Трансформаторные подстанции 35/0,4 кВ открытого типа
ПРИМЕНЕНИЕ
Комплектная трансформаторная подстанция открытого типа (КТП-С 35/0,4 кВ) предназначена для приема, преобразования и распределения электрической энергии трехфазного переменного тока промышленной частоты 50 Гц, для электроснабжения сельскохозяйственных объектов, нефтегазовых месторождений, отдельных населённых пунктов, небольших промышленных объектов и прочих потребителей электроэнергии.
ТЕХНИЧЕСКИЕ ПАРАМЕТРЫ ПОДСТАНЦИИ
| Распределительное устройство | ||
| ВН | НН | |
| Номинальное напряжение | 35 кВ | 0,4 кВ |
| Максимальное рабочее напряжение | 40,5 кВ | 0,69 кВ |
| Номинальный ток | до 20 А | до 1200 А |
| Номинальная частота | 50 Гц | |
| Мощность трансформатора | от 25 кВА до 630 кВА | |
| Габариты подстанции (зависят от мощности силового трансформатора) | 2500х4550х6050 мм (ШхДхВ) | |
| Комплектация | Разъединитель РДЗ. 1-35/1000 УХЛ1 (воздушный ввод) 1-35/1000 УХЛ1 (воздушный ввод)Система обогрева РУ 0,4 кВ Система внутреннего и внешнего освещения Связи: Разъединитель – Трансформатор – РУ 0,4 кВ | |
КТП-С 35/0,4 кВ представляет собой металлоконструкцию, которая позволяет расположить оборудование подстанции на двух уровнях, тем самым уменьшая занимаемую ей площадь и обеспечивая визуальный контроль за высоковольтным оборудованием.
На первом уровне металлоконструкции располагается шкаф РУ 0,4 кВ, на втором – силовой трансформатор, предохранители, ОПН и высоковольтный разъединитель. Оперативные блокировки и защитные ограждения обеспечивают безопасную и удобную эксплуатацию подстанции.
Подстанция КТПН-100-10-0,4 кВ (комплектная наружная)
| Наименование товара | Производство | Схема подключения | Заказ | |
|---|---|---|---|---|
| КТПН-100/10/0,4 | Собственное | Оформить заявку | ||
Производство КТПН 100/10/0,4
КТПН рассчитана на мощность 100 кВА, номинальное напряжение УВН — 10 кВ. Электроустановку располагают в металлическом корпусе, который предотвращает попадание воды и твердых предметов. Каркас выполнен из стальных пластин, которые скрепляют болтами. Оболочку пропитывают химическими составами для защиты металла от коррозионного разрушения.
Электроустановку располагают в металлическом корпусе, который предотвращает попадание воды и твердых предметов. Каркас выполнен из стальных пластин, которые скрепляют болтами. Оболочку пропитывают химическими составами для защиты металла от коррозионного разрушения.
В комплект подстанции входят:
- понижающий трансформатор;
- соединительные шины и кабельные линии;
- шкаф распределительного устройства и линии отвода;
- устройство ввода энергии;
- техническая документация: руководство по эксплуатации, сертификат соответствия, паспорт.
Силовой трансформатор понижает напряжение высоковольтных ЛЭП до сетевых значений потребителей. Токоведущие части заземляют и покрывают изоляцией. Установку располагают во взрывобезопасной среде. Содержание агрессивных газов в атмосфере не должно превышать нижних концентрационных пределов.
Для защиты РУНН от короткого замыкания устанавливают разрядники и блокирующие выключатели.
| Номинальное напряжение, кВ: | Значение параметра | ||
|---|---|---|---|
| — на стороне ВН | 10 | ||
| — на стороне НН | 0,23; 0,4 | ||
| Номинальный ток термической стойкости в течении 1 секунды, кА: | |||
| — на стороне ВН | не менее 16 | ||
| — на стороне НН | не менее 20 | ||
| Номинальный ток электродинамической стойкости, кА: | |||
| — на стороне ВН | не менее 41 | ||
| — на стороне НН | не менее 50 | ||
| Температура окружающего воздуха | от минус 45°С до плюс 40°С | ||
| Степень защиты | IР23 | ||
| Климатическое исполнение и категория размещения | У1, УХЛ1 |
| Признаки классификации | Исполнение | ||
|---|---|---|---|
| По конструктивному исполнению | в утепленном блок-боксе | столбовая | |
| По электрической схеме на стороне ВН | тупиковая | проходная | тупиковая |
| По способу установки | стационарная, передвижная (на полозьях) | стационарная | |
| По числу применяемых силовых трансформаторов | однотрансформаторная | двухтрансформаторная | однотрансформаторная |
| По выполнению Высоковольтного ввода | воздушный, кабельный | воздушный | |
| По выполнению вводов отходящих линий на стороне НН | воздушный, кабельный | воздушный, кабельный | |
| По выполнению нейтрали трансформатора на стороне НН | с глухозаземленной нейтралью, с изолированной нейтралью (по специальному заказу) | ||
Индексы Мосбиржи и РТС за январь снизились на 0,4% и 1,4% — Экономика и бизнес
МОСКВА, 29 января. /ТАСС/. Индекс Мосбиржи за январь 2021 года потерял около 0,4%, завершив последнюю основную торговую сессию месяца на отметке 3 277,08 пункта, индекс РТС за месяц упал на 1,4%, остановившись на 1 367,64 пункта, свидетельствуют данные торгов. Доллар за то же время вырос примерно на 1,4%, евро — на 0,15%.
/ТАСС/. Индекс Мосбиржи за январь 2021 года потерял около 0,4%, завершив последнюю основную торговую сессию месяца на отметке 3 277,08 пункта, индекс РТС за месяц упал на 1,4%, остановившись на 1 367,64 пункта, свидетельствуют данные торгов. Доллар за то же время вырос примерно на 1,4%, евро — на 0,15%.
По итогам последнего торгового дня месяца индекс Мосбиржи снизился на 1,94%, РТС — на 1,23%. Рубль в пятницу укрепился — доллар по состоянию на 19:33 мск снизился на 0,32%, до 75,63 рубля, евро — на 0,32%, до 91,82 рубля.
Инвесторы начали фиксировали прибыль, не дождавшись позитива. Кроме того, к концу торгового дня ухудшился и внешний фон, считает инвестиционный стратег «БКС мир инвестиций» Александр Бахтин. «Компания Johnson & Johnson обнародовала слабые результаты эффективности вакцины от COVID-19 — в среднем 66%. Так, повлиять на рыночный сентимент не смогла и неплохая макростатистика — лучше ожиданий вышли немецкие статданные по безработице за декабрь и оценка ВВП за четвертый квартал 2020 года, а также данные по расходам и доходам граждан США в декабре», — рассказал эксперт.
В лидерах роста на торгах в пятницу оказались акции ПИК (+4,11%), ЛСР (+1,17%) и «Детского мира» (+1,31%). Бумаги компаний строительного сектора растут в преддверии назначенного на 12 февраля заседания по ключевой ставке Банка России, отметил аналитик «Фридом финанс» Александр Осин. «Динамика финансовых показателей сектора в последние кварталы стала значительно сильнее зависеть от изменения процентных ставок в связи с ростом доли ипотеки в продажах до уровней более 60% -70%. Тем самым, ситуация, возможно, отражает ожидания на рынке смягчения кредитной политики ЦБ в феврале», — пояснил эксперт.
В пятницу под заметным давлением оказались бумаги «Новатэка» (-4,03%) и генерирующих компаний — акции «Россетей» просели на 4,01%. Также заметное снижение продемонстрировали бумаги «Норильского никеля» (-3,36%).
«На акции «Норникеля» в пятницу дополнительное давление оказывали новости о неготовности Росприроднадзора идти на компромисс с компанией в споре о размере штрафа за экологический урон.
Прогноз на понедельник
Риск-аппетиты в начале будущей недели стабилизируются, покупатели могут начать выкупать подешевевшие активы после просадки, так как для формирования более масштабной коррекции причин сейчас нет, считает Бахтин. «В выходные выйдут январские PMI в производственном и непроизводственном секторах КНР, в понедельник картину дополнит индекс деловой активности в производственном секторе Поднебесной от Caixin. Инвесторы также оценят производственные PMI за первый месяц года Германии, США, Великобритании. PMI обрабатывающих отраслей РФ за январь представит в понедельник и Росстат», — добавил эксперт.
Прогнозный диапазон «БКС мир инвестиций» по индексу Мосбиржи на понедельник — 3 250-3 350 пунктов, по курсу рубля к доллару — 74,8-76 рубля.
Осин, напротив, считает, что в понедельник преобладают шансы снижения рынка. Целевые диапазоны закрытия первого торгового дня следующей недели по оценкам «Фридом финанс» для индекса Мосбиржи и курсов доллара и евро к рублю составляют 3 260-3 340 пунктов, а также 75,25 — 76,1 рубля и 91,05 — 92,1 рубля соответственно.
Целевые диапазоны закрытия первого торгового дня следующей недели по оценкам «Фридом финанс» для индекса Мосбиржи и курсов доллара и евро к рублю составляют 3 260-3 340 пунктов, а также 75,25 — 76,1 рубля и 91,05 — 92,1 рубля соответственно.
vMix Clock и опции таймера
Вы можете использовать vMix для добавления всех видов часов, таймеров, обратных отсчетов и дат в вашу продукцию, которые будут автоматически обновляться!
Чтобы добавить один из этих элементов реального времени, вам необходимо следовать правильному синтаксису — {0: DATETIMESTRING}
Не беспокойтесь, если вы этого не понимаете, у нас есть множество примеров на этой странице, которые вы можете использовать и адаптировать к своей продукции! Полный список элементов, которые можно использовать в строке времени, можно найти по этой ссылке —
.Вот несколько примеров, которые можно использовать и с которыми можно экспериментировать!
| Что это? | Код vMix | Как выглядит |
| Время суток 24 часа 00-24 | {0: ЧЧ: мм: сс} | 20:05:00 |
| Время суток 24 часа 0-24 | {0: H: мм: ss} | 15:05:00 |
| Что это такое? | Код vMix | Как выглядит |
| Время суток 12 час 00-12 | {0: чч: мм: сс} | 09:15:00 |
| Время суток 12-часовой формат 0-12 | {0: ч: мм: сс} | 9:15:00 |
Если вам не нужны секунды, вы можете просто удалить: ss из любого из перечисленных выше.
Например, {0: ЧЧ: мм} отобразит что-то вроде 15:33
Чтобы добавить доли секунды, вы можете добавить к строке
| Что это такое? | Код vMix | Как выглядит |
| Добавление десятых долей секунды | {0: ЧЧ: мм: сс.f} | 20: 15: 00.0 |
| Добавление сотых секунды | {0: ЧЧ: мм: сс.ff} | 20: 15: 00.00 |
Вы можете добавить AM / PM, используя «tt» в строке.
| Что это? | Код vMix | Как выглядит |
| Время суток 12-часовой формат (0-12) с AM PM | {0: h: мм tt} | 15:15 |
Если вы хотите отсчитать время до определенного времени, вы можете сделать следующее:
{0: ENDDATETIME | DATETIMESTRING}
Где ENDDATETIME — дата / время, когда обратный отсчет должен отображать 0.
| Что это? | Код vMix | Как выглядит |
| Обратный отсчет до 15:00 | {0: 15: 00 PM | ЧЧ: мм: сс} | Показывает, сколько времени осталось до 15:00 |
Дополнительные параметры обратного отсчета можно установить, оставив текст пустым и используя функцию обратного отсчета в vMix.
Если вы хотите добавить дату, вы можете попробовать что-нибудь из следующего —
| Что это? | Код vMix | Как выглядит |
| Показывает дату (в правильном направлении) | {0: дд / ММ / гг} | 21-12-18 |
| Показывает дату (по США) | {0: ММ / дд / гг} | 12-21-18 |
| Показывает дату и время! | {0: дд / мм / гг Ч: мм: сс} | 21-12-18 16:35:16 |
Вы даже можете написать дату вот так —
| Что это? | Код vMix | Как выглядит |
| Показать все! | {0: дддд ММММ д, гггг} | Пятница, 21 декабря 2018 г. |
Доступно множество различных опций, поэтому просмотрите ссылку Microsoft вверху и начните создавать свои часы реального времени!
Двойные шплинты HH с цинковым покрытием
Прочные, прочные и долговечные — Двойные шплинты HH фиксируются быстро и надежно, с легким захватом для быстрого снятия.
- Доступны размеры от 3/16 «до 7/16»
- Подходит для пальцев категории 0-3 верхней тяги и пальца подъемного рычага
- Оцинковка желтого цвета для дополнительной прочности
Стандартная упаковка = 100 штук
LYNCHPIN (фиксатор)
| Номер детали | Описание | Категория | Полезная длина | Длина хвостовика | Общая длина | Вес |
| 21910 | 3/16 «Lynchpin | 0 | 1-1 / 8″ | 1-3 / 8 « | 1-5 / 8″ | 0.03 |
| 21915 | Штифт 3/16 «с цепью 12» | 0 | 1-1 / 8 « | 1-3 / 8″ | 1-5 / 8 « | 0,14 |
| 21914 | 3/16 «Lynchpin | 0 | 1-3 / 8″ | 1-1 / 2 « | 2″ | 0,03 |
| 21930 | 5/16 «Lynchpin | 1, 2 | 1-7 / 16 « | 1-3 / 4″ | 2-1 / 8 « | 0,07 |
| 21935 | 5/16″ Lynchpin с цепью 12 « | 1 , 2 | 1-7 / 16 « | 1-3 / 4″ | 2-1 / 8 « | 0. 18 18 |
| 21932 | 5/16 «Lynchpin с термообработкой | 1, 2 | 1-1 / 2″ | 2-1 / 4 « | 2-3 / 4″ | 0,09 |
| 21933 | 5/16 «Lynchpin с термообработкой | 1, 2 | 1-3 / 4″ | 2-1 / 4 « | 2-3 / 4″ | 0,10 |
| 21938 | 7/16 «Lynchpin | 1, 2, 3 | 1-1 / 2″ | 2 « | 2-7 / 16″ | 0.11 |
| 21940 | 7/16 «Lynchpin | 1, 2 | 1-1 / 2″ | 1-3 / 4 « | 2″ | 0,11 |
| 21945 | 7 / Штифт 16 «с цепью 12» | 1, 2 | 1-1 / 2 « | 1-3 / 4″ | 2 « | 0,21 |
| 21960 | 7/16″ Lynchpin с Кольцо для тяжелых условий эксплуатации | 1, 2, 3 | 1-1 / 2 « | 1-3 / 4″ | 2-1 / 8 « | 0.13 |
| 21923 | 1/4 «Lynchpin с термообработкой | 1 | 1-5 / 16″ | 2-1 / 4 « | 2-1 / 2″ | 0,06 |
| 21922 | 1/4 «Штифт с термообработкой | 1 | 1-3 / 8″ | 1-3 / 4 « | 2″ | 0,06 |
| 21920 | 1/4 «Lynchpin | 1 | 1-7 / 16 « | 1-3 / 4″ | 2-1 / 8 « | 0,05 |
| 21925 | 1/4″ Lynchpin с цепью 12 « | 1 | 1 -7/16 « | 1-3 / 4″ | 2-1 / 8 « | 0. 16 16 |
Стандартная упаковка = 1 сумка
LYNCHPIN — СТАНДАРТНАЯ УПАКОВКА ()
| Номер детали | Категория | Диаметр вала | Полезная длина | Длина хвостовика | Общая длина | штук в пакете | Вес |
| 41910 | 0 | 3/16 « | 1-1 / 8″ | 1-3 / 8 « | 1-5 / 8″ | 2 | 0.06 |
| 41912 | 0 | 3/16 « | 1-1 / 8″ | 1-3 / 8 « | 1-5 / 8″ | 10 | 0,32 |
| 41920 | 1 | 1/4 « | 1-7 / 16″ | 1-3 / 4 « | 2-1 / 8″ | 10 | 0,50 |
| 41921 | 1 | 1 / 4 « | 1-7 / 16″ | 1-3 / 4 « | 2-1 / 8″ | 2 | 0,10 |
| 41922 | 1 | 1/4 « | 1 -7/16 « | 1-3 / 4″ | 2-1 / 8 « | 5 | 0. 25 25 |
| 41930 | 1, 2 | 5/16 « | 1-7 / 16″ | 1-3 / 4 « | 2-1 / 8″ | 2 | 0,14 |
| 41932 | 1 | 5/16 « | 1-7 / 16″ | 1-3 / 4 « | 2-1 / 8″ | 10 | 0,69 |
| 41938 | 1, 2, 3 | 7/16 « | 1-1 / 2″ | 2 « | 2-7 / 16″ | 2 | 0.22 |
| 41939 | 1, 2, 3 | 7/16 « | 1-1 / 2″ | 2 « | 2-7 / 16″ | 10 | 1.10 |
| 41940 | 1, 2 | 7/16 « | 1-1 / 2″ | 1-3 / 4 « | 2″ | 10 | 1,10 |
| 41941 | 1, 2 | 7 / 16 « | 1-1 / 2″ | 1-3 / 4 « | 2″ | 2 | 0,22 |
| 41942 | 1, 2 | 7/16 « | 1-1 / 2 « | 1-3 / 4″ | 2 « | 5 | 0. 55 55 |
| 41945 | 1, 2 | 7/16 « | 1-1 / 2″ | 1-3 / 4 « | 2″ | 5 | 1.03 |
| 41947 | 1, 2 | 7/16 « | 1-1 / 2″ | 1-3 / 4 « | 2″ | 2 | 0,41 |
| 41960 | 1, 2, 3 | 7 / 16 « | 1-1 / 2″ | 1-3 / 4 « | 2-1 / 8″ | 2 | 0,26 |
| 41962 | 1, 2, 3 | 7/16 « | 1-1 / 2″ | 1-3 / 4 « | 2-1 / 8″ | 10 | 1.30 |
| 41965 | 1, 2, 3 | 7/16 « | 1-1 / 2″ | 1-3 / 4 « | 2-1 / 8″ | 5 | 0,65 |
Стандартная упаковка Clamshell = 1 упаковка
LYNCHPIN — СТАНДАРТНАЯ УПАКОВКА CLAMSHELL ()
| Номер детали | Категория | Диаметр вала | Полезная длина | Длина хвостовика | Общая длина | штук в упаковке | Вес |
| 31910 | 0 | 3/16 « | 1-1 / 8″ | 1-3 / 8 « | 1-5 / 8″ | 4 | 0. 13 13 |
| 31920 | 1 | 1/4 « | 1-7 / 16″ | 1-3 / 4 « | 2-1 / 8″ | 4 | 0,20 |
| 31925 | 1 с цепью | 1/4 « | 1-7 / 16″ | 1-3 / 4 « | 2-1 / 8″ | 2 | 0,38 |
| 31930 | 1 , 2 | 5/16 « | 1-7 / 16″ | 1-3 / 4 « | 2-1 / 8″ | 4 | 0.28 |
| 31940 | 1, 2 | 7/16 « | 1-1 / 2″ | 1-3 / 4 « | 2″ | 4 | 0,55 |
| 31945 | 1, 2 с цепью | 7/16 « | 1-1 / 2″ | 1-3 / 4 « | 2″ | 2 | 0,41 |
| 31960 | 1 | 7 / 16 « | 1-1 / 2″ | 1-3 / 4 « | 2-1 / 8″ | 2 | 0,26 |
| 31938 | 1, 2, 3 | 7/16 » | 1-1 / 2 « | 2″ | 2-7 / 16 « | 4 | 0. 44 44 |
Флаговая бирка Стандартная упаковка = 100 штук
LYNCHPIN — СТАНДАРТНАЯ УПАКОВКА FLAG TAG ()
| Номер детали | Категория | Диаметр вала | Полезная длина | Длина хвостовика | Общая длина | Вес |
| 81911 | 0 | 3/16 « | 1-1 / 8″ | 1-3 / 8 « | 1-5 / 8″ | 0.03 |
| 81922 | 1 | 1/4 « | 1-7 / 16″ | 1-3 / 4 « | 2-1 / 8″ | 0,05 |
| 81933 | 1 , 2 | 5/16 « | 1-7 / 16″ | 1-3 / 4 « | 2-1 / 8″ | 0,07 |
| 81944 | 1, 2 | 7/16 « | 1-1 / 2″ | 1-3 / 4 « | 2″ | 0,11 |
Проверить канал в стиле HH
Проверить канал в стиле HHШаг 4.Протестируйте канал
Мы можем протестировать наш новый канал, выполнив «виртуальный эксперимент по выбору и спасению».
Опытный образец
Примените короткий надпороговый стимул к модельной ячейке в двух «контрольных» и двух «тестовых» условиях.
- Control 1 — Модель имеет только механизм hh.
Прогноз: это должно вызвать нормальный всплеск. - Элемент управления 2 — Модель имеет и hh, и myna, но gmax_myna равно 0
(аналогично вставке «гена myna», но не его экспрессии).
Прогноз: это должно вызвать всплеск, идентичный тому, что был замечен в Контрольном пункте 1. - Тест 1 — Модель имеет и hh, и myna, но оба gnabar_hh и gmax_myna равны 0
(аналогично нокаутной мутации, затрагивающей натриевые каналы hh).
Прогноз: скачка быть не должно. - Тест 2 — Модель имеет и hh, и myna, но gnabar_hh равно 0, а gmax_myna равно 0,12 См / см 2 (натриевые каналы чч все еще «выбиты», но майна теперь выражена).
Прогноз: Это должно «спасти» шип.Кроме того, если myna правильно реализована, реакция этой модели на вводимый ток должно быть идентично тому, что произошло в двух контрольных экспериментах.

Control 1 — Модель имеет только механизм hh.
- 1. Сделайте однокамерную модель с hh.
- Дайте модели площадь поверхности 100 мкм 2 .
NEURON Главное меню / Сборка / одно отделение
Одно отделение / чч - 2. Вызовите RunControl.
- NEURON Главное меню / Инструменты / RunControl
Установить Tstop = 10 мс - 3. Подключите токовый стимул для подачи импульса 0,1 нА x 0,1 мс, начиная с 1 мс.
- NEURON Главное меню / Инструменты / Процессы точек / Менеджеры / Менеджер точек
PointProcessManager / SelectPointProcess / IClamp
PointProcessManager / Показать / Параметры
Установить del = 1 мс, dur = 0,1 мс, amp = 0,1 нА - 4. Постройте график зависимости мембранного потенциала от времени.
- NEURON Главное меню / График / Ось напряжения
- 5.Нажмите «Инициировать и запустить» на панели «Управление запуском».
- Импульс тока должен запускать потенциал нормального действия.
Перед проведением следующего эксперимента сохраните все в файл сеанса с именем control1.ses.
Элемент управления 2 — Модель имеет и hh, и myna, но gmax_myna равно 0. (аналогично вставке «гена myna», но не его экспрессии).
Начните с модели, которую вы использовали для Control 1.
- 1. Добавьте механизм майны.
- Одноквартирный / майна
- 2. «Заблокируйте выражение майны».
- Уменьшите gmax_mna до 0.
Это можно сделать произвольно, но легче отслеживать, что происходит. если вы управляете параметрами модели с помощью панели Parameters. Чтобы открыть панель параметров —- NEURON Главное меню / Инструменты / Распределенные механизмы / Средства просмотра / Имя формы.
вызывает окно параметров раздела. Это показывает фигурку ячейки на левой панели, и список названий разделов на его правой панели. - На правой панели окна Параметры раздела дважды щелкните «soma».
Появится панель параметров сомы.
(теперь вы можете закрыть окно параметров сечения)
- NEURON Главное меню / Инструменты / Распределенные механизмы / Средства просмотра / Имя формы.
- 3. Запустите моделирование.
- Подтверждает или опровергает этот результат предсказание?

Сохраните все в файл сеанса с именем control2.ses
Тест 1 — Модель имеет и hh, и myna, но оба gnabar_hh и gmax_myna равны 0 (аналогично нокаутной мутации, затрагивающей натриевые каналы hh).
Начните с модели, которую вы использовали для Control 2.
- 1. «Выбить натриевые каналы».
- Используйте панель параметров сомы, чтобы изменить gnabar_hh на 0. Оставьте gmax_myna равным 0.
- 2. Запустите моделирование.
- Это предсказанный результат?
Сохраните все в файл сеанса под названием test1.ses
Тест 2 — Модель имеет как hh, так и myna,
но gnabar_hh равно 0, а gmax_myna равно 0,12 См / см 2 (натриевые каналы чч все еще «выбиты», но майна теперь выражена).
Начните с модели, которую вы использовали для Теста 1.
- 1. «Экспресс майна».
- Используйте панель параметров сомы, чтобы изменить gmax_myna на 0,12 См / см2. Оставьте gnabar_hh равным 0.
- 2. Запустите моделирование.
- Эта линия напряжения идентична линиям управления?
Вот пример полного графического интерфейса, который строит модель, управляет симуляцией и отображает результаты.Толстый красный след был получен контрольными 1 и 2, и тонкий синий след, который покрывает его, был создан Тестом 2.
Это ссылка на hhchnltest.hoc,
который вы можете использовать для воссоздания этого рисунка (на самом деле это сеанс
файл, но его расширение было изменено на «hoc», чтобы его можно было запускать из WWW).
И этот файл, и полностью настроенный hhchannel.ses
включены в заархивированный архив этого руководства.
[Схема | Предыдущий ]
Авторские права © 2004-2006 Н.Т. Карневале и М.Л. Хайнс, Все права Зарезервированный.
Brady® HH-0-SC-PK | Черепаха и Хьюз
Маркерная карта проводов Brady®, предварительно напечатанный сплошной номер, серия: HH, длина маркера 3/4 дюйма, ширина маркера 1/4 дюйма, обозначение маркера: 0, черный / белый, ацетатная ткань B-12
| Маркер Легенда | : | 0 |
| Длина маркера | : | 3/4 дюйма |
| Ширина маркера | : | 1/4 дюйма |
| Тип | : | Предварительно отпечатанный сплошной номер с высечкой |
| Материал | : | B-12 Ацетатная ткань |
| Серии | : | Серия HH |
| Легенда / Цвет фона | : | Черный на белом |
| Маркеров на карту | : | 72 |
- Каталог https: // www. turtle.com//ASSETS/DOCUMENTS/ITEMS/EN/Brady_WM_1_33_SC_PK_Catalog.pdf
- Техническая спецификация https://www.turtle.com//ASSETS/DOCUMENTS/ITEMS/EN/Brady_WM_1_33_SC_PK_Datasheet.pdf
 turtle.com//ASSETS/DOCUMENTS/ITEMS/EN/Brady_WM_1_33_SC_PK_Catalog.pdf
turtle.com//ASSETS/DOCUMENTS/ITEMS/EN/Brady_WM_1_33_SC_PK_Catalog.pdf- Маркировщики проводов серии
- HH маслостойкие и термостойкие
- Матовое покрытие
- Маркировщики проводов, устанавливаемые на карту
- Диапазон температур 105 ° C
- 0.008 толщиной
| Шаблон формата | Описание |
|---|---|
| d,% d | День месяца. Однозначные дни не имеют нуля в начале. Приложение указывает «% d», если шаблон формата не сочетается с другими шаблонами формата.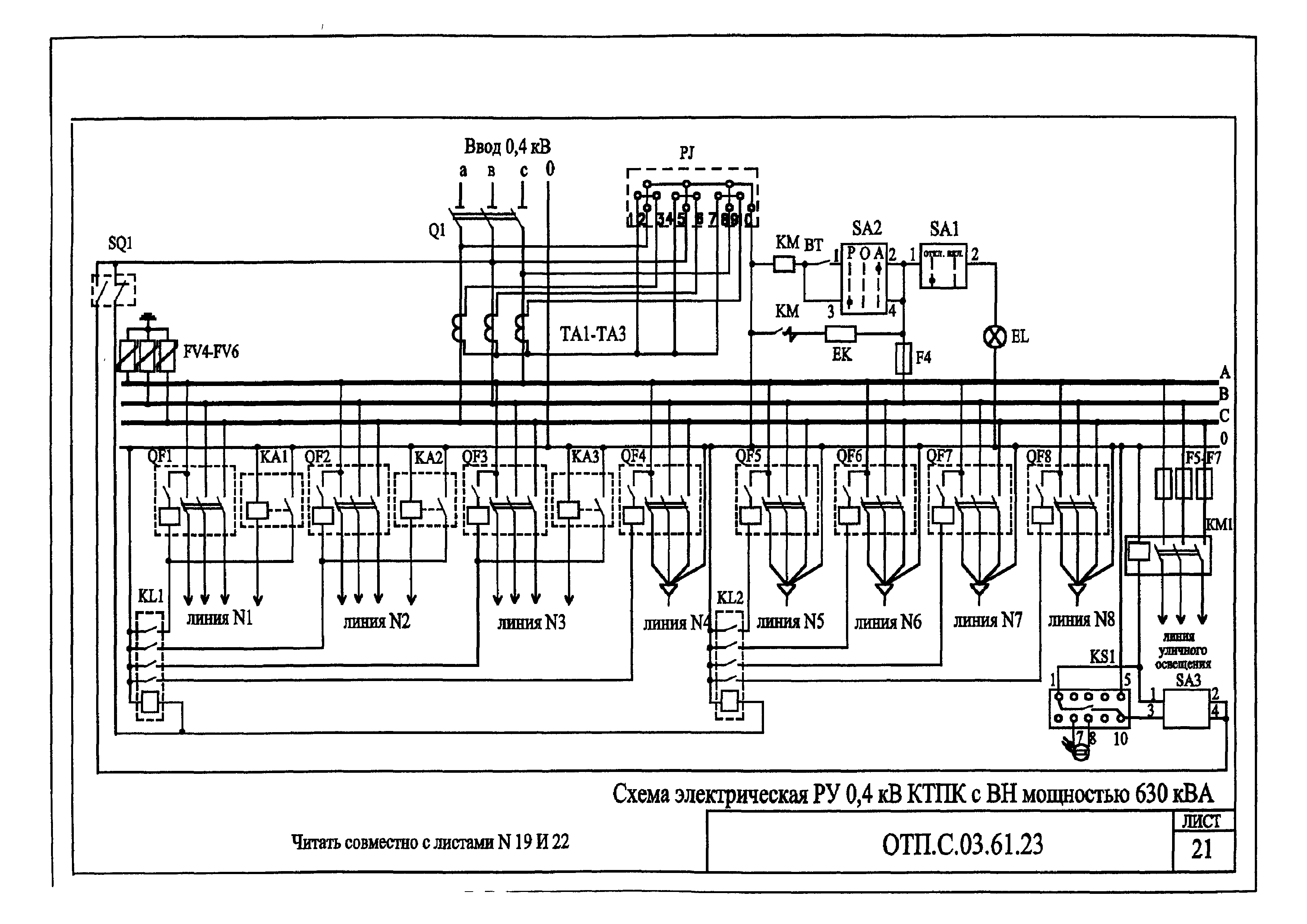 |
| dd | День месяца. Однозначные дни начинаются с нуля. |
| ddd | Сокращенное название дня недели (строка, зависящая от языка и региональных параметров) |
| dddd | Полное название дня недели (строка, зависящая от языка и региональных параметров) |
| f,% f | Доля секунды при однозначной точности. Остальные цифры усечены. Приложение указывает «% f», если шаблон формата не сочетается с другими шаблонами формата. |
| ff | Доля секунды с двузначной точностью.Остальные цифры усечены. |
| fff | Доля секунды с трехзначной точностью. Остальные цифры усечены. |
| ffff | Доля секунды с четырехзначной точностью. Остальные цифры усечены. |
| fffff | Доля секунды с пятизначной точностью. Остальные цифры усечены. |
| ffffff | Доля секунды с шестизначной точностью. Остальные цифры усечены. Остальные цифры усечены. |
| fffffff | Доля секунды с семизначной точностью. Остальные цифры усечены. |
| F,% F | Отображает самый старший разряд доли секунды. Если цифра равна нулю, ничего не отображается. Приложение указывает «% F», если шаблон формата не сочетается с другими шаблонами формата. |
| FF | Отображает две наиболее значимые цифры доли секунды.Однако конечные нули или две нулевые цифры не отображаются. |
| FFF | Отображает три наиболее значимые цифры доли секунды. Однако конечные нули или три нулевых цифры не отображаются. |
| FFFF | Отображает четыре старших разряда доли секунды. Однако конечные нули или четыре нулевых цифры не отображаются. |
| FFFFF | Отображает пять наиболее значимых цифр доли секунды.Однако конечные нули или пять нулевых цифр не отображаются. |
| FFFFFF | Отображает шесть старших разрядов доли секунды. Однако конечные нули или шесть нулевых цифр не отображаются. Однако конечные нули или шесть нулевых цифр не отображаются. |
| FFFFFFF | Отображает семь наиболее значимых цифр доли секунды. Однако конечные нули или семь нулевых цифр не отображаются. |
| gg | Период или эпоха. Этот шаблон игнорируется, если форматируемая дата не имеет связанной строки периода или эры. |
| h,% h | Час в 12-часовом формате. Однозначные часы не имеют нуля в начале. Приложение указывает «% h», если шаблон формата не сочетается с другими шаблонами формата. |
| hh | Час в 12-часовом формате. Однозначные часы начинаются с нуля. |
| H,% H | Час в 24-часовом формате. Однозначные часы не имеют нуля в начале. Приложение указывает «% H», если шаблон формата не сочетается с другими шаблонами формата. |
| HH | Час в 24-часовом формате. Однозначные часы начинаются с нуля. |
| K | Различные значения свойства Kind, то есть Local, Utc или Unspecified. |
| m,% m | Минута. Однозначные минуты не имеют начального нуля. Приложение указывает «% m», если шаблон формата не сочетается с другими шаблонами формата. |
| мм | Минуты. Однозначные минуты начинаются с нуля. |
| M,% M | Числовой месяц. Однозначные месяцы не имеют начального нуля. Приложение указывает «% M», если шаблон формата не сочетается с другими шаблонами формата. |
| MM | Числовой месяц. Однозначные месяцы начинаются с нуля. |
| MMM | Сокращенное наименование месяца |
| MMMM | Полное название месяца |
| s,% s | Второе.Однозначные секунды не имеют нуля в начале. Приложение указывает «% s», если шаблон формата не сочетается с другими шаблонами формата. |
| сс | Второй. Однозначные секунды начинаются с нуля. |
| t,% t | Первый символ в обозначении AM / PM, если он есть. Приложение указывает «% t», если шаблон формата не сочетается с другими шаблонами формата. Приложение указывает «% t», если шаблон формата не сочетается с другими шаблонами формата. |
| tt | Обозначение AM / PM («ante meridiem» (до полудня) или «post meridiem» (после полудня)), если таковое имеется.Ваше приложение должно использовать этот шаблон формата для языков, для которых необходимо поддерживать различие между AM и PM. Примером является японский язык, для которого обозначения AM и PM различаются вторым символом вместо первого. |
| г,% у | Год без века. Если год без века меньше 10, год отображается без нуля в начале. Приложение указывает «% y», если шаблон формата не сочетается с другими шаблонами формата. |
| гг | Год без века. Если год без века меньше 10, год отображается с нулем в начале. |
| ггг | Год в трехзначном формате. Если год меньше 100, год отображается с нулем в начале. |
| гггг | Год в четырех или пятизначном формате (в зависимости от используемого календаря), включая век. Прокладки с ведущими нулями для получения четырех цифр. Тайский буддийский и корейский календари имеют пятизначный год.Пользователи, выбирающие шаблон «гггг», видят все пять цифр без начальных нулей для календарей с пятью цифрами. Исключение: японский и тайваньский календари всегда ведут себя так, как если бы выбрано «yy». Прокладки с ведущими нулями для получения четырех цифр. Тайский буддийский и корейский календари имеют пятизначный год.Пользователи, выбирающие шаблон «гггг», видят все пять цифр без начальных нулей для календарей с пятью цифрами. Исключение: японский и тайваньский календари всегда ведут себя так, как если бы выбрано «yy». |
| ггггг | Год в пятизначном формате. Прокладки с ведущими нулями, чтобы получить пять цифр. Исключение: японский и тайваньский календари всегда ведут себя так, как если бы выбрано «yy». |
| гггггг | Год в шести цифрах. Прокладки с ведущими нулями, чтобы получить шесть цифр.Исключение: японский и тайваньский календари всегда ведут себя так, как если бы выбрано «yy». Шаблон может быть продолжен более длинной строкой заполнения «y» с большим количеством ведущих нулей. |
| z,% z | Смещение часового пояса («+» или «-» с указанием только часа). Однозначные часы не имеют нуля в начале. Например, стандартное тихоокеанское время — «-8». Приложение указывает «% z», если шаблон формата не сочетается с другими шаблонами формата. Приложение указывает «% z», если шаблон формата не сочетается с другими шаблонами формата. |
| zz | Смещение часового пояса («+» или «-» с указанием только часа).Однозначные часы начинаются с нуля. Например, стандартное тихоокеанское время — «-08». |
| zzz | Полное смещение часового пояса («+» или «-», за которыми следуют час и минуты). Однозначные часы и минуты имеют ведущие нули. Например, стандартное тихоокеанское время — «-08: 00». |
Отображение отрицательного времени (Microsoft Excel)
Обратите внимание: Эта статья написана для пользователей следующих версий Microsoft Excel: 2007, 2010, 2013, 2016, 2019 и Excel в Office 365.Если вы используете более раннюю версию (Excel 2003 или более раннюю), этот совет может вам не подойти . Чтобы посмотреть версию этого совета, написанного специально для более ранних версий Excel, щелкните здесь: Отображение отрицательного времени.
У Майка есть рабочий лист, в котором есть несколько раз.Если он вычитает 6:33 из 6:21, он заметил, что не получает отрицательного значения прошедшего времени, как в -: 12. Вместо этого он получает ############# в ячейке. Майк задается вопросом, как он может правильно отображать отрицательную разницу во времени?
Самый простой способ решить эту проблему — просто изменить систему дат, используемую в книге. Это может показаться глупым, но если вы используете систему дат 1900 (которая используется по умолчанию для версий Excel для Windows), тогда вы получите ############# в ячейке. Если вместо этого вы перейдете на систему дат 1904 года (которая используется по умолчанию для версий Excel для Mac), вы увидите правильное отрицательное прошедшее время в своей формуле.
Чтобы изменить систему дат, выполните следующие действия:
- Отображение диалогового окна параметров Excel. (В Excel 2007 нажмите кнопку Office, а затем выберите Параметры Excel. В Excel 2010 или более поздней версии откройте вкладку Файл на ленте и нажмите Параметры.)
- Щелкните «Дополнительно» в левой части диалогового окна.
- Прокрутите список параметров, пока не увидите раздел «При вычислении этой книги». (См. Рисунок 1.)
- Флажок «Использовать систему дат 1904» определяет, какая система датирования используется, как и в более ранних версиях Excel.
Рисунок 1. Дополнительные параметры диалогового окна Параметры Excel.
Если вы предпочитаете не изменять систему датирования, используемую в книге (возможно, это может испортить некоторые другие формулы даты, которые есть на рабочем листе), то единственное, что вы можете сделать, это создать текстовую версию времени. дифференциал по следующей формуле:
= ЕСЛИ (B2-A2 <0, «-» & ТЕКСТ (ABS (B2-A2), «чч: мм»), B2-A2)
Если разница между двумя значениями времени (в A2 и B2) отрицательная, то формула объединяет текстовое значение, состоящее из знака минус и абсолютного значения разницы между временами.
ExcelTips - ваш источник экономичного обучения Microsoft Excel. Этот совет (6239) применим к Microsoft Excel 2007, 2010, 2013, 2016, 2019 и Excel в Office 365. Вы можете найти версию этого совета для более старого интерфейса меню Excel здесь: Отображение отрицательного времени .
Автор Биография
Аллен Вятт
Аллен Вятт - всемирно признанный автор, автор более чем 50 научно-популярных книг и многочисленных журнальных статей.Он является президентом Sharon Parq Associates, компании, предоставляющей компьютерные и издательские услуги. Узнать больше о Allen ...
Изменение шрифтов для записей автотекста
Если вы часто используете записи автотекста, вы можете задаться вопросом, можете ли вы изменить форматирование, сохраненное с вашими существующими записями. В ...
В ...
Сноски в сносках
Нужно добавить сноски к вашим сноскам? На самом деле это разрешено некоторыми руководствами по стилю, но в Word это не так просто.
Открой для себя большеПереход к определенной странице
Хотите перейти на определенную страницу в документе? Word облегчает задачу; просто откройте вкладку «Перейти» в меню «Найти» и ...
Открой для себя большеHH-suite3 для быстрого удаленного определения гомологии и глубокой аннотации белков | BMC Bioinformatics
Обзор HH-suite
Программное обеспечение HH-suite содержит инструменты поиска HHsearch [15] и HHblits [5], а также различные утилиты для создания баз данных MSA или профильных HMM, для преобразования форматов MSA и т. Д.
HHsearch сопоставляет HMM профиля с базой данных HMM целевого профиля. Сначала поиск сопоставляет запрос HMM с каждым из целевых HMM с помощью алгоритма динамического программирования Витерби, который находит совпадение с максимальной оценкой. Значение E для целевой HMM рассчитывается по шкале Витерби [5]. Целевые HMM, которые достигают достаточной значимости для сообщения, повторно выравниваются с использованием алгоритма максимальной точности (MAC) [22]. Этот алгоритм максимизирует ожидаемое количество правильно выровненных пар остатков за вычетом штрафа от 0 до 1 (параметр -mact).Значения около 0 приводят к жадным, длинным, почти глобальным выравниваниям, значения выше 0,3 приводят к более коротким локальным выравниваниям.
Значение E для целевой HMM рассчитывается по шкале Витерби [5]. Целевые HMM, которые достигают достаточной значимости для сообщения, повторно выравниваются с использованием алгоритма максимальной точности (MAC) [22]. Этот алгоритм максимизирует ожидаемое количество правильно выровненных пар остатков за вычетом штрафа от 0 до 1 (параметр -mact).Значения около 0 приводят к жадным, длинным, почти глобальным выравниваниям, значения выше 0,3 приводят к более коротким локальным выравниваниям.
HHblits - это ускоренная версия HHsearch, которая достаточно быстра для выполнения итеративного поиска по миллионам профильных HMM, например через базы данных HMM профиля Uniclust, сгенерированные путем кластеризации базы данных UniProt в кластеры глобально выравниваемых последовательностей [23]. Подобно PSI-BLAST и HMMER3, такой итеративный поиск можно использовать для построения MSA, начиная с одной последовательности запросов.Последовательности совпадений с профилями HMM ниже некоторого порогового значения E (например, 10 −3 ) добавляются в запрос MSA для следующей итерации поиска.
HHblits имеет двухступенчатый предварительный фильтр, который уменьшает количество HMM базы данных, которые необходимо согласовать с медленным выравниванием Viterbi HMM-HMM и алгоритмами MAC. Для максимальной скорости целевые HMM представлены в предварительном фильтре как дискретизированные последовательности в 219-буквенном алфавите, в котором каждая буква представляет один из 219 столбцов архетипического профиля.Таким образом, два этапа предварительной фильтрации выполняют выравнивание профиля по последовательности, сначала без промежутков, затем с промежутками, используя динамическое программирование. Каждая ступень отфильтровывает от 95 до 99% целевых HMM.
Обзор изменений с HH-suite версии 2.0.16 на 3
Векторизованное выравнивание viterbi HMM-HMM
Большая часть ускорения была достигнута за счет разработки эффективного кода SIMD и удаления ветвей в алгоритме попарного выравнивания Viterbi HMM. Новая реализация выравнивает 4 (с использованием SSE2) или 8 (с использованием AVX2) целевых HMM параллельно одному запросу HMM.
Быстрое выравнивание MAC HMM-HMM
Мы ускорили алгоритм вперед-назад, который вычисляет апостериорные вероятности для всех пар остатков ( i , j ), которые будут выровнены друг с другом. Эти вероятности необходимы алгоритму выравнивания MAC. Мы повысили скорость алгоритмов Forward-Backward и MAC, удалив ветви в самых внутренних циклах и оптимизировав порядок индексов, что снизило частоту промахов кеша.
Уменьшение памяти
Мы уменьшили объем памяти, необходимый во время выравнивания Viterbi HMM-HMM, в 1 раз.5 для SSE2 и реализовал AVX2 с увеличением всего в 1,3 раза, несмотря на необходимость хранить оценки для 4 (SSE2) или 8 (AVX2) HMM целевого профиля в памяти вместо одного. Это было сделано путем сохранения в памяти только текущей строки из 5 матриц скоринга во время динамического программирования (раздел «Уменьшение памяти для обратной трассировки и матриц отсечения ячеек»), а также путем сохранения 5 матриц обратной трассировки, для которых ранее требовался один байт на матрицу. ячейка в одной матрице обратной трассировки с одним байтом на ячейку (раздел «От квадратичной к линейной памяти для скоринг-матриц»).Мы также уменьшили потребление памяти алгоритмами прямого-обратного и MAC-выравнивания в два раза, перейдя от хранения апостериорных вероятностей с типом double к хранению их логарифмов с использованием типа float. В целом мы уменьшили объем требуемой памяти примерно в 1,75 раза (при использовании SSE2) или 1,16 (при использовании AVX2).
ячейка в одной матрице обратной трассировки с одним байтом на ячейку (раздел «От квадратичной к линейной памяти для скоринг-матриц»).Мы также уменьшили потребление памяти алгоритмами прямого-обратного и MAC-выравнивания в два раза, перейдя от хранения апостериорных вероятностей с типом double к хранению их логарифмов с использованием типа float. В целом мы уменьшили объем требуемой памяти примерно в 1,75 раза (при использовании SSE2) или 1,16 (при использовании AVX2).
Ускорение фильтрации последовательностей и вычисления профиля
Для максимальной чувствительности HHblits и HHsearch необходимо уменьшить избыточность во входном MSA путем удаления последовательностей, которые имеют идентичность последовательности с другой последовательностью в MSA, превышающей указанное пороговое значение (90% по умолчанию ) [15].Фильтрация избыточности занимает время O ( N L 2 ), где N - это количество последовательностей MSA, а L - количество столбцов. Это может быть узким местом во время выполнения для крупных MSA, например, во время итеративного поиска с помощью HHblits. Более подробное объяснение приводится в разделе «Резервный фильтр MSA на основе SIMD».
Это может быть узким местом во время выполнения для крупных MSA, например, во время итеративного поиска с помощью HHblits. Более подробное объяснение приводится в разделе «Резервный фильтр MSA на основе SIMD».
Кроме того, расчет вероятностей аминокислот в столбцах профиля HMM из MSA может стать ограничивающим по времени.Его время выполнения масштабируется как O ( N L 2 ), потому что для каждого столбца требуется время ∼ O ( N L ) для вычисления весов последовательности для конкретных столбцов на основе субвыравнивания. содержащие только последовательности, в которых нет пробелов в этом столбце.
Мы переработали эти два алгоритма для использования инструкций SIMD и оптимизировали доступ к памяти за счет переупорядочения вложенных циклов и индексов массивов.
Оценка вторичной структуры
Чувствительность поиска можно немного повысить для удаленных гомологов путем изменения взвешивания оценки выравнивания вторичной структуры по отношению к оценке сходства столбцов профиля. В HH-suite3 оценка вторичной структуры может составлять более 20% общей оценки. Это немного повысило чувствительность для обнаружения удаленных гомологов без отрицательного влияния на высокую точность.
В HH-suite3 оценка вторичной структуры может составлять более 20% общей оценки. Это немного повысило чувствительность для обнаружения удаленных гомологов без отрицательного влияния на высокую точность.
Новые функции, рефакторинг кода и исправления ошибок
HH-suite3 позволяет пользователям выполнять поиск по большому количеству последовательностей запросов путем распараллеливания поиска HHblits / HHsearch по запросам с использованием OpenMP и MPI (hhblits_omp, hhblits_mpi, hhsearch_omp, hhsearch_mpi). Мы сняли ограничение на максимальное количество последовательностей в MSA (параметр -maxseqs
Мы приняли новый формат для баз данных HHblits, в котором последовательности состояний столбцов, используемые для предварительной фильтрации (бывшие файлы * . cs219), хранятся в формате FFindex. Формат FFindex уже использовался в версии 2.0.16 для файлов a3m MSA и файлов HMM профиля hhm.Это привело к экономии ∼4 с для чтения базы данных префильтра и улучшенному масштабированию HHblits с количеством ядер. Мы также интегрировали наш дискриминантный, контекстно-зависимый метод последовательностей для вычисления псевдосчетов для профильных HMMs, который немного улучшает чувствительность для гомологий на уровне складок [26].
cs219), хранятся в формате FFindex. Формат FFindex уже использовался в версии 2.0.16 для файлов a3m MSA и файлов HMM профиля hhm.Это привело к экономии ∼4 с для чтения базы данных префильтра и улучшенному масштабированию HHblits с количеством ядер. Мы также интегрировали наш дискриминантный, контекстно-зависимый метод последовательностей для вычисления псевдосчетов для профильных HMMs, который немного улучшает чувствительность для гомологий на уровне складок [26].
Чтобы HH-пакет оставался устойчивым и расширяемым в долгосрочной перспективе, мы тщательно реорганизовали код, улучшив повторное использование кода с помощью новых классов с наследованием, заменив потоки POSIX (pthreads) на распараллеливание OpenMP, удалив глобальные переменные, перейдя от make к cmake и перемещение проекта HH-suite на GitHub (https: // github.com / soedinglab / hh-suite). Мы исправили различные ошибки, такие как утечки памяти и ошибки сегментации, возникающие в новых компиляторах.
Поддерживаемые платформы и оборудование
HHblits разработан под Linux, протестирован под Linux и macOS, и должен работать под любыми Unix-подобными операционными системами. Поддерживаются процессоры Intel и AMD, которые предлагают наборы инструкций AVX2 или хотя бы SSE2 (процессоры Intel: с 2006 г., AMD: с 2011 г.). Также поддерживаются процессоры PowerPC с векторными расширениями AltiVec.
Поддерживаются процессоры Intel и AMD, которые предлагают наборы инструкций AVX2 или хотя бы SSE2 (процессоры Intel: с 2006 г., AMD: с 2011 г.). Также поддерживаются процессоры PowerPC с векторными расширениями AltiVec.
Поскольку нам не удалось получить финансирование для продолжения поддержки HH-suite, поддержка пользователей, к сожалению, пока ограничивается исправлением ошибок.
Распараллеливание путем векторизации с использованием инструкций SIMD
Все современные процессоры имеют модули SIMD, обычно по одному на ядро, для выполнения арифметических, логических и других операций с несколькими элементами данных параллельно. В SSE2 четыре операции с плавающей запятой обрабатываются за один такт в выделенных 128-битных регистрах. С 2012 года стандарт AVX позволяет обрабатывать восемь операций с плавающей запятой за один такт параллельно, хранящихся в 256-битных регистрах AVX. С расширением AVX2 появилась поддержка операций на уровне байтов, слов и целых чисел, например. грамм. 32 однобайтовых числа можно складывать или умножать параллельно (32 × 1 байт = 256 бит). Intel поддерживает AVX2 с 2013 года, AMD - с 2015 года.
грамм. 32 однобайтовых числа можно складывать или умножать параллельно (32 × 1 байт = 256 бит). Intel поддерживает AVX2 с 2013 года, AMD - с 2015 года.
HHblits 2.0.16 уже использовал SSE2 в своем предварительном фильтре для непрерывной обработки выравнивания профиля и последовательности 16 ячеек динамического программирования параллельно, но он не поддерживал выравнивание HMM-HMM с использованием векторизованного кода.
Уровень абстракции для векторного программирования на основе SIMD
Внутренние функции позволяют писать параллельные алгоритмы SIMD без использования инструкций сборки.Однако они привязаны к одному конкретному варианту набора инструкций SIMD (например, AVX2), что делает их не совместимыми с предыдущими версиями и не ориентированными на будущее. Чтобы иметь возможность компилировать наши алгоритмы с различными вариантами набора инструкций SIMD, мы реализовали уровень абстракции simd.h. На этом уровне внутренние функции обернуты макросами препроцессора. Поэтому перенос нашего кода на новый стандарт SIMD просто требует от нас расширения уровня абстракции до этого нового стандарта, в то время как алгоритм остается неизменным.
Поэтому перенос нашего кода на новый стандарт SIMD просто требует от нас расширения уровня абстракции до этого нового стандарта, в то время как алгоритм остается неизменным.
Заголовок simd.h поддерживает наборы инструкций SSE2, AVX2 и AVX-512. Дэвид Миллер любезно расширил уровень абстракции simd.h для поддержки векторного расширения AltiVec процессоров PowerPC. Алгоритм 1 показывает функцию, которая вычисляет скалярное произведение двух векторов.
Векторизованные выравнивания витерби HMM-HMM
Алгоритм Витерби для выравнивания профильных hMM
Алгоритм Витерби, когда он применяется к профильным HMM, формально эквивалентен глобальному выравниванию последовательностей со штрафами за разрывы, зависящие от позиции [27].Ранее мы представили модификацию алгоритма Витерби, которая формально эквивалентна локальному выравниванию последовательностей Смита-Ватермана [15]. В HH-suite мы используем его для вычисления наилучшего локального выравнивания между двумя HMM профилями.
HH-suite моделирует столбцы MSA с <50 % пробелов (значение по умолчанию) по состояниям соответствия, а все остальные столбцы - как состояния вставки. Проходя через состояния профиля HMM, HMM может «испускать» последовательности. Состояние совпадения (M) выделяет аминокислоты в соответствии с 20 вероятностями аминокислот, оцененными по их доле в столбце MSA, плюс несколько псевдосчетов.Состояния вставки (I) выделяют аминокислоты в соответствии со стандартным распределением фоновых аминокислот, в то время как состояния удаления (D) не выделяют никаких аминокислот.
Оценка выравнивания между двумя HMM в HH-наборе представляет собой сумму по всем совместно испускаемым последовательностям логарифмических оценок вероятности для двух выровненных HMM совместно испускать эту последовательность, деленную на вероятность последовательности на фоне модель. Поскольку состояния M и I выделяют аминокислоты, а состояния D - нет, M и I в одной HMM могут быть выровнены только с состояниями M или I в другой HMM. И наоборот, состояние D может быть выровнено только с состоянием D или с разрывом G (рис. 1). Оценка совместной эмиссии может быть записана как сумма оценок подобия выровненных столбцов профиля, другими словами, состояния пары совпадение-совпадение (MM) за вычетом штрафов, связанных с позицией, за отступы: удаление-открытие, удаление-расширение , вставить-открыть и вставить-выдвинуть.
И наоборот, состояние D может быть выровнено только с состоянием D или с разрывом G (рис. 1). Оценка совместной эмиссии может быть записана как сумма оценок подобия выровненных столбцов профиля, другими словами, состояния пары совпадение-совпадение (MM) за вычетом штрафов, связанных с позицией, за отступы: удаление-открытие, удаление-расширение , вставить-открыть и вставить-выдвинуть.
HMM-HMM выравнивание запроса и цели. Выравнивание представлено красным путем через оба HMM. Соответствующая последовательность состояний пары - MM, MM, MI, MM, MM, DG, MM
. Мы обозначаем состояния пары выравнивания как MM, MI, IM, II, DD, DG и GD.На рисунке 1 показан пример двух ГММ с выровненным профилем. В третьем столбце HMM q испускает остаток из своего состояния M, а HMM p испускает остаток из состояния I. Состояние пары для этого столбца выравнивания - MI. В шестом столбце выравнивания HMM q ничего не испускает, так как проходит через состояние D..jpg) {ss} _ {j} \ вправо) \ + \\ & \ max \ left \ {\! \! \ begin {array} {c} \ begin {align} & 0 \ text {(для {локального} выравнивания)} \\ & S _ {\ text {MM}} (i \, - \, 1, j \, - \, 1) + \ log \ left (q_ {i \, - \, 1} (\ text {M, M}) \: t_ {j \, - \, 1} (\ text {M, M} \ right) ) \\ & S _ {\ text {MI}} (i \, - \, 1, j \, - \, 1) \; \, + \ log \ left (q_ {i \, - \, 1} (\ текст {M, M}) \: t_ {j \, - \, 1} (\ text {I, M}) \ right) \\ & S _ {\ text {II}} (i \, - \, 1, j \, - \, 1) \; \; \: + \ log \ left (q_ {i \, - \, 1} (\ text {I, M}) \: t_ {j \, - \, 1 } (\ text {M, M}) \ right) \\ & S _ {\ text {DG}} (i \, - \, 1, j \, - \, 1) \: + \ log \ left (q_ { i \, - \, 1} (\ text {D, M}) \: t_ {j \, - \, 1} (\ text {M, M}) \ right) \\ & S _ {\ text {GD} } (i \, - \, 1, j \, - \, 1) \: + \ log \ left (q_ {i \, - \, 1} \ left (\ text {M, M} \ right) \ : t_ {j \, - \, 1} (\ text {D, M}) \ right) \ end {align} \ end {array} \ right.\ end {array} $$
{ss} _ {j} \ вправо) \ + \\ & \ max \ left \ {\! \! \ begin {array} {c} \ begin {align} & 0 \ text {(для {локального} выравнивания)} \\ & S _ {\ text {MM}} (i \, - \, 1, j \, - \, 1) + \ log \ left (q_ {i \, - \, 1} (\ text {M, M}) \: t_ {j \, - \, 1} (\ text {M, M} \ right) ) \\ & S _ {\ text {MI}} (i \, - \, 1, j \, - \, 1) \; \, + \ log \ left (q_ {i \, - \, 1} (\ текст {M, M}) \: t_ {j \, - \, 1} (\ text {I, M}) \ right) \\ & S _ {\ text {II}} (i \, - \, 1, j \, - \, 1) \; \; \: + \ log \ left (q_ {i \, - \, 1} (\ text {I, M}) \: t_ {j \, - \, 1 } (\ text {M, M}) \ right) \\ & S _ {\ text {DG}} (i \, - \, 1, j \, - \, 1) \: + \ log \ left (q_ { i \, - \, 1} (\ text {D, M}) \: t_ {j \, - \, 1} (\ text {M, M}) \ right) \\ & S _ {\ text {GD} } (i \, - \, 1, j \, - \, 1) \: + \ log \ left (q_ {i \, - \, 1} \ left (\ text {M, M} \ right) \ : t_ {j \, - \, 1} (\ text {D, M}) \ right) \ end {align} \ end {array} \ right.\ end {array} $$
(1)
$$ {} {\ begin {align} & S _ {\ text {MI}} \ left (i, j \ right) = \ max \ left \ {\! \! \ begin {array} {c} S _ {\ text {MM}} (i \, - \, 1, j) + \ log \ left (q_ {i \, - \, 1} (\ text {M, M }) \: t_ {j} (\ text {D, D}) \ right) \\ S _ {\ text {MI}} (i \, - \, 1, j) + \ log \ left (q_ {i \, - \, 1} (\ text {M, M}) \: t_ {j} (\ text {I, I}) \ right) \ end {array} \ right. \ end {align}} $$
\ end {align}} $$
(2)
$$ \ begin {array} {* {20} l} & S _ {\ text {DG}} \ left (i, j \ right) = \ max \ left \ {\! \! \ begin {array} {c} S _ {\ text {MM}} (i \, - \, 1, j) + \ log \ left (q_ {i \, - \, 1} (\ text {D, M }) \ right) \\ S _ {\ text {DG}} (i \, - \, 1, j) + \ log \ left (q_ {i \, - \, 1} (\ text {D, D} ) \ right) \ end {array} \ right.{p} _ {j} \) - вероятности аминокислот t при j , а f a обозначает фоновую частоту аминокислоты a . Оценка S aa измеряет сходство распределений аминокислот в двух столбцах i и j . S ss можно дополнительно добавить к S aa . Он измеряет сходство состояний вторичной структуры запроса и целевой HMM на i и j [15].
Векторизация выравнивания последовательностей Смита-Уотермана
Много усилий было вложено в ускорение алгоритма Смита-Ватермана на основе динамического программирования (при неизменной временной сложности O ( L q L t )). Хотя было продемонстрировано существенное ускорение с использованием универсальных графических процессоров (GPGPU) и программируемых логических матриц (FPGA) [28–31], необходимость в мощном GPGPU и отсутствие единого стандарта (например,грамм. Собственный CUDA Nvidia по сравнению со стандартом OpenCL) были препятствиями. Реализации SIMD, использующие стандарты SSE2 и AVX2 с векторными модулями SIMD на ЦП, продемонстрировали ускорение, аналогичное реализациям GPGPU, и получили широкое распространение [3, 4, 32–35].
Хотя было продемонстрировано существенное ускорение с использованием универсальных графических процессоров (GPGPU) и программируемых логических матриц (FPGA) [28–31], необходимость в мощном GPGPU и отсутствие единого стандарта (например,грамм. Собственный CUDA Nvidia по сравнению со стандартом OpenCL) были препятствиями. Реализации SIMD, использующие стандарты SSE2 и AVX2 с векторными модулями SIMD на ЦП, продемонстрировали ускорение, аналогичное реализациям GPGPU, и получили широкое распространение [3, 4, 32–35].
Чтобы ускорить динамическое программирование (DP) с использованием SIMD, несколько ячеек в матрице DP обрабатываются совместно. Однако значение в ячейке ( i , j ) зависит от значений в предыдущих ячейках ( i −1, j −1), ( i −1, j ) и ( i , j −1).Эта зависимость данных затрудняет ускорение алгоритма.
Для решения этой проблемы были разработаны четыре основных подхода: (1) распараллеливание по антидиагональным участкам ячеек в матрице DP (( i , j ), ( i +1, j - 1),… ( i +15, j −15), предполагая, что 16 ячеек помещаются в один регистр SIMD) [32], (2) распараллеливание по вертикальным или горизонтальным сегментам матриц DP (например, ( i , j ), ( i + 1, j ),… ( i + 15, j )) [33], (3) распараллеливание по полосам DP-матриц (( i , j ), ( i + 1 × D , j ),… ( i + 15 × D , j ) где D : = ceil (query_length / 16) ) [34] и (4), где 16 ячеек ( i , j ) из 16 целевых последовательностей обрабатываются параллельно [35].
Последний вариант - самый быстрый метод выравнивания последовательность-последовательность, поскольку он позволяет избежать зависимостей данных. Здесь мы представляем реализацию этой опции, которая может параллельно согласовывать один профиль запроса HMM с 4 (SSE2) или 8 (AVX2) HMM целевого профиля.
Векторизованный алгоритм Витерби для выравнивания профилей HMM
Алгоритм 2 показывает скалярную версию алгоритма Витерби для попарного выравнивания HMM профиля на основе уравнений итеративного обновления. (1) - (3). Алгоритм 3 представляет нашу векторизованную версию без ветвей (рис.2). Он выравнивает пакеты из 4 или 8 целевых HMM вместе, в зависимости от того, сколько оценок типа float помещается в один регистр SIMD (4 для SSE2, 8 для AVX).
Рис. 2Распараллеливание SIMD над HMM целевого профиля. Пакеты из 4 или 8 HMM профиля базы данных выравниваются вместе с помощью векторизованного алгоритма Витерби. Каждая ячейка ( i , j ) в матрице динамического программирования обрабатывается параллельно для 4 или 8 целевых HMM
Векторизованный алгоритм должен иметь доступ к вероятностям перехода между состояниями и выбросам аминокислот для этих 4 или 8 целей одновременно. Память устроена так (рис. 3), что вероятности излучения и перехода 4 или 8 целей последовательно сохраняются в памяти. Таким образом, один набор из 4 или 8 вероятностей перехода (например, MM) из 4 или 8 целевых HMM может быть загружен совместно в один регистр SIMD.
Память устроена так (рис. 3), что вероятности излучения и перехода 4 или 8 целей последовательно сохраняются в памяти. Таким образом, один набор из 4 или 8 вероятностей перехода (например, MM) из 4 или 8 целевых HMM может быть загружен совместно в один регистр SIMD.
Схема логарифмических вероятностей перехода (вверху) и вероятностей выбросов (внизу) в памяти для алгоритмов одиночных данных с одной инструкцией (SISD) и SIMD. Для алгоритма SIMD, 4 (с использованием SSE2) или 8 (с использованием AVX 2) HMM целевого профиля (t1 - t4) хранятся вместе с чередованием: 4 или 8 значений перехода или излучения в позиции i в этих HMM сохраняются последовательно (обозначены одним цветом).Таким образом, чтение одной строки кэша размером 64 байта может заполнить четыре SSE2 или два SIMD-регистра AVX2 с 4 или 8 значениями каждый
Скалярные версии функций MAX6, MAX2 содержат ветви. Разветвленный код может значительно замедлить выполнение кода из-за высокой стоимости неверных предсказаний ветвлений, когда частично выполненный конвейер команд должен быть отброшен, чтобы возобновить выполнение правильного перехода.
Функции MAX6 и MAX2 находят максимальную оценку из двух или шести входных оценок, а также возвращают состояние перехода пары, которое дало наибольшую оценку.Это состояние сохраняется в матрице обратной трассировки, которая необходима для восстановления выравнивания с наилучшими показателями после вычисления всех пяти матриц DP.
Чтобы удалить пять ветвей if-statement в MAX6, мы реализовали макрос VMAX6, который реализует по одному if-statement за раз. VMAX6 необходимо вызывать 5 раз, а не один раз, как MAX6, и каждый вызов сравнивает текущий лучший результат со следующим из 6 баллов и обновляет состояние лучшего результата на данный момент путем максимизации.При каждом вызове VMAX6 текущее наилучшее состояние перезаписывается новым состоянием, если оно имеет лучший результат.
Мы вызываем функцию VMAX2 четыре раза, чтобы обновить четыре состояния GD, IM, DG и MI. Первая строка в VMAX2 сравнивает 4 или 8 значений в регистре SIMD sMM с соответствующими значениями в регистре sXY и устанавливает все биты четырех значений в регистре SIMD res_gt_vec в 1, если значение в sMM больше, чем в sXY, и 0 в противном случае. Вторая строка вычисляет побитовое И между четырьмя значениями в res_gt_vec (0x00000000 или 0xFFFFFFFF) и значением состояния MM.Для тех из 4 или 8 значений sMM, которые были больше, чем соответствующее значение sXY, мы получаем состояние MM в index_vec, для остальных мы получаем ноль, что означает нахождение в том же состоянии. Затем вектор обратной трассировки можно объединить с помощью инструкции XOR.
Вторая строка вычисляет побитовое И между четырьмя значениями в res_gt_vec (0x00000000 или 0xFFFFFFFF) и значением состояния MM.Для тех из 4 или 8 значений sMM, которые были больше, чем соответствующее значение sXY, мы получаем состояние MM в index_vec, для остальных мы получаем ноль, что означает нахождение в том же состоянии. Затем вектор обратной трассировки можно объединить с помощью инструкции XOR.
Чтобы вычислить субоптимальное, альтернативное выравнивание, мы запрещаем субоптимальному выравниванию проходить через любую ячейку ( i , j ), которая находится в пределах 40 ячеек от любой из ячеек с лучшими выравниваниями.Эти запрещенные ячейки хранятся в матрице cell_off [i] [j] в скалярной версии алгоритма Витерби. Первый оператор if в алгоритме 2 гарантирует, что эти ячейки получат оценку - ∞ .
Чтобы уменьшить требования к памяти в векторизованной версии, флаг отключения ячейки хранится в старшем разряде матрицы обратной трассировки (рис. 5) (см. Раздел «Уменьшение памяти для матриц обратной трассировки и исключения ячеек»). В алгоритме Витерби SIMD мы сдвигаем бит отключения ячейки матрицы обратного отслеживания вправо на единицу и загружаем четыре 32-битных (SSE2) или восемь 64-битных (AVX2) значений в регистр SIMD (строка 23).Мы извлекаем только биты выключения ячейки (строка 24), вычисляя И между co_mask и регистром cell_off. Мы устанавливаем элементы в регистре с битом cell_off в 0 и без 0xFFFFFFFF, сравнивая, больше ли cell_mask, чем cell_off (строка 25). В строке 26 мы устанавливаем 4 или 8 значений в регистре SIMD cell_off на - ∞ , если их бит отключения ячейки был установлен, и в противном случае на 0. После этого мы добавляем сгенерированный вектор ко всем пяти оценкам (MM, MI, IM, DG и GD).
Раздел «Уменьшение памяти для матриц обратной трассировки и исключения ячеек»). В алгоритме Витерби SIMD мы сдвигаем бит отключения ячейки матрицы обратного отслеживания вправо на единицу и загружаем четыре 32-битных (SSE2) или восемь 64-битных (AVX2) значений в регистр SIMD (строка 23).Мы извлекаем только биты выключения ячейки (строка 24), вычисляя И между co_mask и регистром cell_off. Мы устанавливаем элементы в регистре с битом cell_off в 0 и без 0xFFFFFFFF, сравнивая, больше ли cell_mask, чем cell_off (строка 25). В строке 26 мы устанавливаем 4 или 8 значений в регистре SIMD cell_off на - ∞ , если их бит отключения ячейки был установлен, и в противном случае на 0. После этого мы добавляем сгенерированный вектор ко всем пяти оценкам (MM, MI, IM, DG и GD).
Два подхода к уменьшению потребности в памяти для матриц оценок DP с O ( L q L t ) до O ( L
t ), где L q и L t - длины профиля запроса и целевого профиля соответственно. (Вверху) Один вектор содержит оценки предыдущей строки, S XY ( i −1, ·), для состояния пары XY ∈ {MM, MI, IM, GD и DG}, а другой - оценки текущей строки: S XY ( i , ·) для состояния пары XY ∈ {MM, MI, IM, GD и DG}. Указатели векторов меняются местами после обработки каждой строки. (Внизу) Один вектор для состояния пары XY содержит оценки текущей строки до j -1 и предыдущей строки для j до L t .Второй подход несколько быстрее и был выбран для HH-suite3
(Вверху) Один вектор содержит оценки предыдущей строки, S XY ( i −1, ·), для состояния пары XY ∈ {MM, MI, IM, GD и DG}, а другой - оценки текущей строки: S XY ( i , ·) для состояния пары XY ∈ {MM, MI, IM, GD и DG}. Указатели векторов меняются местами после обработки каждой строки. (Внизу) Один вектор для состояния пары XY содержит оценки текущей строки до j -1 и предыдущей строки для j до L t .Второй подход несколько быстрее и был выбран для HH-suite3
Небольшое улучшение времени выполнения было достигнуто путем компиляции обеих версий метода Витерби, одной с логикой отключения ячейки, а другой без нее. Для первого оптимального согласования мы называем версию, скомпилированную без логики отключения ячейки, а для альтернативных согласований - версией с включенной логикой отключения ячейки. В C / C ++ это можно сделать с помощью макросов препроцессора.
ТММ с более коротким профилем заполняются с вероятностью от нуля до длины самого длинного профиля HMM в партии (рис. {p} _ {j} (a) \).Код SIMD требует 39 инструкций для вычисления оценок для 4 или 8 целевых столбцов, тогда как скалярная версия требует 39 инструкций для одного целевого столбца.
{p} _ {j} (a) \).Код SIMD требует 39 инструкций для вычисления оценок для 4 или 8 целевых столбцов, тогда как скалярная версия требует 39 инструкций для одного целевого столбца.
От квадратичной к линейной памяти для матриц оценки
Большая часть памяти в алгоритме 2 требуется для пяти матриц оценок для состояний пар MM, MI, IM, GD и DG. Для белка из 15 000 остатков пяти матрицам требуется 15 000 × 15 000 × 4 байта × 5 матриц = 4,5 ГБ памяти на поток.
В наивной реализации векторизованному алгоритму потребовалось бы в 4 или 8 раз больше памяти, чем это, так как он должен был бы хранить оценки 4 или 8 HMM целевого профиля в матрицах оценок.Для этого потребуется 36 ГБ памяти на поток или 576 ГБ для обычно используемых 16-ядерных серверов.
Однако мы не требуем, чтобы все скоринговые матрицы находились в памяти. Нам нужны только матрицы обратного отслеживания и положение ( i наилучшее , j наилучшее ) ячейки с наивысшей оценкой, чтобы восстановить выравнивание.
Мы реализовали два подхода. Первый использует два вектора на состояние пары (рис. 4 вверху). Один содержит оценки текущей строки i , где ( i , j ) - это позиции ячейки, оценки которой должны быть вычислены, а другой вектор содержит оценки предыдущей строки i - 1.После того, как все оценки строки i были вычислены, указатели на векторы меняются местами, и предыдущая строка становится текущей.
Рис. 5Состояния пары предшественников для отслеживания выравниваний Витерби сохраняются в одном байте матрицы обратного отслеживания в HH-suite3, чтобы уменьшить требования к памяти. Биты от 0 до 2 (синие) используются для сохранения состояния предшественника в состояние MM, биты с 3 по 6 хранят предшественник состояний пары GD, IM, DG и MI. Последний бит обозначает ячейки, которым не разрешено быть частью субоптимального выравнивания, потому что они находятся рядом с ячейкой, которая была частью выравнивания с более высокими баллами
Второй подход использует только один вектор (рис. 4 внизу). Его элементы от 1 до j −1 содержат оценки текущей строки, которые уже были вычислены. Его элементы от j до последней позиции L t содержат оценки из предыдущего ряда i −1.
4 внизу). Его элементы от 1 до j −1 содержат оценки текущей строки, которые уже были вычислены. Его элементы от j до последней позиции L t содержат оценки из предыдущего ряда i −1.
Второй вариант оказался быстрее, хотя на каждой итерации он выполняет больше инструкций. Однако профилирование показало, что это более чем компенсируется меньшим количеством промахов в кэше, вероятно, из-за необходимости в два раза меньшей памяти.
Мы экономим много памяти, сохраняя текущие необходимые оценки цели в линейном кольцевом буфере размером O ( L t ). Тем не менее, нам по-прежнему необходимо сохранить в памяти матрицу обратного отслеживания (см. Следующий подраздел) квадратичного размера O ( L q L t ). Следовательно, сложность памяти остается неизменной.
Сокращение памяти для обратной трассировки и матриц отсечения ячеек
Чтобы вычислить выравнивание путем обратной трассировки из ячейки ( i лучшее , j лучшее ) с максимальным количеством очков, нам необходимо сохранить для каждой ячейки i , j ) и состояние каждой пары ( M M , G D , M I , D G , I M ) предыдущая ячейка и пара указывает, что выравнивание будет проходить, то есть какая ячейка внесла максимальный балл в ( i , j ). Для этого, очевидно, достаточно сохранить только предыдущее состояние пары.
Для этого, очевидно, достаточно сохранить только предыдущее состояние пары.
HHblits 2.0.16 использует пять различных матриц типа char, по одной для каждого состояния пары, и одну матрицу char для хранения значений вне ячейки (всего 6 байтов). Самый длинный из известных белков Титин содержит около 33 000 аминокислот. Чтобы сохранить в памяти матрицу размером 33 000 × 33 000 × 6 b y t e , нам потребуется 6 ГБ памяти. Поскольку только часть из ∼10 -5 последовательностей является последовательностями, длина которых превышает 15 000 остатков в базе данных UniProt, мы ограничиваем максимальную длину последовательности по умолчанию до 15 000.Этот предел можно увеличить с помощью параметра -maxres.
Но нам все равно потребуется около 1,35 ГБ для хранения матриц трассировки и отключения ячейки. Поэтому наивной реализации SSE2 потребуется 5,4 ГБ и 10,8 ГБ с AVX2. Поскольку каждому потоку нужны собственные матрицы отслеживания и исключения ячеек, это может быть серьезным ограничением.
Мы уменьшаем требования к памяти, сохраняя всю информацию об обратной трассировке и флаг отключения ячейки в одном байте на ячейку ( i , j ).Предыдущее состояние для состояний IM, MI, GD, DG может храниться как одиночный бит, где 1 означает, что предыдущее состояние пары было таким же, как текущее, и 0 означает, что это было MM. Предыдущее состояние для MM может быть любым из STOP, MM, IM, MI, GD и DG. СТОП представляет собой начало выравнивания, которое соответствует 0 в (уравнение 1), вносящему наибольший из 6 баллов. Нам нужно три бита для хранения этих шести возможных состояний пары предшественников. Таким образом, информация обратной трассировки может храниться в битах «4 + 3», что оставляет один бит для флага отключения ячейки (рис.5). Из-за сокращения до одного байта на ячейку нам нужно всего 0,9 ГБ (с SSE2) или 1,8 ГБ (с AVX2) на поток для хранения информации об обратной трассировке и отключении ячеек.
Критерий раннего завершения Витерби
Для некоторых HMM запроса многие негомологичные целевые HMM проходят стадию предварительной фильтрации, например, когда они содержат одну из очень часто встречающихся областей спиральной катушки.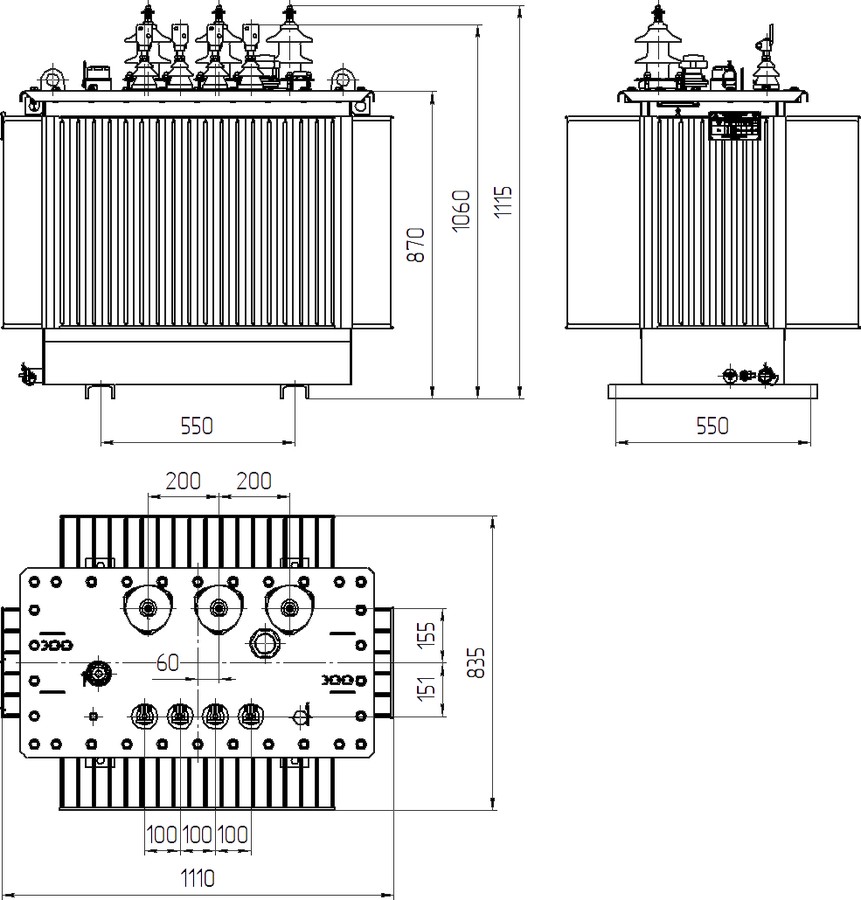 Чтобы избежать необходимости согласовывать тысячи негомологичных целевых HMM с дорогостоящим алгоритмом Витерби, мы ввели критерий раннего завершения в HHblits 2.0,16. Мы усреднили 1 / (1 + E-значение) по последним 200 обработанным выравниваниям Витерби и пропустили все последующие HMM базы данных, когда это среднее значение упало ниже 0,01, что указывает на то, что последние 200 целевых HMM дали очень мало E-значений Витерби ниже 1.
Чтобы избежать необходимости согласовывать тысячи негомологичных целевых HMM с дорогостоящим алгоритмом Витерби, мы ввели критерий раннего завершения в HHblits 2.0,16. Мы усреднили 1 / (1 + E-значение) по последним 200 обработанным выравниваниям Витерби и пропустили все последующие HMM базы данных, когда это среднее значение упало ниже 0,01, что указывает на то, что последние 200 целевых HMM дали очень мало E-значений Витерби ниже 1.
Этот критерий требует, чтобы цели обрабатывались путем уменьшения показателя предварительной фильтрации, в то время как наша векторизованная версия алгоритма Витерби требует, чтобы HMM профиля базы данных упорядочивались по уменьшению длины. Мы решили эту дилемму, отсортировав список целевых HMM, уменьшив оценку предварительной фильтрации, разделив его на равные части (размер по умолчанию 2 000) с уменьшением оценок и сортируя целевые HMM внутри каждого блока по их длине.После того, как каждый фрагмент обработан алгоритмом Витерби, мы вычисляем среднее значение 1 / (1 + E-value) для фрагмента и завершаем работу раньше, когда это число падает ниже 0,01.
Фильтр избыточности MSA на основе SIMD
Чтобы построить профиль HMM из MSA, HH-suite уменьшает избыточность, отфильтровывая последовательности, которые имеют более чем часть seqid_max идентичных остатков с другой последовательностью в MSA. Скалярная версия функции (алгоритм 5) возвращает 1, если две последовательности x и y имеют идентификатор последовательности выше seqid_min и 0 в противном случае.Версия SIMD (алгоритм 6) не имеет ветвей и обрабатывает аминокислоты блоками по 16 (SSE2) или 32 (AVX2). Это примерно в 11 раз быстрее, чем скалярная версия.
.
Ваш комментарий будет первым