нашем сайте.
Использование критерия Like для поиска данных
Access
Запросы
Простые запросы
Простые запросы
Использование критерия Like для поиска данных
Access для Microsoft 365 Access 2021 Access 2019 Access 2016 Access 2013 Access 2010 Access 2007 Еще…Меньше
Условия или оператор Like используются в запросе для поиска данных, которые соответствуют определенному шаблону. Например, в нашей базе данных есть таблица «Клиенты», как по примеру ниже, и нам нужно найти только клиентов, живущих в городах, названия которых начинаются с «B». Вот как мы создадим запрос и будем использовать условия Like:
Вот как мы создадим запрос и будем использовать условия Like:
-
Откройте таблицу
«Клиенты»:
-
На вкладке Создание нажмите кнопку Конструктор запросов.
-
Нажмите кнопку «Добавить», и таблица «Клиенты» будет добавлена в конструктор запросов.
-
Дважды щелкните поля «Фамилия»и «Город», чтобы добавить их в сетку конструктора запросов.
 org/ListItem»>
org/ListItem»>
В поле «Город» добавьте условия «Нравится B*» и нажмите кнопку «Выполнить».
В результатах запроса будут отбираться только клиенты из названий городов, названия которых начинаются с буквы «B».
Дополнительные информацию об использовании критериев см. в этой теме.
К началу страницы
Если вы предпочитаете синтаксис SQL (язык SQL), вот как это сделать:
-
Откройте таблицу «Клиенты» и на вкладке «Создание» нажмите кнопку «Конструктор запросов».
 org/ListItem»>
org/ListItem»>
На вкладке «Главная» нажмите кнопку «> SQL», а затем введите следующий синтаксис:
SELECT [Last Name], City FROM Customers WHERE City Like “B*”;
-
Щелкните Выполнить.
-
Щелкните вкладку запроса правой кнопкой мыши и выберите > «Закрыть».
Дополнительные сведения см. в SQL Access: основные понятия, лексика и синтаксис, а также о том, как изменять SQL для более четкого получения результатов запроса.
К началу страницы
Примеры шаблонов условий Like и результатов
Условия или оператор Like удобны при сравнении значения поля с строкным выражением. Следующий пример возвращает данные, которые начинаются с буквы P, за которой идут любая буква от A до F и три цифры:
Следующий пример возвращает данные, которые начинаются с буквы P, за которой идут любая буква от A до F и три цифры:
Like “P[A-F]###”
Вот несколько способов использования like для различных шаблонов:
|
|
|
Если ваша база данных имеет |
Если в базе данных нет |
|
Несколько символов |
а*а |
аа, aБa, aБББa |
aБВ |
|
*aб* |
aбв, AAББ, Цaб |
aШб, бaв |
|
|
Особые символы |
а[*]а |
а*а |
Ааа |
|
Несколько символов |
aб* |
aбвгдеё, aбв |
вaб, aaб |
|
Один символ |
а?а |
ааа, а3а, aБa |
aБББa |
|
Одна цифра |
а#а |
а0а, а1а, а2а |
ааа, а10а |
|
Диапазон символов |
[a-я] |
д, о, и |
2, & |
|
Вне диапазона |
[!a-я] |
9, &, % |
б, a |
|
Не цифра |
[!0-9] |
А, а, &, ~ |
0, 1, 9 |
|
Смешанный |
a[!б-л]# |
Aм9, aя0, a99 |
aбв, aи0 |
Примеры условия «Нравится» с поддиавными знаками
В следующей таблице показаны типы результатов, если критерий «Нравится» используется с подстановочные знаки в таблице, которая может содержать данные с определенными шаблонами.
|
Условия |
Результат |
|
Like «E#» |
Возвращает элементы с двумя знаками, в которых первый символ — E, а второй — числом. |
|
Like «G?» |
Возвращает элементы с двумя знаками, у которых первый символ — G. |
|
Like «*16» |
Возвращает элементы, заканчивающийся на 16. |

См. другие примеры поддеревных знаков.
К началу страницы
c# — поиск похожих имен людей в базе данных
Существует множество возможных проблем, которые необходимо учитывать при сопоставлении имен. Вот некоторые из них:
- прозвищ (Боб — Роберт)
- опечатки
- замена имени (фамилия заменена именем)
- девичья фамилия
- инициалы
- усеченных имен
- фонетически похожее имя (Дженнифер — Дженни)
Расстояние Дамерау–Левенштейна — это один из алгоритмов редактирования расстояния, которые вы можете использовать. Каждый алгоритм учитывает разные операции (вставка символов, замена, удаление, замена и т. д.), и ни один из них не идеален, но каждый обеспечивает расстояние между двумя строками.
Вам нужно решить, какая ошибка для вас приемлема (т. е. отсечка для положительных совпадений). Пример, который вы привели, включает минимум 7 операций. При таком количестве операций многие имена вернут одно и то же расстояние.
е. отсечка для положительных совпадений). Пример, который вы привели, включает минимум 7 операций. При таком количестве операций многие имена вернут одно и то же расстояние.
При сравнении имен вы должны попытаться сделать обе стороны сопоставимыми, нормализовав их: если, например, на одной стороне есть только первая буква имени, вы должны сделать то же самое и на другой стороне, чтобы алгоритм расстояния редактирования дал вам лучший результат.
Точно так же вы можете избавиться от отчества, если другая сторона не имеет отчества (и вы можете игнорировать случаи, когда отчество вводится как имя). Но лучшая альтернатива — сгенерировать все возможные пары «имя-фамилия», используя все слова, доступные в имени, и посмотреть, даст ли какая-либо из пар лучшее расстояние редактирования. Вы также можете сравнить каждое слово отдельно и найти лучшую комбинацию слов с лучшим результатом (компромисс заключается в игнорировании опечаток на границах слов).
Вам также следует рассмотреть возможность использования алгоритма фонетического сходства, такого как Двойной метафон, в дополнение к алгоритму Дамерау–Левенштейна, и сгенерировать комбинированный балл. Фонетический алгоритм разработан для конкретной языковой семьи и пытается определить, будут ли оба имени звучать одинаково в этой языковой семье. Результат сам по себе ненадежен (по крайней мере, мой опыт был таким), но это в сочетании с алгоритмом расстояния редактирования улучшит ваше сопоставление.
Фонетический алгоритм разработан для конкретной языковой семьи и пытается определить, будут ли оба имени звучать одинаково в этой языковой семье. Результат сам по себе ненадежен (по крайней мере, мой опыт был таким), но это в сочетании с алгоритмом расстояния редактирования улучшит ваше сопоставление.
Чтобы уменьшить количество ошибок, следует учитывать дополнительные элементы данных, такие как ZIP, DOB и т. д.
В конце концов, все дело в компромиссах: ваш предполагаемый вариант использования, допустимый порог для положительных совпадений, качество ваших данных, ограничения времени/стоимости и т. д. Например: вы можете просто потребовать первую букву имя и первая буква фамилии должны совпадать в дополнение к расстоянию Дамерау–Левенштейна. Это уменьшит количество ложных срабатываний за счет игнорирования опечаток в первых буквах.
Как и во многих других вещах в наши дни, я думаю, что наилучший результат в этой области может быть достигнут с помощью хорошо обученной модели машинного обучения. Я некоторое время не работал в этой области, поэтому я не уверен, что там есть, но вы, вероятно, могли бы найти хорошее облачное решение для наилучшего качества, конечно, за определенную плату, если это важно для вас.
Я некоторое время не работал в этой области, поэтому я не уверен, что там есть, но вы, вероятно, могли бы найти хорошее облачное решение для наилучшего качества, конечно, за определенную плату, если это важно для вас.
Вы можете просмотреть обзор методов сопоставления имен здесь для дальнейшего чтения.
строка — как получить базу данных всех имен людей (или хотя бы английских распространенных)?
спросил
Изменено 7 лет, 6 месяцев назад
Просмотрено 4к раз
Я разрабатываю приложение, которое должно извлекать имена людей из коротких текстов.
Как лучше всего это сделать? есть ли база данных имен, где я могу проверить, где это имя? тот факт, что текст короткий, может быть не таким интенсивным с точки зрения потребностей в обработке.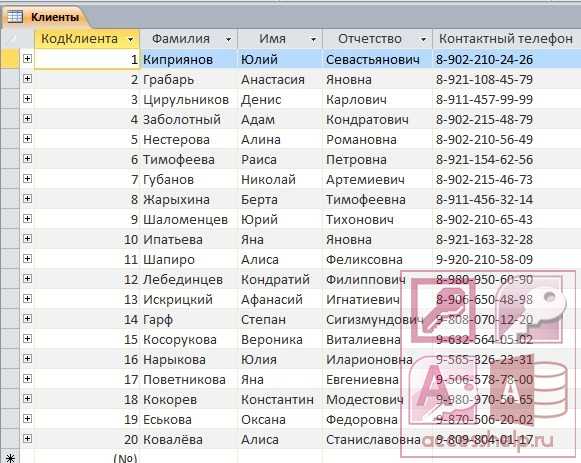
Есть идеи?
Спасибо,
Тэм
- строка
Вы можете использовать статистический распознаватель именованных объектов (NER), такой как NER Стэнфорда или LingPipe. Это распознаватели на основе машинного обучения, которым не требуются огромные словари имен в качестве входных данных.
Кроме того, вы можете получить список имен людей из Интернета (их много) и использовать алгоритм поиска строк Ахо-Корасика для эффективного извлечения имен из списка из текста.
Если вы работаете в системе *nix, попробуйте просмотреть /usr/share/dict/propernames . В Mac OS X он есть, и я думаю, по крайней мере, в Ubuntu тоже.
Вы можете использовать это с grep :
grep -f /usr/share/dict/propernames short_text.txt1
Я нашел эту ссылку: Извлечение имен людей из RSS-каналов с помощью WordNet
1 Получить набор данных имени:
Я сделал набор наборов данных для таких задач. Вы можете использовать мои наборы данных здесь: https://mbejda.github.io. Все они в формате CSV. Имена классифицируются по расе и полу.
Вы можете использовать мои наборы данных здесь: https://mbejda.github.io. Все они в формате CSV. Имена классифицируются по расе и полу.
Распознаватель именованных объектов:
Посмотрите OpenNLP или StanfordNLP для распознавания именованных объектов и извлечения.
Как насчет генеалогических данных Бюро переписи населения США
0Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google Зарегистрироваться через Facebook Зарегистрируйтесь, используя электронную почту и парольОпубликовать как гость
Электронная почтаТребуется, но не отображается
Опубликовать как гость
Электронная почтаТребуется, но не отображается
Нажимая «Опубликовать свой ответ», вы соглашаетесь с нашими условиями обслуживания и подтверждаете, что прочитали и поняли нашу политику конфиденциальности и кодекс поведения.
Ваш комментарий будет первым