Моделирование работы процессора — Документ
Информатика, 11 класс К.Ю. Поляков, Е.А. Еремин
Моделирование
Практические работы
-
Моделирование работы процессора
Напишите программу, которая моделирует работу процессора. Процессор имеет 4 регистра, они обозначаются R0, R1, R2 и R3. Все команды состоят из трех десятичных цифр: код операции, номер первого регистра и номер второго регистра (или число от 0 до 9). Коды команд и примеры их использования приведены в таблице:
Код операции | Описание | Пример | Псевдокод |
1 | запись константы | 128 | R2 := 8 |
2 | копирование значения | 203 | R3 := R0 |
3 | сложение | 331 | R1 := R1 + R3 |
4 | вычитание | 431 | R1 := R1 – R3 |
Обратите внимание, что результат
записывается во второй регистр. Команды вводятся последовательно как
символьные строки. После ввода каждой
строки программа показывает значения
всех регистров.
Команды вводятся последовательно как
символьные строки. После ввода каждой
строки программа показывает значения
всех регистров.
*Добавьте в систему команд умножение, деление и логические операции c регистрами – «И», «ИЛИ», «исключающее ИЛИ».
*Добавьте в систему команд логическую операцию «НЕ». Подумайте, как можно использовать второй регистр.
*Сделайте так, чтобы в команде с кодом 1 можно было использовать шестнадцатеричные значения констант (0-9, A-F).
Добавьте обработку ошибок типа «неверная команда», «неверный номер регистра», «деление на ноль».
**Подумайте, как можно было бы организовать условный переход: перейти на N байт вперед (или назад), если результат последней операции – ноль.
Моделирование движения
Парашютист массой 90 кг разгоняется в свободном падении до скорости 10 м/с и на высоте 50 м раскрывает парашют, площадь которого 55 м2. Коэффициент сопротивления парашюта равен 0,9. Выполните следующие задания:
постройте графики изменения скорости и высоты полета в течение первых 4 секунд;
-
определите, с какой скоростью приземлится парашютист?
сравните результаты моделирования с установившимся значением скорости, вычисленным теоретически.
теоретически | моделирование | |
Скорость приземления, м/с |
Напишите программу, которая моделирует полет мяча, брошенного вертикально вверх, при
мм,
г,
м/с,
с.
Остальные необходимые данные есть в тексте § 9. Выполните следующие задания:
вычислите время полета и максимальную высоту подъема мяча, используя модель движения без сопротивления воздуха:
сравните эти результаты с полученными при моделировании с учетом сопротивления;
без учёта сопротивления
с учётом сопротивления
Время полета, с
Максимальная высота, м
Скорость приземления, м/с
можно ли в этой задаче пренебречь сопротивлением воздуха? почему?
Ответ:
с помощью табличного процессора постройте траекторию движения мяча, а также графики изменения скорости, ускорения и силы сопротивления;
уменьшите шаг до 0,01 с и повторите моделирование; сделайте выводы по поводу выбора шага в данной задаче.
Ответ:
*Выполните моделирование движения мяча, брошенного под углом 45° к горизонту:
определите время полета, максимальную высоту и дальность полета мяча, скорость в момент приземления;
без учёта сопротивления
с учётом сопротивления
Время полета, с
Максимальная высота, м
Дальность полета, м
Скорость приземления, м/с
- сравните результаты со случаем, когда
сопротивление воздуха не учитывается;
сделайте выводы.


Ответ:
Моделирование популяции животных
Для выполнения работы откройте файл-заготовку Популяция.xls.
Постройте графики изменения численности популяции животных для моделей ограниченного и неограниченного роста при , и в течение первых 15 периодов. Определите, когда модель неограниченного роста перестает быть адекватной (отклонение от модели ограниченного роста составляет более 10%).
Ответ:
Используя подбор параметра, определите, при каких коэффициентах модель неограниченного роста остается адекватной в течение не менее 10 периодов.
Ответ:
Используя модель ограниченного роста из предыдущей задачи, выполните моделирование популяции с учетом отлова (). Предполагается, что животных начали отлавливать через 10 лет после начала наблюдений.
постройте график изменения численности животных;
определите количество животных в состоянии равновесия по результатам моделирования; зависит ли оно от начальной численности?
Ответ:
определите количество животных в состоянии равновесия теоретически, из модели ограниченного роста с отловом; сравните это значение с результатами моделирования
Ответ:
Ответ:
Ответ:
*определите максимально допустимый отлов теоретически, из модели ограниченного роста с отловом; сравните это значение с результатами моделирования
Ответ:
Моделирование эпидемии
Для выполнения работы откройте
файл-заготовку Эпидемия. xls.
xls.
При эпидемии гриппа число больных изменяется по формуле
,
где – количество заболевших в -й день, а – количество выздоровевших в тот же день. Число заболевших рассчитывается согласно модели ограниченного роста:
,
где – общая численность жителей, – коэффициент роста и – число переболевших (тех, кто уже переболел и выздоровел, и поэтому больше не заболеет):
.
Считается, что в начале эпидемии заболел 1 человек, все заболевшие выздоравливают через 7 дней и больше не болеют.
Выполните моделирование развития эпидемии при и до того момента, когда количество больных станет равно нулю. Постройте график изменения количества больных.
Ответьте на следующие вопросы:
Когда закончится эпидемия?
Ответ:
Сколько человек переболеет, а сколько вообще не заболеет гриппом?
Ответ:
Каково максимальное число больных в один день?
Ответ:
Изменяя коэффициент , определите, при каких значениях модель явно перестает быть адекватной.
Ответ:
*Сравните модель, использованную в этой работе, со следующей моделью:
, .
Анализируя результаты моделирования, докажите, что эта модель неадекватна. Какие допущения, на ваш взгляд, были сделаны неверно при разработке этой модели?
Ответ:
Сравните поведение двух моделей при , и . Сделайте выводы.
Ответ:
Модель «хищник-жертва»
Для выполнения работы откройте
файл-заготовку ХищникЖертва. xls.
xls.
Выполните моделирование биологической системы «щуки-караси»
где – численность карасей
– численность щук
при следующих значениях параметров:
– коэффициент прироста карасей;
– предельная численность карасей;
– начальная численность карасей;
– начальная численность щук;
– коэффициент смертности щук без пищи;
и – коэффициенты модели.
Постройте на одном поле графики изменения численности карасей и щук в течение 30 периодов моделирования.
Ответьте на следующие вопросы:
Сколько карасей и щук живут в водоеме в состоянии равновесия?
Ответ:
Что влияет на количество рыб в состоянии равновесия: начальная численность хищников и жертв или значения коэффициентов модели?
Ответ:
На что влияет начальная численность хищников и жертв?
Ответ:
Подберите значения коэффициентов, при которых модель становится неадекватна.
Ответ:
Подберите значения коэффициентов, при которых щуки вымирают, а численность карасей достигает предельно возможного значения. Как вы можете объяснить это с точки зрения биологии?
Ответ:
Практическая работа № 10а.
Модель «две популяции»
Для выполнения работы откройте файл-заготовку ДвеПопуляции.xls.
Белки и бурундуки живут в одном лесу и
едят примерно одно и то же (конкурируют
за пищу). Модель, описывающая изменение
численности двух популяций, имеет вид:
Модель, описывающая изменение
численности двух популяций, имеет вид:
Здесь и – численность белок и бурундуков; и – их максимальные численности; и – коэффициенты прироста; и – коэффициенты взаимного влияния.
Объясните, на основании каких предположений была построена эта модель.
Ответ:
Выполните моделирование изменения численности двух популяций в течение 15 периодов при , , , , и . Постройте графики изменения численности обеих популяций на одном поле.
Ответьте на следующие вопросы:
Является ли эта модель системной? Почему?
Ответ:
Какова численность белок и бурундуков в состоянии равновесия?
Ответ:
Что влияет на состояние равновесия?
Ответ:
На что влияет начальная численность животных?
Ответ:
При каком значении коэффициента бурундуки вымрут через 25 лет? (используйте подбор параметра).
Ответ:
Найдите какие-нибудь значения коэффициентов, при которых модель становится неадекватна;
Ответ:
Предложите аналогичную модель взаимного влияния трех видов.
Ответ:
Саморегуляция
Для выполнения работы откройте файл-заготовку Саморегуляция.xls.
Биологи выяснили, что для каждого вида
животных существует некоторая минимальная
численность популяции, которая необходима
для выживания этой колонии. Это может
быть одна пара животных (например, для
ондатр) или даже тысячи особей (для
американских почтовых голубей). Если
количество животных становится меньше
этого минимального значения, популяция
вымирает. Для этого случая предложена
следующая модель изменения численности:
Это может
быть одна пара животных (например, для
ондатр) или даже тысячи особей (для
американских почтовых голубей). Если
количество животных становится меньше
этого минимального значения, популяция
вымирает. Для этого случая предложена
следующая модель изменения численности:
, (*)
Эта модель отличатся от модели ограниченного роста только дополнительным множителем , где и – некоторые числа (параметры), смысл которых вам предстоит выяснить.
Выполните моделирование для 30 периодов при следующих значениях параметров модели:
Сравните результаты, которые дают модель классическая модель ограниченного роста и модель (*). Сделайте выводы и опишите, в чём проявляется саморегуляция для этих моделей.
Ответ:
Постепенно увеличивая коэффициент от 0 до 500, выясните с помощью моделирования, как влияет этот коэффициент на саморегуляцию.
Ответ:
Через 10 периодов в результате изменения природных условия число животных уменьшилось до 400 (то есть, ). Выполните моделирование при этих условиях и опишите, как работает саморегуляция и чем отличается поведение двух сравниваемых моделей.
Ответ:
Повторите моделирование п. 3 при и сделайте аналогичные выводы:
Ответ:
Экспериментируя с моделями, найдите минимальную численность популяции , при которой она выживает в соответствии с моделью (*).
Ответ:
Сделайте выводы о смысле коэффициента в модели (*).
Ответ:
Сравните свойства саморегуляции для модели ограниченного роста и модели (*).

Ответ:
Моделирование работы банка
Для моделирования обслуживания клиентов в банке предложена следующая модель:
где – количество клиентов, вошедших за -ую минуту, а – количество клиентов, обслуженных за это время;
достаточным считается число касс, при которых среднее время ожидания превышает установленный предел не более, чем 5% рабочего времени в течение дня.
Используя эту вероятностную модель работы банка, напишите программу, с помощью которой определите минимальное необходимое количество касс при следующих исходных данных:
, , , .
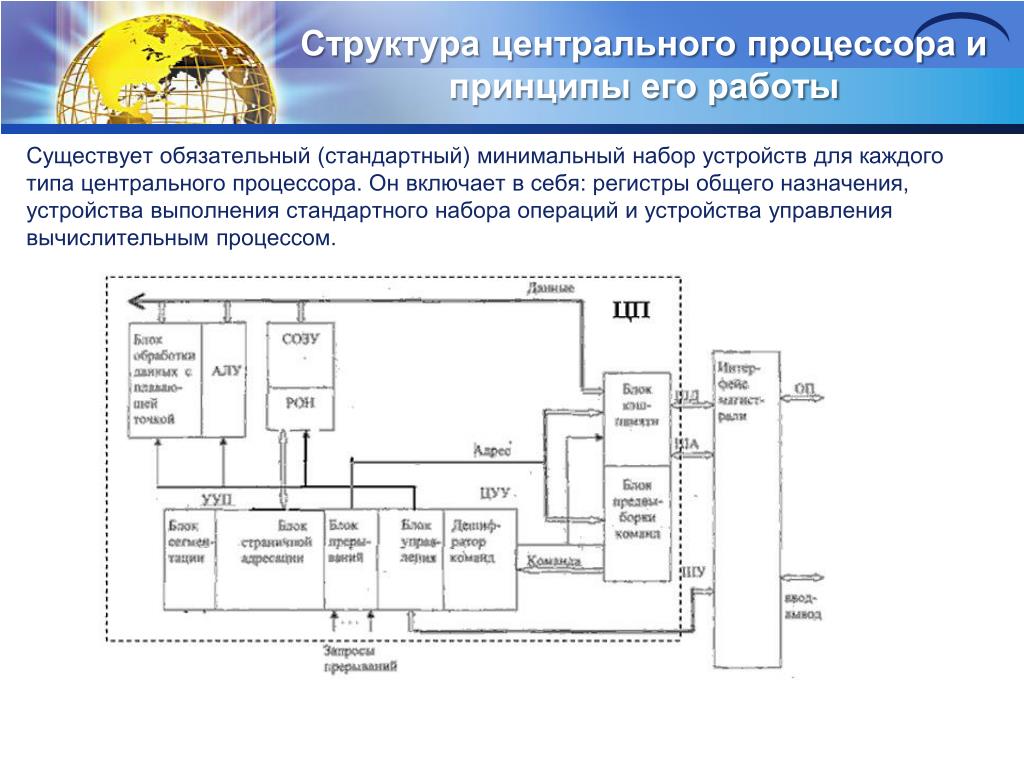
Интерфейс программы «Моделирование работы процессора»
регистре команд хранится предыдущая команда (ADD [0]), в регистре адреса – адрес её операнда [0], в регистре данных и аккумуляторе – значение этого операнда (53) и в счётчике команд – адрес рассматриваемой команды [5].
2.Адрес команды пересылается из программного счётчика в регистр адреса: У7, У1. Надо отметить, что в базовой ЭВМ все пересылки между регистрами выполняются через арифметико-логическое устройство.
3.Из памяти (по команде устройства управления) выбирается содержимое ячейки памяти, адрес которой расположен в регистре адреса и производится увеличение на единицу содержимого счётчика команд: У2, У7, тип операции для АЛУ: увеличение на 1, команда чтения из памяти.
4.Следующий такт – пересылка нового значения в программный счётчик: У8.
5.Содержимое регистра данных пересылается в регистр команд, и устройство управления начинает декодировать команду: У4, У6.
6.Перечисленные действия относятся к «Выборке команды».
7.Расшифровав код операции командыADD [1], устройство управления пересылает её адресную часть(адрес 1) в регистр адреса: У4, У1. Пересылка осуществляется из регистра данных, где ещё сохранилась копия команды.
Пересылка осуществляется из регистра данных, где ещё сохранилась копия команды.
8.Из памяти в регистр данных считывается содержимое ячейки памяти, адрес которой расположен в регистре адреса: У2, команда чтения из памяти.
9.Выполняется операция сложения содержимого регистра данных и аккумулятора: У4, У10, тип операции для АЛУ: сложение операндов.
10.Полученная в арифметико-логическом устройстве сумма пересылается в аккумулятор: У9.
11.Исполнение команды завершено.
Программа служит для моделирования работы процессора при исполнении программы пользователя, набранной в памяти ЭВМ.
Программа «Моделирование работы процессора» рассчитана на запуск на ЭВМ с разрешением экрана не менее 1024 х 768.
9
Запуск программы выполняется выбором команды в меню Пуск.
Пуск \ Программы \ Моделирование работы процессора
После запуска программы на экране появляется главное окнопро граммы (Рис. 4), которое содержит мнемосхему базовой ЭВМ. На мнемосхеме отображается текущие значения всех регистров процессора, а также фрагмент несколько ячеек области памяти.
Пользователь имеет возможность набрать свою программу на языке машинных инструкций и выполнить её в пошаговом режиме на базовой ЭВМ.
Рис. 4. Главное окно программы «Моделирование работы процессора»
2. Окно редактирования (Рис. 5) текста программы вызывается с помощью команды меню программы Программа \ Изменить, или по двойному щелчку мышью по таблице «Память» в главном окне программы.
10
Адрес загружается в ПС перед запуском программы
Указать тип данных, добавляемых в ячейку памяти
Выбранная ячейка памяти
Добавить
сформированную команду или число в выбранную ячейку памяти
Очистить выбранную ячейку памяти
Рис. 5. Окно редактирования программы
3.Программа пользователя может исполняться либо непрерывно, либо
состановом после выполнения каждой микрокоманды. Настройка режима исполнения программы пользователя(непрерывно или по усмотрению) осуществляется с помощью окна«Настройка», которое вызывается по ко-
манде Программа \ Настройка.
4. Управление запуском, остановом и поэтапным исполнением осуществляется с помощью кнопок панели управления в левой нижней части главного окна программы (Рис. 6).
Вызов окна редактирования программы пользователя Начать выполнения программы пользователя Переход к исполнению следующей микрокоманды Остановить выполнение программы пользователя
Вызов окна «Настройка» Помощь Выход из программы «Моделирование работы процессора»
Рис. 6. Панель управления программой
11
5. Программа пользователя может быть сохранена в файле данных и загружена вновь с помощью команд меню Файл.
Задание для самостоятельного выполнения
1.Набрать программу сложения двух чисел (табл. 2) и изучить работу базовой ЭВМ на примере выполнения данной программы.
2.Разработать программу, выполняющую следующие действия:
№ | программа | Хранение операндов и ре- |
|
| зультатов |
1 | y = a–(b+c) | До программы |
| z = a AND d |
|
2 | y = (a–b)+c+d | После программы |
| z = a OR 2d |
|
3 | y = a AND b+c | До программы |
| z = b |
|
4 | y = a AND b+c | После программы |
| z = b+c |
|
5 | y = a OR b+c | До программы |
| z = b-c |
|
6 | y = a AND b-a+d | После программы |
| z = (b+c) OR a |
|
7 | y = a AND b OR a | До программы |
| z = b-c |
|
|
|
|
8 | y = a-(b AND c) | После программы |
| z = 2b+c |
|
9 | y = a-(b AND c) | До программы |
| z = c+b |
|
|
|
|
10 | y = a OR (b AND c) | После программы |
| z = 2c AND d |
|
11 | y = a AND c | До программы |
| z = 2y+3b |
|
12 | y = (a AND c) OR a | После программы |
| z = 2b-c |
|
13 | y = a+(b OR c) | До программы |
| z = (b+2c) AND d |
|
14 | y = a OR b+a | После программы |
| z = b-c+d |
|
12
Моделирование центрального процессора с помощью интерпретации
Двоичная трансляция и симуляция
Двоичная трансляция и симуляция 28.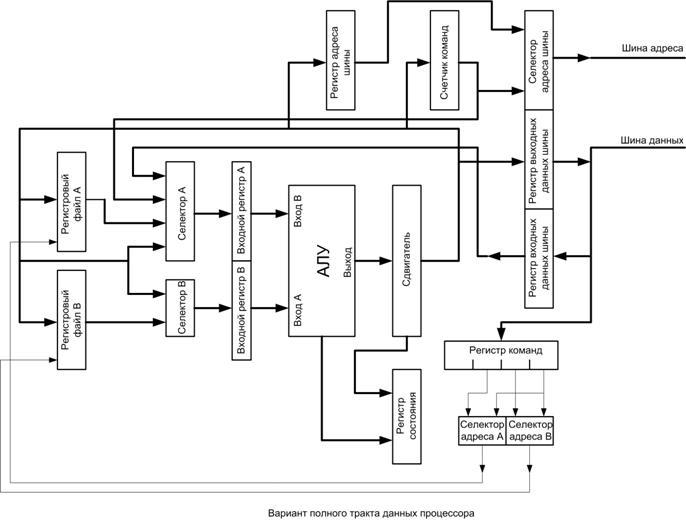 10.2013 [email protected] Григорий Речистов [email protected] Статическая ДТ Динамическая ДТ Проблемы и решения 2 Вопросы к прошлой лекции 1. Определение процесса
10.2013 [email protected] Григорий Речистов [email protected] Статическая ДТ Динамическая ДТ Проблемы и решения 2 Вопросы к прошлой лекции 1. Определение процесса
2014 МГУ/ВМК/СП. Лекция февраля
Лекция 2 12 февраля Архитектура фон Неймана mov eax, ecx mov eax, dword [0x2014] add eax, 0xff 1. Двоичное кодирование информации 2. Неразличимость команд и данных Вспоминаем Си-машину 3. Адресуемость
ПодробнееСимуляция, управляемая событиями
Курс «Программное моделирование вычислительных систем» Григорий Речистов [email protected] 6 апреля 2015 г. 1 Таймер 2 Отложенный ответ 3 Теория 4 Практический пример 5 Косимуляция 6 Практический
ПодробнееЛекция 7. Интерпретаторы и компиляторы
Лекция 7. Интерпретаторы и компиляторы Абстрактные машины и реальные процессоры Язык программирования машинный код некоторого абстрактного компьютера, отличающегося от реальных процессоров. Цель трансляции
ПодробнееОсновы программного конструирования
Лектор: А.Д.Хапугин Основы программного конструирования Лекция 5. Общие понятия архитектур ЭВМ — продолжение (начало см. в лекциях 3 и 4) Материалы доступны в Интернете по адресу: http://www.excelsior.ru/afti/
Подробнее2017 МГУ/ВМК/СП. Лекция февраля
Лекция 5 22 февраля Организация вызова функций Вопросы Передача управления и возвращение обратно Вычисление значений фактических параметров и их размещение Передача возвращаемого значения Размещение автоматических
Подробнее2019 МГУ/ВМК/СП. Лекция февраля
Лекция 5 27 февраля Организация вызова функций Вопросы Передача управления и возвращение обратно Вычисление значений фактических параметров и их размещение Передача возвращаемого значения Размещение автоматических
ПодробнееРаспределение памяти
Распределение памяти Распределение памяти — это процесс, в результате которого отдельным элементам исходной программы ставятся в соответствие адрес, размер и атрибуты области памяти, необходимой для размещения
ПодробнееЯзыки программирования
3. Влияние архитектуры Структура компьютера 1. Данные; 2. Элементарные операции; 3. Управление последовательностью действий; 4. Доступ к данным; 5. Управление памятью; 6. Операционная среда. 2 Данные Хранение:
Влияние архитектуры Структура компьютера 1. Данные; 2. Элементарные операции; 3. Управление последовательностью действий; 4. Доступ к данным; 5. Управление памятью; 6. Операционная среда. 2 Данные Хранение:
1 ФУПМ 2-й семестр. Домашние задания.
1 ФУПМ 2-й семестр. Домашние задания. Первое задание. Требуется реализовать эмулятор компьютера FUMP2 с заданной архитектурой. FUPM2 есть машина с архитектурой Фон-Неймана с адресным пространством в 2
ПодробнееГенератор тестовых программ
RISC-V Developers Forum 7 декабря, Москва Генератор тестовых программ MicroTESK for RISC-V Андрей Татарников Институт системного программирования им. В.П. Иванникова Российской академии наук Введение Тестирование
ПодробнееВведение в информатику
Введение в информатику Е. А. Яревский физический факультет СПбГУ 2018 ЛЕКЦИЯ 7 Архитектура и устройство компьютера Расширения архитектуры фон-неймана Принципы фон Неймана Принцип двоичного кодирования
Подробнее2017 МГУ/ВМК/СП. Лекция A. 15 марта
Лекция A 15 марта Оптимизация доступа к элементам массива a j-ый столбец #define N 16 typedef int fix_matrix[n][n]; Вычисления Проход по всем элементам в столбце j Оптимизация Выборка последовательных
ПодробнееПрактикум (лабораторный). Дополнение 1
Практикум (лабораторный). Дополнение 1 Лабораторная работа 1. Представление информации 3.3.Преобразование дробной части десятичного числа Преобразование дробной части выполняется за счет умножения на основание
Подробнее2019 МГУ/ВМК/СП. Лекция 0xA. 16 марта
Лекция 0xA 16 марта Матрица N X N Фиксированные размерности Значение N известно во время компиляции Динамически задаваемая размерность. Требуется явное преобразование индексов Традиционный способ реализации
Требуется явное преобразование индексов Традиционный способ реализации
Джон фон Нейман ( )
Джон фон Нейман (1903-1957) Архитектура Джона фон Неймана Кодирование двоичным кодом. Переход на двоичную логику позволил использовать хорошо разработанный к тому моменту аппарат алгебры логики для анализа
ПодробнееИ.В. Музылёва, 2015 Страница 1
Тема 12 Составление линейных программ и их оформление Теория Линейными называются программы, состоящие из команд, выполняемых одна за другой, без переходов и подпрограмм. Примечания: 1) В учебном стенде
ПодробнееКЛАССИФИКАЦИЯ ROP ГАДЖЕТОВ
КЛАССИФИКАЦИЯ ROP ГАДЖЕТОВ Алексей Вишняков [email protected] Москва, 02 декабря 2016 г. Актуальность В современных программах могут присутствовать тысячи программных дефектов Техника возвратно-ориентированного
Подробнее2015 МГУ/ВМК/СП. Лекция февраля
Лекция 5 21 февраля Далее Архитектура фон Неймана Архитектура IA-32 Вычисление арифметических выражений Передача управления Организация вызова функций 2 Организация вызова функций Вопросы Передача управления
ПодробнееРаспределение памяти
Распределение памяти Распределение памяти — это процесс, в результате которого отдельным элементам исходной программы ставятся в соответствие адрес, размер и атрибуты области памяти, необходимой для размещения
ПодробнееВиртуализация. Антоненко Виталий
Виртуализация Антоненко Виталий Виртуализация «на пальцах» Виртуализация компьютера означает, что можно заставить компьютер казаться сразу несколькими компьютерами одновременно или совершенно другим компьютером.
Лекция 5. Центральный микропроцессор
Лекция 5 Центральный микропроцессор Архитектура ПЛК 2 Под архитектурой микроконтроллера понимают комплекс его аппаратных и программных средств, предоставляемых пользователю. Основные модули ПЛК: центральный
Подробнее2014 МГУ/ВМК/СП. Лекция марта
Лекция 11 19 марта Как сохранить место Размещаем большие типы первыми struct S4 { char c; int i; char d; } *p; struct S5 { int i; char c; char d; } *p; Результат (K=4) c 3 байта i d 3 байта i c d 2 байта
ПодробнееЛекция 5. Анализ быстродействия программ
Название Лекция 5. Анализ быстродействия программ Инструменты разработки быстрых программ 2 января 2016 г. Лекция 5 1 / 21 Виды инструментов Методы измерения производительности программ Виды анализа Принцип
Подробнее2017 МГУ/ВМК/СП. Лекция D. 25 марта
Лекция D 25 марта Какие есть компиляторы и соглашения о вызове функций? 2017 МГУ/ВМК/СП Компиляторы LLVM clang (open source) GNU gcc (open source) Microsoft Visual Studio vc Intel icc еще компиляторы PGI
ПодробнееОсновные функции микропроцессора :
Архитектура МП Основные понятия Микропроцессор — это программно-управляемое устройство, предназначенное для обработки цифровой информации и управления процессами этой обработки, выполненной в виде одной
Подробнее2018 МГУ/ВМК/СП. Лекция 0xA. 14 марта
Лекция 0xA 14 марта zip_dig cmu = { 1, 5, 2, 1, 3 ; zip_dig mit = { 0, 2, 1, 3, 9 ; zip_dig ucb = { 9, 4, 7, 2, 0 ; #define UCOUNT 3 int *univ[ucount] = {mit, cmu, ucb; Переменная univ представляет собой
Подробнее2016 МГУ/ВМК/СП.
 Лекция 0xB. 16 марта
Лекция 0xB. 16 мартаЛекция 0xB 16 марта Выполнение правил выравнивания для полей Внутри структуры Выравнивание должно выполняться для каждого поля Размещение всей структуры Для каждой структуры определятся требование по выравниванию
ПодробнееМашинное представление чисел
Машинное представление чисел Целые числа Беззнаковые числа В современных ЭВМ для представления чисел используется двоичная система счисления. При использовании для представления положительных целых чисел
ПодробнееЦифровые сигнальные процессоры TMS320C674x
Основы программирования цифровых сигнальных процессоров Цифровые сигнальные процессоры TMS320C674x Конспект лекций РГРТУ, 2018 Лекция 2. Архитектура ЦСП операционное ядро По фон-нейману электронно-вычислительная
ПодробнееРазделитель программ для записи в ППЗУ
Разделитель программ для записи в ППЗУ 5 5.1. Введение Программа разделителя программ выделяет ПЗУ части из выходного.exe файла редактора связей и формирует информацию для использования программаторами
ПодробнееГлава 4. Форматы команд и данных
Глава 4. Форматы команд и данных В этой главе вводятся основные определения и рассматриваются важные базовые понятия, которые будут необходимы для дальнейшего изучения архитектуры ЭВМ. С этой целью будут
ПодробнееТ О Ч Н О С Т Ь — О С Н О В А Д О В Е Р И Я
Т О Ч Н О С Т Ь — О С Н О В А Д О В Е Р И Я Измерение ИМС памяти при помощи тестера FORMULA. Чехович С.Д. Обзор структуры схемы формирования последовательности тестовых векторов Тестера. Формирование тестовых
ПодробнееЛекция 1.
 Языки и трансляторы
Языки и трансляторыЛекция 1 Языки и трансляторы Компьютерные языки Лексика (словарь) Синтаксис (правила построения «предложений») Семантика (смысл «предложений»)! Формализация математическая модель эффективная реализация
ПодробнееМНОГОЯДЕРНАЯ АРХИТЕКТУРА УНИВЕРСАЛЬНОЙ
МНОГОЯДЕРНАЯ АРХИТЕКТУРА УНИВЕРСАЛЬНОЙ 32-ух РАЗРЯДНОЙ УЧЕБНОЙ МАШИНЫ Семенов А. А. Московский государственный институт радиотехники, электроники и автоматики (технический университет) Универсальная 32х
ПодробнееВычислительный конвейер
Вычислительный конвейер Pipeline http://arkov.narod.ru В.Арьков 1 Производственный конвейер Assembly line Поточная организация производства постепенная сборка и механическое перемещение изделия от одного
ПодробнееВведение в информатику
Введение в информатику Е.А.Яревский физический факультет СПбГУ 2016 Лекция 5 Архитектура и устройство компьютера История развития ЭВМ 1) 1642-1945 Механические компьютеры 2) 1945-1955 Электронные лампы
Подробнее2019 МГУ/ВМК/СП. Лекция 0xD. 30 марта
Лекция 0xD 30 марта Зачем переходить на 64-х разрядную архитектуру? Особенности полноценной 64-х разрядной процессорной архитектуры АЛУ оперирует 64-х разрядными данными (Большой) набор 64-х разрядных
ПодробнееМоделирование процессора MIPS в Simulink
${form_setting.title_name}
${form_setting.first_name_required}
* ${form_setting.first_name_required} ${form_setting. title_fam}
title_fam}
${form_setting.last_name_required}
* ${form_setting.last_name_required}${form_setting.title_otchestvo}
Для преподавателей отчество обязательно
* Для преподавателей отчество обязательно${form_setting.title_phone}
*${country_title}
${phone.title} ${form_setting.phone_required} ${form_setting.country_required}${form_setting.type_action}
*${action.title}
${form_setting.type_action_required}${form_setting.type_action_required}
${form_setting.title_find_company}
* Выберите организацию Такой организации нет${org.title}
Выберите организацию
Некорректный url сайтаНекорректный url сайта
${form_setting.title_no_company}
${form_setting.title_fac}
${form_setting.facultet_required}
${Data.select_facultet.title}
${faculty.title}
${form_setting.facultet_required}Не нашел в списке Факультет
${form_setting.title_caf}
${form_setting.cafedra_required}
${Data.select_cafedra}
${cafedra.title}
${form_setting.cafedra_required}Не нашел в списке Кафедру
${form_setting.title_position}
${form_setting.position_required}
* ${ error }${form_setting.title_departament}
Реферат по информатике на тему «Процессоры и моделирование работы процессоров»
Муниципальное автономное общеобразовательное учреждение города Калининграда средняя образовательная школа №25 с углубленным изучением отдельных предметов им. И.В. Грачева
Реферат
по теме: «Процессоры и моделирование работы процессора»
Реферат составил:
Ученик 10Б класса
Фисюк Максим
Проверил:
учитель информатики
первой категории
Чернышова И.В.
Калининград
2020 г.
Содержание Стр.
Введение……………………………………………….…………………. 3
1 История развития процессоров…………………….…………………. 4
2 Алгоритм работы процессора……………………….………………… 10
2.1 Устройство процессора…………………….……………………….. 10
2.2 Алгоритм работы процессора…………………………………………………… 11
2.3 Прерывание процессора…………………………………………………………… 12
3 Моделирование работы процессора…………………………………………….. 15
Заключение…………………………………………………………………………………… 17
Список источников…………………………………………………………………… 18
Введение
Одним из основных устройств современного персонального компьютера является центральный процессор. Который, на первый взгляд, просто выращенный по специальной технологии кристалл кремния. Однако этот кристалл содержит в себе множество отдельных элементов – транзисторов, которые в совокупности и наделяют компьютер способностью «думать».
История создания микропроцессора началась еще в 50-х годах, когда на смену электронным лампам пришли компактные «электронные переключатели» — транзисторы, затем – интегральные схемы, в которых впервые удалось объединить на одном кристалле кремния сотни крохотных транзисторов. Но все-таки отсчет летоисчисления компьютерной эры ведут с 1971 года, с момента появления первого микропроцессора.
За три десятка лет, прошедших с этого знаменательного дня, процессоры сильно изменились. Современный процессор — это не просто набор транзисторов, а целая система множества важных устройств.
1 История развития процессоров
В настоящее время существуют много фирм по производству процессоров для персональных компьютеров. Это Intel, AMD, Cyrix, VIA, Centaur/IDT, NexGen, и многие другие. Однако наиболее популярными являются Intel и AMD. Развитие процессоров этих ведущих фирм мы и постараемся рассмотреть.
Однако прежде чем углубляться в историю производства процессоров необходимо дать характеристику некоторым техническим терминам характеризующих процессор.
Тактовая частота – это скорость работы процессора, а именно количество операций выполненных на протяжении 1 секунды.
Поколения – поколения процессоров отличаются друг от друга скоростью работы, архитектурой, исполнением и внешним видом. Если просмотреть поколения процессоров фирмы Intel то их было 8 (8088, 286, 386, 486, Pentium, PentiumII, PentiumIII, PentiumIV).
Модификация –у ведущих и постоянно конкурирующих фирм Intel и AMD есть две модификации процессоров. У Intel это Pentium и Celeron, у AMD это Athlon и Duron. Pentium и Athlon это дорогие процессоры для графических станций или серверов, а Celeron и Duron это процессоры для домашних компьютеров.
Технология производства – под технологией производства в данном случае понимают размер минимальных элементов процессора. Так в 1999 году фирмы перешли на новую, 0,13 – микронную технологию.
КЭШ-память первого уровня – небольшая (несколько десятков килобайт) сверхбыстрая память, предназначенная для хранения промежуточных результатов вычислений.
КЭШ-память второго уровня – эта память более медленная, но она больше от 128 до 512 кбайт.
Центральный процессор (ЦП; также центра́льное процессорное устройство — ЦПУ; англ. centralprocessingunit, CPU, дословно — центральное обрабатывающее устройство, часто просто процессор) — электронный блок либо интегральная схема, исполняющая машинные инструкции (код программ), главная часть аппаратного обеспечения компьютера или программируемого логического контроллера. Иногда называют микропроцессором или просто процессором.
Изначально термин центральное процессорное устройство описывал специализированный класс логических машин, предназначенных для выполнения сложных компьютерных программ. Вследствие довольно точного соответствия этого назначения функциям существовавших в то время компьютерных процессоров он естественным образом был перенесён на сами компьютеры. Начало применения термина и его аббревиатуры по отношению к компьютерным системам было положено в 1960-е годы. Устройство, архитектура и реализация процессоров с тех пор неоднократно менялись, однако их основные исполняемые функции остались теми же, что и прежде.
Главными характеристиками ЦПУ являются: тактовая частота, производительность, энергопотребление, нормы литографического процесса, используемого при производстве (для микропроцессоров), и архитектура.
Ранние ЦП создавались в виде уникальных составных частей для уникальных и даже единственных в своём роде компьютерных систем. Позднее от дорогостоящего способа разработки процессоров, предназначенных для выполнения одной единственной или нескольких узкоспециализированных программ, производители компьютеров перешли к серийному изготовлению типовых классов многоцелевых процессорных устройств. Тенденция к стандартизации компьютерных комплектующих зародилась в эпоху бурного развития полупроводниковых элементов, мейнфреймов и мини-компьютеров, а с появлением интегральных схем она стала ещё более популярной. Создание микросхем позволило ещё больше увеличить сложность ЦП с одновременным уменьшением их физических размеров. Стандартизация и миниатюризация процессоров привели к глубокому проникновению основанных на них цифровых устройств в повседневную жизнь человека. Современные процессоры можно найти не только в таких высокотехнологичных устройствах, как компьютеры, но и в автомобилях, калькуляторах, мобильных телефонах и даже в детских игрушках. Чаще всего они представлены микроконтроллерами, где, помимо вычислительного устройства, на кристалле расположены дополнительные компоненты (память программ и данных, интерфейсы, порты ввода-вывода, таймеры и др.). Современные вычислительные возможности микроконтроллера сравнимы с процессорами персональных ЭВМ десятилетней давности, а чаще даже значительно превосходят их показатели.
История развития производства процессоров полностью соответствует истории развития технологии производства прочих электронных компонентов и схем.
Первым этапом, затронувшим период с 1940-х по конец 1950-х годов, было создание процессоров с использованием электромеханических реле, ферритовых сердечников (устройств памяти) и вакуумных ламп. Они устанавливались в специальные разъёмы на модулях, собранных в стойки. Большое количество таких стоек, соединённых проводниками, в сумме представляло процессор. Отличительными особенностями были низкая надёжность, низкое быстродействие и большое тепловыделение.
Вторым этапом, с середины 1950-х до середины 1960-х, стало внедрение транзисторов. Транзисторы монтировались уже на близкие к современным по виду платы, устанавливавшиеся в стойки. Как и ранее, в среднем процессор состоял из нескольких таких стоек. Возросло быстродействие, повысилась надёжность, уменьшилось энергопотребление.
Третьим этапом, наступившим в середине 1960-х годов, стало использование микросхем. Первоначально использовались микросхемы низкой степени интеграции, содержавшие простые транзисторные и резисторные сборки, затем, по мере развития технологии, стали использоваться микросхемы, реализующие отдельные элементы цифровой схемотехники (сначала элементарные ключи и логические элементы, затем более сложные элементы — элементарные регистры, счётчики, сумматоры), позднее появились микросхемы, содержащие функциональные блоки процессора — микропрограммное устройство, арифметическо-логическое устройство, регистры, устройства работы с шинами данных и команд.
Четвёртым этапом, в начале 1970-х годов, стало создание, благодаря прорыву в технологии, БИС и СБИС (больших и сверхбольших интегральных схем, соответственно), микропроцессора — микросхемы, на кристалле которой физически были расположены все основные элементы и блоки процессора. Фирма Intel в 1971 году создала первый в мире 4-разрядный микропроцессор 4004, предназначенный для использования в микрокалькуляторах. Постепенно практически все процессоры стали выпускаться в формате микропроцессоров. Исключением долгое время оставались только малосерийные процессоры, аппаратно оптимизированные для решения специальных задач (например, суперкомпьютеры или процессоры для решения ряда военных задач) либо процессоры, к которым предъявлялись особые требования по надёжности, быстродействию или защите от электромагнитных импульсов и ионизирующей радиации. Постепенно, с удешевлением и распространением современных технологий, эти процессоры также начинают изготавливаться в формате микропроцессора.
Сейчас слова «микропроцессор» и «процессор» практически стали синонимами, но тогда это было не так, потому что обычные (большие) и микропроцессорные ЭВМ мирно сосуществовали ещё, по крайней мере, 10—15 лет, и только в начале 1980-х годов микропроцессоры вытеснили своих старших собратьев. Тем не менее, центральные процессорные устройства некоторых суперкомпьютеров даже сегодня представляют собой сложные комплексы, построенные на основе микросхем большой и сверхбольшой степени интеграции.
Переход к микропроцессорам позволил потом создать персональные компьютеры, которые проникли почти в каждый дом.
Первым общедоступным микропроцессором был 4-разрядный Intel 4004, представленный 15 ноября 1971 года корпорацией Intel. Он содержал 2300 транзисторов, работал на тактовой частоте 92,6 кГц и стоил 300 долларов.
Далее его сменили 8-разрядный Intel 8080 и 16-разрядный 8086, заложившие основы архитектуры всех современных настольных процессоров. Из-за распространённости 8-разрядных модулей памяти был выпущен дешёвый 8088, упрощенная версия 8086 с 8-разрядной шиной данных.
Затем последовала его модификация, 80186.
В процессоре 80286 появился защищённый режим с 24-битной адресацией, позволявший использовать до 16 Мб памяти.
Процессор Intel 80386 появился в 1985 году и привнёс улучшенный защищённый режим, 32-битную адресацию, позволившую использовать до 4 Гб оперативной памяти и поддержку механизма виртуальной памяти. Эта линейка процессоров построена на регистровой вычислительной модели.
Параллельно развиваются микропроцессоры, взявшие за основу стековую вычислительную модель.
За годы существования микропроцессоров было разработано множество различных их архитектур. Многие из них (в дополненном и усовершенствованном виде) используются и поныне. Например, Intel x86, развившаяся вначале в 32-битную IA-32, а позже в 64-битную x86-64 (которая у Intel называется EM64T). Процессоры архитектуры x86 вначале использовались только в персональных компьютерах компании IBM (IBM PC), но в настоящее время всё более активно используются во всех областях компьютерной индустрии, от суперкомпьютеров до встраиваемых решений. Также можно перечислить такие архитектуры, как Alpha, POWER, SPARC, PA-RISC, MIPS (RISC-архитектуры) и IA-64 (EPIC-архитектура).
В современных компьютерах процессоры выполнены в виде компактного модуля (размерами около 5×5×0,3 см), вставляющегося в ZIF-сокет (AMD) или на подпружинивающую конструкцию — LGA (Intel). Особенностью разъёма LGA является то, что выводы перенесены с корпуса процессора на сам разъём — socket, находящийся на материнской плате. Большая часть современных процессоров реализована в виде одного полупроводникового кристалла, содержащего миллионы, а с недавнего времени даже миллиарды транзисторов.
2 Алгоритм работы процессора
2.1 Устройство процессора
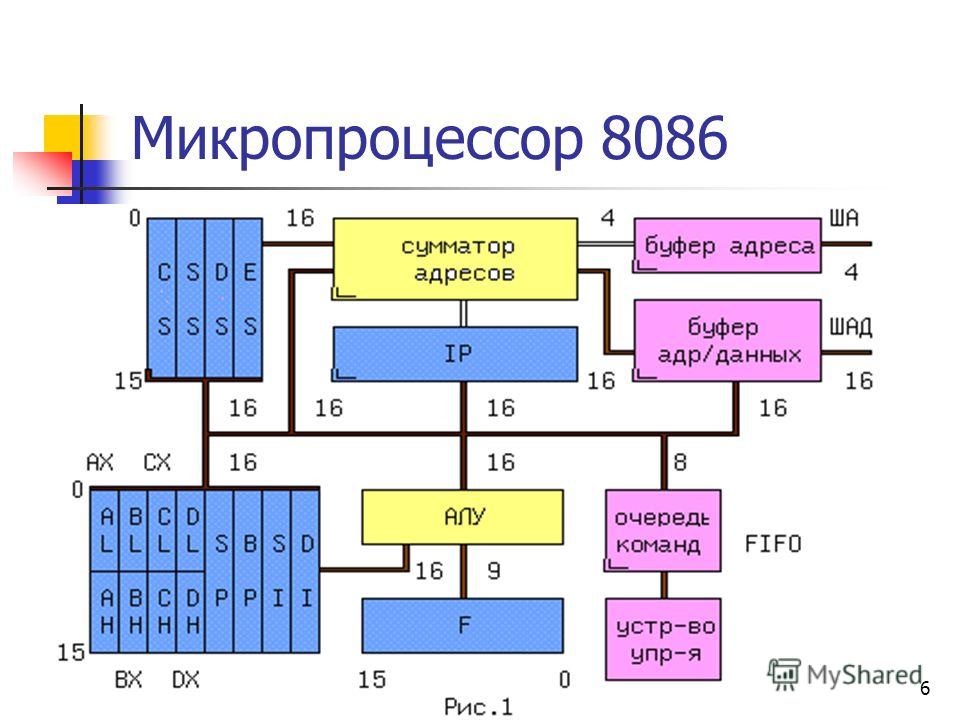
Основные функциональные компоненты процессора
Ядро: Сердце современного процессора — исполняющий модуль. Pentium имеет два параллельных целочисленных потока, позволяющих читать, интерпретировать, выполнять и отправлять две инструкции одновременно.
Предсказатель ветвлений: Модуль предсказания ветвлений пытается угадать, какая последовательность будет выполняться каждый раз когда программа содержит условный переход, так чтобы устройства предварительной выборки и декодирования получали бы инструкции готовыми предварительно.
Блок плавающей точки. Третий выполняющий модуль внутри Pentium, выполняющий нецелочисленные вычисления
Первичный кэш: Pentium имеет два внутричиповых кэша по 8kb, по одному для данных и инструкций, которые намного быстрее большего внешнего вторичного кэша.
Шинный интерфейс: принимает смесь кода и данных в CPU, разделяет их до готовности к использованию, и вновь соединяет, отправляя наружу.
Рис. 1 Внутреннее строение процессора
Все элементы процессора синхронизируются с использованием частоты часов, которые определяют скорость выполнения операций. Самые первые процессоры работали на частоте 100kHz, сегодня рядовая частота процессора — 2000MHz, иначе говоря, часики тикают 2000 миллионов раз в секунду, а каждый тик влечет за собой выполнение многих действий. Счетчик Команд (PC) — внутренний указатель, содержащий адрес следующей выполняемой команды. Когда приходит время для ее исполнения, Управляющий Модуль помещает инструкцию из памяти в регистр инструкций (IR). В то же самое время Счетчик команд увеличивается, так чтобы указывать на последующую инструкцию, а процессор выполняет инструкцию в IR. Некоторые инструкции управляют самим Управляющим Модулем, так если инструкция гласит ‘перейти на адрес 2749’, величина 2749 записывается в Счетчик Команд, чтобы процессор выполнял эту инструкцию следующей.
Многие инструкции задействуют Арифметико-логическое Устройство (АЛУ), работающее совместно с Регистрами Общего Назначения — место для временного хранения, которое может загружать и выгружать данные из памяти. Типичной инструкцией АЛУ может служить добавление содержимого ячейки памяти к регистру общего назначения. АЛУ также устанавливает биты Регистра Состояний (Statusregister — SR) при выполнении инструкций для хранения информации о ее результате. Например, SR имеет биты, указывающие на нулевой результат, переполнение, перенос и так далее. Модуль Управления использует информацию в SR для выполнения условных операций, таких как ‘перейти по адресу 7410 если выполнение предыдущей инструкции вызвало переполнение’.
Это почти все что касается самого общего рассказа о процессорах — почти любая операция может быть выполнена последовательностью простых инструкций, подобных описанным.
2.2 Алгоритм работы процессора
Весь алгоритм работы процессора можно описать в трех строчках
НЦ
| чтение команды из памяти по адресу, записанному в СК
| увеличение СК на длину прочитанной команды
| выполнение прочитанной команды
КЦ
Однако для полного представления необходимо определить логические схемы выполнения тех или иных команд, вычисления величин, а это уже функции Арифметико-логического Устройства.
Арифметико-логическое устройство (АЛУ)— блок процессора, который под управлением устройства управления (УУ) служит для выполнения арифметических и логических преобразований (начиная от элементарных) над данными, называемыми в этом случае операндами. Разрядность операндов обычно называют размером или длиной машинного слова.
2.3 Прерывания процессора
При работе процессорной системы могут возникать особые случаи, когда процессор вынужден прерывать работу текущей программы и переходить к обработке этого особого случая, более срочного и важного. Причинами прерывания текущей программы может быть:
внешний сигнал по шине управления — маскируемых прерываний и немаскируемого прерывания;
аномальная ситуация, сложившаяся при выполнении команды программы и препятствующую ее дальнейшему выполнению;
находящаяся в программе команда прерывания.
Первая из указанных выше причин относится к аппаратным прерываниям, а две другие — к программным прерываниям. Отметим, что аппаратные прерывания непредсказуемы и могут возникать в любые моменты времени.
С помощью аппаратных прерываний осуществляется взаимодействие процессора с устройствами ввода-вывода ( клавиатурой, диском, модемом и т.п.), таймером и внутренними часами, сообщается о возникновении ошибки на шине или в памяти, об аварийном выключении сети и т.п. При возникновении аппаратного прерывания процессор выявляет его источник, сохраняет минимальный контекст текущей программы (включая адрес возврата), и переключается на специальную программу — обработчик прерывания ( interrupthandler). Эта программа правильно реагирует на возникшую ситуацию (например, помещает символ с клавиатуры в буфер, считывает сектор с диска и т.п.), что называется 1обслуживанием прерывания. После обслуживания прерывания процессор возвращается к прерванной программе, как будто прерываний не было.
Программные прерывания обычно называются особыми случаями, или исключениями (exception). Особые случаи возникают, например, при делении на ноль, нарушения при защите по привилегиям, превышении длины сегмента, выходе за границу массива. Как правило, предсказать эти исключения невозможно. Однако встречающаяся в программе 1команда прерывания вполне предсказуема и находится под управлением программиста. Реакция процессора на программное прерывание такое же, как и на аппаратное прерывание, однако его обработка производится 1обработчиком особого случая (exceptionhandler).
Все особые случаи квалифицируются на:
Нарушение(fault). Особый случай, который процессор может обнаружить до возникновения фактической ошибки (например — нарушение правил привилегий). После обработки нарушения можно продолжить программу, осуществив повторное выполнение (рестарт) виноватой команды. Иногда это исключение называют отказом.
Ловушка(trap). Особый случай, который возникает после окончания виноватой программы. После обслуживания ловушки процессор продолжает выполнение программы с команды, находящейся после виноватой. Типичный пример — команда прерывания INT n в процессорах семейства x86 или прерывание при переполнении.
Авария(abort) — возникает при столь серьезной ошибке, что контекст программы теряется и продолжать ее невозможно. Причину аварии установить нельзя, поэтому рестарт невозможен и ее необходимо прекратить. Иногда авария называется выходом из процесса.
Обработка всех прерывания и особых случаев происходит, в общем, одинаково и состоит из двух основных этапов. На первом этапе процессор выполняет некоторые «рефлексивные» операции, которые одинаковы для всех прерываний и исключений, и которыми программист управлять не может. На втором этапе запускается созданный программистом обработчик прерывания или исключения. Все служебные действия процессор производит автоматически.
3 Моделирование работы процессора
Разгон компьютеров — процесс увеличения тактовой частоты (и напряжения) компонента компьютера сверх штатных режимов с целью увеличения скорости его работы. Повышение частоты может достигать максимального значения, при котором сохраняется стабильность работы системы в необходимом для пользователя режиме. При разгоне повышается тепловыделение, энергопотребление, шум, уменьшается рабочий ресурс.
Конечная цель разгона — повышение производительности оборудования. Побочными эффектами могут быть повышение шума и тепловыделения, нестабильности, особенно при условии несоблюдения правил, подразумевающих усиление охлаждающего оборудования, улучшения питания компонентов, тонкой настройки разгона.
Противоположную цель ставит андерклокинг — снизить частоту работы оборудования (и, иногда, необходимого для неё напряжения) и этим достичь снижения тепловыделения, шума, а иногда и нестабильности. Может быть особенно актуальным для тихих помещений, экономии энергии или заряда батареи.
Могут быть разогнана центральные процессоры, память, видеокарты, матплаты, роутеры и прочее.
Классическим методом разгона может быть задание параметров через интерфейс BIOS оборудования и установку там более высоких значений частот работы компонентов системы, нежели штатные. Другой метод — перепрошивка BIOS’а альтернативной от штатной микропрограммой, имеющей уже другие параметры частот и напряжения по умолчанию. Третий метод — повышение частот через операционную систему с помощью специального разгонного программного обеспечения.
Для улучшения охлаждения и снижения уровня шума ставят жидкостное охлаждение, более эффективные и не всегда менее шумные вентиляторы взамен штатных, меняют термопасту, ставят более производительные кулеры. Некоторые типы центральных процессоров подвергаются конструктивной доработке с целью снижения теплового сопротивления между кристаллом и кулером путём удаления защитной крышки процессора и замены термопасты на более новую или на жидкий металл, но уже в самом процессоре, иногда может встречаться припой, который превосходит термопасту по теплопроводности («скальпирование»). Для проверки стабильности используется программное обеспечение, приводящее оборудование в предельный режим нагрузки в тот момент, когда оно уже работает на повышенных частотах.
Для тестов стабильности компонентов компьютеров используются программное обеспечение такое как: Prime95, AIDA64, Super PI, LINPACK, SiSoft Sandra, BOINC, Memtest86+, OCCT.
Заключение
Переход на новые технологии изготовления процессоров, разработка новых алгоритмов их работы является перспективным продвижением данной отрасли. По прогнозам ученых скорость процессоров через 10 лет может достичь 20-ти кратного увеличения по сравнению с современными процессорами.
Автоматизм работы процессора, возможность выполнения длинных последовательных команд без участия человека – одна из основных отличительных особенностей ЭВМ как универсальной машины по обработке информации.
Список источников
https://www.bestreferat.ru/referat-61622.html
https://ru.wikipedia.org/wiki/%D0%A6%D0%B5%D0%BD%D1%82%D1%80%D0%B0%D0%BB%D1%8C%D0%BD%D1%8B%D0%B9_%D0%BF%D1%80%D0%BE%D1%86%D0%B5%D1%81%D1%81%D0%BE%D1%80
https://ru.wikipedia.org/wiki/%D0%A0%D0%B0%D0%B7%D0%B3%D0%BE%D0%BD_%D0%BA%D0%BE%D0%BC%D0%BF%D1%8C%D1%8E%D1%82%D0%B5%D1%80%D0%BE%D0%B2
Алгоритм увеличения вычислительной производительности и баланса загрузки процессоров для моделирования общей циркуляции атмосферы Текст научной статьи по специальности «Математика»
УДК 551.513
Алгоритм увеличения вычислительной производительности и баланса загрузки процессоров для моделирования общей циркуляции атмосферы
© В.П. Пархоменко
Вычислительный центр им. А. А. Дородницына ФИЦ ИУ РАН Москва, 119333, Россия
Представлен анализ некоторых факторов, влияющих на выполнение параллельной реализации модели общей циркуляции атмосферы на многопроцессорной электронно-вычислительной машине кластерного типа. Рассмотрены несколько модификаций первоначального параллельного кода этой модели, направленных на улучшение его вычислительной эффективности, баланса загрузки процессоров. Осуществлена модификация численной схемы по времени модели общей циркуляции атмосферы для возможности осуществления параллельных расчетов блоков динамики и физики. Предлагаемая процедура используется вместе с процедурами распараллеливания блоков динамики и физики на основе декомпозиции расчетной области, что позволяет оптимизировать загрузку процессоров и повысить эффективность распараллеливания. Результаты применения схемы баланса загрузки блока физики рассмотренной модели дают возможность усложнения блока физики без увеличения общего времени счета. Приведены результаты численных экспериментов.
Ключевые слова: модель общей циркуляции атмосферы, особенности параллельной реализации, численные эксперименты.
Введение. Климат [1] является одним из основных природных ресурсов, определяющих последствия для экономики, сельского хозяйства, энергетики, демографии и т. д. Результаты исследований в области климата [2] позволяют предположить, что деятельность человека — важный климатический фактор, и последствия антропогенного воздействия на климатическую систему в ближайшие десятилетия могут быть весьма существенными. Много неопределенностей остается относительно сведений об изменениях климата, особенно в региональном масштабе. Кроме того, крайне неблагоприятные социально-экономические последствия регионального и даже глобального масштаба могут быть вызваны естественными климатическими колебаниями.
Необходима разработка научных основ и системы мер по ограничению негативных последствий экономической деятельности на окружающую среду для сохранения энергии и ресурсов, реструктуризации экономики и адаптации к новым природным и климатическим условиям. Такие основы могут быть разработаны только при совместном изучении глобальных экологических изменений и климата, что позволит осуществить переход к устойчивому развитию [3].
Математическое и численное моделирование является мощным инструментом для исследования климатической системы и прогнозирования изменений климата. Современное моделирование осуществляется с помощью мощных программных средств, в том числе отечественных, для решения задач нестационарной газодинамики многокомпонентного газа различными численными методами [4-7]. Грубые оценки показывают, что для расчетов состояния климатической системы на 100 лет на современной однопроцессорной электронно-вычислительной машине (ЭВМ) необходимо от суток до нескольких месяцев в зависимости от сложности и подробности модели. Следовательно, моделирование климата — одна из задач, требующая для своего решения применения многопроцессорных ЭВМ.
Наиболее сложными и адекватными моделями для описания климатической системы являются модели общей циркуляции атмосферы и океана. В настоящее время разработаны многочисленные модели общей циркуляции атмосферы [2], в которых учтены все существенные процессы в атмосфере. Модели достаточно хорошо описывают циркуляцию атмосферы, температурный режим, осадки, поле давлений, облачность и т. д. Однако слабым местом этих моделей является адекватное воспроизведение взаимодействия атмосферы с подстилающей поверхностью, региональных особенностей климата, а также описания облачности и связанных с ней мелкомасштабных конвективных процессов в атмосфере.
Как известно [8], облачно-радиационная обратная связь является одним из важнейших факторов формирования состояния атмосферы. Характерный масштаб циклонических образований составляет несколько сот километров, атмосферных фронтов — десятки километров, отдельных кучевых облаков — порядка одного километра, а микрофизических процессов в облаках — порядка нескольких метров. Масштаб вертикальных конвективных движений во влажной атмосфере колеблется от нескольких сотен метров до десяти километров.
Таким образом, для адекватного описания только крупномасштабных течений в атмосфере необходимы расчетная сетка с горизонтальным шагом порядка 50 км и несколько десятков уровней по вертикали в тропосфере и стратосфере [9] при условии идеального описания подсеточных процессов.
Увеличение мощности ЭВМ является одним из важнейших требований для более надежных результатов, поэтому в работе рассмотрим методы распараллеливания для решения поставленных задач [10].
Описание модели общей циркуляции атмосферы и процедура распараллеливания., Аф), где X — долгота и ф — широта точки.
Здесь я = рз — рт; У — вектор горизонтальной скорости; а = ёа /
/ — параметр Кориолиса; к — вертикальный единичный вектор; Ф — геопотенциал; Г — вектор горизонтальной силы трения на единицу массы воздуха; а — удельный объем.
Термодинамическое уравнение энергии имеет вид:
— (ясрТ ) + У (ясрТУ) + —(тсрТ а )-яаа дt да
дя ,тГ7 — + УУя
дt
= яН, (3)
где ср — удельная теплоемкость сухого воздуха; Т — температура
воздуха; Н — скорость выделения тепла в единице массы воздуха. Уравнения неразрывности и переноса влаги, соответственно:
—+ У(яУ) + —(та ) = 0, (4)
дt 1 ‘ да1 ; W
д д
— (яд ) + У (тдУ ) + —(яда ) = я((, (5)
дt да
где д — отношение смеси водяного пара; (( — скорость генерации влаги в единице массы воздуха.
Уравнения (2)-(5) являются прогностическими (т. е. эволюционными) для определения зависимых переменных V, Т, т и ц. К ним добавляют уравнение состояния:
где Я — газовая постоянная для влажного воздуха. Диагностическое гидростатическое уравнение:
Уравнения дополняют соответствующие граничные условия; таким образом, получается замкнутая динамическая система в о-координатах.сеткой Аракавы [18] в горизонтальном (широта, долгота) направлении с относительно небольшим числом вертикальных слоев (обычно значительно меньше, чем число горизонтальных точек сетки).
Динамический блок состоит из двух главных компонент: фильтрования и собственно конечно-разностных вычислений. Операция фильтрования необходима на каждом временном шаге в областях, близких к полюсам, чтобы гарантировать, что эффективный размер сетки там удовлетворяет условию устойчивости для явной схемы по времени [18]. Операция основана на разложении потоков в ряд Фурье с обрезанием коротковолновой части спектра и существенно использует все точки географической параллели.
а = ЯТ/р,
(6)
(7)
Эо
В параллельной реализации модели используют разбиение по процессорам двумерной сетки в горизонтальной плоскости (метод декомпозиции). Выбор обусловлен тем, что вертикальные процессы сильно связывают точки сетки, что делает распараллеливание менее эффективным в вертикальном направлении, число точек сетки в вертикальном направлении является обычно небольшим. Каждая подобласть в такой сетке — прямоугольная и содержит все точки сетки в вертикальном направлении. В этом случае есть в основном два типа межпроцессорных обменов [19, 20]. Обмены данными между логически соседними процессорами (узлами) необходимы при вычислениях конечных разностей, а удаленные обмены данными — в частности, для осуществления операции спектрального фильтрования.
Соотношение затрат времени главных блоков исходной параллельной программы модели ОЦА при использовании 4*5*9 градусов разрешения, которое содержит 46*72*9 точек, показано в табл. 1.
Таблица 1
Соотношение затрат времени счета основных блоков модели
Число процессоров Динамический блок, % Физический блок, %
1 63 33
8 67 30
16 70 27
Для счета был использован кластер МВС-60001М (256 CPU) (64-разрядные процессоры Intel® Itanium-2® 1,6 ГГц, при двунаправленном обмене данными между двумя вычислительными машинами с использованием протоколов MPI достигается пропускная способность на уровне 450-500 Мбайт/с). Вычислительные модули связаны между собой высокоскоростной коммуникационной сетью Myrinet (пропускная способность 2 Гбит/с), транспортной сетью Gigabit Ethernet и управляющей сетью Fast Ethernet. Коммуникационная сеть Myrinet предназначена для высокоскоростного обмена между вычислительными модулями в ходе вычислений. Программа была реализована также на сервере Вычислительного центра им. А.А. Дороницына Российской академии наук (ВЦ РАН) с общей памятью (двухпроцессорный, четырехъядерный, на базе Intel Xeon DP 5160, частота 3 ГГц, 4 Гбайт оперативной памяти). Были произведены те же измерения для одного, двух и четырех процессов.
Как следует из табл. 1, основная часть вычислительных затрат модели ОЦА связана с блоками динамики и физики с исключенными процедурами ввода-вывода. Эти процедуры выполняются только один раз, тогда как главная часть повторяется многократно по времени и доминирует по затратам времени выполнения. При сравнении
этих двух блоков можно видеть, что динамическая часть занимает основное время счета, особенно при большом количестве узлов. На масштабируемость параллельной программы влияет отношение затрат обменов данными к затратам вычислений и степень несбалансированности загрузки процессоров в программе. Результаты анализа и оценок затрат времени показывают, что затраты спектральной процедуры составляют заметную часть в параллельной программе модели ОЦА, особенно при увеличении числа узлов [20].
Модификация первоначального параллельного кода модели для улучшения его вычислительной эффективности и баланса загрузки процессоров. Как было отмечено выше, в модели ОЦА можно выделить два главных компонента — динамический и физический блоки. Результаты, полученные в физическом блоке, используют в динамическом блоке как внешние источники для вычисления течения.
Подлежащие интегрированию по времени прогностические уравнения (2)-(5) для основных искомых функций (горизонтальных компонент скорости У, температуры т, отношения смеси водяного пара д, переменной я = р8 — рт, определяющей давление р8) можно записать
в точке (/, у) горизонтальной конечно-разностной сетки в виде:
ду
~д7
= В (у) + 3 (у),
где у — любая из основных искомых функций. — окончательное значение у (после учета влияния источников) в момент времени t + At. Совокупность I и II этапов обеспечивает аппроксимацию рассматриваемых уравнений.
Предлагаемый метод распараллеливания предусматривает одновременный расчет вклада физики и динамики на двух группах процессоров, соответственно. Реализация метода требует изменения численной схемы по времени, которое состоит в одновременном расчете динамики и физики на различных группах процессоров с одних и тех же входных данных:
I группа yD = у0 + AtD (у0 ) ;
II группа у5 = у0 + AtS (у0 ).
По окончании циклов получаем значения основных переменных yD на первой и у s на второй группе процессоров на следующем шаге по времени. После этого процессоры обмениваются данными и на каждой из групп процессоров по формуле у1 = уГ1 + у>5 — у0
рассчитывают окончательные значения искомых функций в момент времени t + At. Легко видеть, что при этом достигается аппроксимация уравнений, но понятно, что результаты исходной и модифицированной схем будут отличаться.
В качестве средства реализации распараллеливания использована библиотека MPI. В настоящее время MPI является наиболее распространенным средством распараллеливания, его реализации есть практически на всех современных многопроцессорных вычислительных машинах, что позволяет обеспечить переносимость программы [21].
Исходная программа была модифицирована в соответствии с высказанными выше соображениями. Для проверки корректности метода по модифицированному и старому вариантам программы были проведены модельные расчеты до установления, имеющие одинаковые начальные условия.
Далее на рисунках приведены некоторые результаты сравнения. На рис. 1 показаны зависимости средней температуры и баланса радиации на верхней границе атмосферы от времени для исходной и модифицированной схем. Указанные средние за сутки и по всему
земному шару величины демонстрируют хорошее совпадение результатов, учитывая сильную изменчивость характеристик атмосферы на коротком интервале в одни сутки.
-10
о -11
я
Он
57 И
-12
-13
-14
100 200 300
Время, дни
а
400
100 200 300 400
Время, дни
б
Рис. 1. Средние глобальные температура атмосферы (а) и баланс радиации на верхней границе атмосферы (б)
в зависимости от времени: 1 — для исходной схемы; 2 — для модифицированной схемы
На рис. 2 показаны графики зависимости от широты зональной компоненты скорости и приземной температуры воздуха, осреднен-ных по долготе для января. Анализ демонстрирует очень хорошее
а б
Рис. 2. Зависимость от широты зональной компоненты скорости (а) и средней приземной температуры воздуха (б) для января:
1 — для исходной схемы; 2 — для модифицированной схемы
совпадение температуры для обоих сезонов, скорости имеют отличия в зимний период в областях сильных градиентов.
Отметим общую особенность распределений основных климатических характеристик, рассчитанных по исходной и модифицированной схемам: наибольшие отличия результатов можно наблюдать в средних и высоких широтах в зимний период. По-видимому, это связано с выпадением осадков в виде снега и интенсивными нестационарными конвективными процессами в атмосфере. Отличия в приземных температурах в более чем 90 % ячеек составляют менее 2 °С. Только в двух ячейках зимой в Северном полушарии над материком разница составляет 10 °С. Для зимы в Южном полушарии наблюдается похожая картина: заметные отличия существуют в трех ячейках в Антарктиде.
Отличия в приземном давлении не превышают 15 мбар в нескольких ячейках и в основном составляют менее 5 мбар.
На рис. 3 показаны географические распределения разности температур воздуха для июля на уровнях 400 и 800 мбар соответственно. На уровне 400 мбар отличия не превышают 2 °С везде за исключением одной точки, где составляют 6 °С. На уровне 800 мбар — подобная картина. Можно утверждать, что отличия в результатах более существенны в приземных областях.
Анализ показывает, что результаты расчетов по модифицированной расчетной схеме дают удовлетворительные результаты и возможно ее применение. В нераспараллеленной программе время счета блока физики составляет 38 %, а блока динамики — 62 %. Значит, на распараллеленной программе может быть достигнуто ускорение
120 150 180
90 70 50 30 10 -10 -30 -50
-2-
5?
СгР
-180 -150 -120 -90 -60 -30
180
Рис. 3. Изолинии разностей температуры воздуха на уровне 400 (а) и 800 мбар (б), рассчитанных по исходной и модифицированной схемам (июль)
приблизительно в полтора раза. Предлагаемую процедуру используют вместе с процедурами распараллеливания блоков динамики и физики на основе декомпозиции расчетной области. Здесь можно применить разработки, описанные в работах [10, 11, 20], что позволяет оптимизировать загрузку процессоров и повысить эффективность распараллеливания (рис. 4).
6 8 Ю 12 14 16 Число процессов
Рис. 4. Зависимость ускорения от числа процессоров:
1 — модифицированный метод; 2 — исходный метод
Другая важная возможность применения метода — усложнение блока физики без увеличения общего времени счета. Рассмотрим четыре численных эксперимента А, В, С и Б с тем, чтобы продемонстрировать результаты:
1) А — использована горизонтальная сетка 4*5 градусов, девять вертикальных уровней, исходный метод для блока физики;
2) В — горизонтальная сетка 4*2,5 градуса для расчета переменных в блоке физики, девять вертикальных уровней;
3) С — горизонтальная сетка 4*2,5 градуса для расчета переменных и 18 вертикальных уровней для радиационных и гидрологических переменных в блоке физики;
4) Б — как в эксперименте С, но в два раза больше спектральных уровней в радиационной модели.
В блоке динамики во всех экспериментах использована фиксированная горизонтальная сетка 4*5 градусов.
В табл. 2 показаны использованные распределения количества процессоров между блоками динамики и физики для указанных вариантов расчетов.
Таблица 2
Распределение процессоров для численных экспериментов А, В, С и Б
Эксперимент А В С Б
Общее количество процессоров 16 22 28 34
Процессоры для блока динамики 10 10 10 10
Процессоры для блока физики 6 12 18 24
Преимущества модифицированного метода, как показано далее, очевидны для экспериментов с относительно большим количеством процессоров, когда большое количество обменов данными между процессорами существует в блоке динамики, а в блоке физики эта проблема отсутствует. Такой эффект объясняет замедление исходного метода расчетов (рис. 5, 2) [20]. Количество процессоров, используемых для блока динамики в модифицированном методе, является одинаковым для всех экспериментов, а увеличивающееся количество
Рис 5. Ускорение счета для численных
экспериментов А, В, С и Б: 1 — модифицированный метод; 2 — исходный метод
процессоров, используемых для блока физики, обеспечивает более подробное и точное описание физических процессов в модели в экспериментах А, В, С и Б. Такое преимущество модифицированного метода не сопровождается увеличением времени счета (рис. 5, 1).
На основе описанной модели климата проведены численные эксперименты по прогнозированию изменения климата при увеличении концентрации углекислого газа в атмосфере, вызванного антропогенными факторами. Для сценария роста концентрации CO2, предложенного в SRES ГРСС [2, 21], рост глобальной температуры атмосферы к 2100 г. составит 2,7 °С, увеличение влажности — 11,5 %, уменьшение толщины морского льда — 25 %. Увеличение приземной температуры атмосферы значительнее над материками и в средних широтах и достигнет 5,2 °С в северных областях Евразии (рис. 6). В Южном полушарии потепление не превысит 2 °С.
А2 С02 всеп еЫв1: Ьиг всЫу = 15 Бскуг = 2100
-260 -220 -180 -140 -100 -60 -20 20 60 100
Долгота
Рис. 6. Изменения температуры воздуха, сценарий А2 С02 (январь)
Существенно изменяется структура меридионального потока воды в Атлантическом океане при реализации рассматриваемого сценария роста концентрации С02. На рис. 7 представлена вертикальная структура среднего меридионального потока в Атлантическом океане для современных условий (а) и прогноз для 2100 г. при реализации сценария роста С02 (б). Наблюдается существенное уменьшение потока максимально на 27 % , что означает уменьшение потока теплых масс воды из экваториальной зоны в северные области Атлантики.
ОРБ! АН Ь А2 С02 всел
Рис. 7. Средний меридиональный поток воды в Атлантическом океане для современных условий (а) и прогноз на 2100 г. (б): ЮП — Южный полюс, Экв — экватор, СП — Северный полюс
Заключение. Рассмотрены результаты применения вариантов параллельного алгоритма климатической модели для различных способов разбиения расчетной области с модифицированными коммуникационными процедурами для обменов информацией между процессорами в параллельном варианте модели общей циркуляции атмосферы. Реализована параллельная программа для различных способов разбиения расчетной области по процессорам в климатической модели.
Представлен анализ некоторых факторов, влияющих на выполнение параллельной реализации модели ОЦА на многопроцессорной ЭВМ кластерного типа. Рассмотрено несколько модификаций первоначального параллельного кода модели, направленных на улучшение его вычислительной эффективности, баланса загрузки процессоров.
Предложен модифицированный метод распараллеливания с одновременным расчетом вклада физики и динамики соответственно на двух группах процессоров с одних и тех же входных данных. Отмечено, что реализация метода требует изменения численной схемы по времени. По модифицированному и исходному вариантам программы проведены модельные расчеты, подтвердившие корректность этого метода. Исследована эффективность модифицированной схемы, при этом повышение точности расчета вклада физики не сопровож-
дается увеличением времени счета. Представлены результаты по моделированию прогнозов изменения климата при увеличении концентрации углекислого газа в атмосфере.
Работа выполнена при поддержке Проектов РФФИ № 14-01-00308, № 14-07-00037, № 16-01-0466.
ЛИТЕРАТУРА
[1] Монин А.С. Введение в теорию климата. Ленинград, Гидрометеоиздат, 1982, 296 с.
[2] Climate Change 2013. The Physical Science Basis. The Physical Science Basis. New York, Cambridge University Press, 2013. Available at: http://www.climatechange2013.org/images/report/WG1 AR5_ALL_FINAL.pdf
[3] Моисеев Н.Н., Александров В.В., Тарко А.М. Человек и биосфера. Москва, Наука, 1985, 272 с.
[4] Dimitrienko Yu.I., Koryakov M.N., Zakharov A.A. Computational Modeling of Conjugated Aerodynamic and Thermomechanical Processes in Composite Structures of High-speed Aircraft. Applied Mathematical Sciences, 2015, vol. 9, no. 98, pp. 4873-4880. http://dx.doi.org/10.12988/ams.2015.55405
[5] Димитриенко Ю.И., Коряков М.Н., Захаров А.А. Применение метода RKDG для численного решения трехмерных уравнений газовой динамики на неструктурированных сетках. Математическое моделирование и численные методы, 2015, № 4, с. 75-91.
[6] Dimitrienko Yu.I., Koryakov M.N., Zakharov A.A. Application of Finite Difference TVD Methods in Hypersonic Aerodynamics. Finite Difference Methods, Theory and Applications. Lecture Notes in Computer Science, 2015, vol. 9045, pp. 161-168. DOI 10.1007/978-3-319-20239-6_15
[7] Димитриенко Ю.И., Захаров А.А., Коряков М.Н., Сыздыков Е.К. Моделирование сопряженных процессов аэрогазодинамики и теплообмена на поверхности теплозащиты перспективных гиперзвуковых летательных аппаратов. Известия высших учебных заведений. Машиностроение, 2014, № 3, с. 23-34.
[8] National Aeronautics and Space Administration: Earth Systems Science: A Closer View. Report of the Earth Systems Science Committee NASA Advisor Council NASA. Washington, NASA, 1988, 208 p.
[9] Белов П.Н., Борисенков Е.П., Панин Б.Д. Численные методы прогноза погоды. Ленинград, Гидрометеоиздат, 1989, 375 с.
[10] Parkhomenko V.P., Lang T.V. Improved computing performance and load balancing of atmospheric general circulation model. Journal of Computer Science and Cybernetics, 2013, vol. 29, no. 2, pp. 138-148.
[11] Пархоменко В.П. Реализация глобальной климатической модели на многопроцессорной ЭВМ кластерного типа. Параллельные вычислительные технологии. Труды Международной научной конференции «Параллельные вычислительные технологии 2009» (Нижний Новгород, 30 марта — 3 апреля 2009 г.). Челябинск, изд-во ЮУрГУ, 2009, 839 с.
[12] Пархоменко В.П. Модель климата с учетом глубинной циркуляции Мирового океана. Вестник МГТУ им. Н.Э. Баумана. Сер. Естественные науки, 2011, спец. вып. «Математическое моделирование», с. 186-200.
[13] Пархоменко В.П. Глобальная модель климата с описанием термохалин-ной циркуляции Мирового океана. Математическое моделирование и численные методы, 2015, № 1, 94-108.
[14] Пархоменко В.П. Моделирование стабилизации глобального климата управляемыми выбросами стратосферного аэрозоля. Математическое моделирование и численные методы, 2014, № 2, c. 115-126.
[15] Пархоменко В.П. Численные эксперименты на глобальной гидродинамической модели по оценке чувствительности и устойчивости климата. Инженерный журнал: наука и инновации, 2012, № 2.
DOI 10.18698/2308-6033-2012-2-45
[16] Пархоменко В.П. Квазислучайный подход для определения оптимальных наборов значений параметров климатической модели. Инженерный журнал: наука и инновации, 2013, № 9. DOI 10.18698/2308-6033-2013-9-962
[17] Parkhomenko V.P. Sea Ice Cover Sensitivity Analysis in Global Climate Model. Research Activities in Atmospheric and Oceanic Modelling. Geneva, World Meteorological Organization, 2003, vol. 33, pp. 7.19-7.20.
[18] Arakawa A., Lamb V. Computational Design of the Basic Dynamical Processes of the UCLA General Circulation Model. Methods in Computational Physics, 1977, vol. 17, pp. 174-207.
[19] Пархоменко В.П. Проблемы реализации и функционирования глобальной климатической модели на параллельных вычислительных системах. Труды IV Международной конференции «Параллельные вычисления и задачи управления» (Москва, 27-29 окт. 2008 г.). Москва, Институт проблем управления им. В.А. Трапезникова РАН, 2008, с. 122-141.
[20] Воеводин В.В., Воеводин Вл.В. Параллельные вычисления. Санкт-Петербург, БХВ-Петербург, 2002, 608 с.
[21] Climate Change 2007: The physical Science Basis. Contribution of Working Group I to the Fourth Assessment Report of the Intergovernmental Panel Climate Change, Paris, 2007, 989 p.
Статья поступила в редакцию 09.09.2016
Ссылку на эту статью просим оформлять следующим образом:
Пархоменко В.П. Алгоритм увеличения вычислительной производительности и баланса загрузки процессоров для моделирования общей циркуляции атмосферы. Математическое моделирование и численные методы, 2016, № 3 (11), с. 93-109.
Пархоменко Валерий Павлович окончил физический факультет МГУ им. М.В. Ломоносова. Канд. физ.-мат. наук, заведующий сектором моделирования климатических и биосферных процессов Вычислительного центра им. А.А. Дородницына РАН Федерального исследовательского центра «Информатика и управление» РАН, доцент МГТУ им. Н.Э. Баумана. Автор более 120 научных публикаций. Область научных интересов: нестационарная газовая динамика, численные методы динамики сплошных сред, математическое моделирование климата. e-mail: [email protected]
Algorithm for computational performance improvement and processor load balancing to simulate the general atmosphere circulation
© V.P. Parkhomenko
Dorodnicyn Computing Centre of RAS, Moscow, 119333, Russia
The paper analyzes some factors affecting the parallel implementation performance of the atmospheric general circulation model designed on a cluster type multiprocessor computer. It considers several modifications of the initial parallel code of this model in order to improve both its computational efficiency and processor load balancing. The
numerical scheme is modified according to the time of the atmospheric general circulation model for parallel computing of dynamics and physics blocks. The proposed procedure is used along with the procedures of paralleling the dynamics and physics blocks based on decomposition of the computational domain. It allows both optimizing the processor load balancing and increasing the paralleling efficiency. The data obtained while using the scheme for the physics block load balancing allow for complication of the physics block without increasing the total computational time. The results of numerical experiments are given.
Keywords: atmospheric general circulation model, parallel implementation features, numerical experiments.
REFERENCES
[1] Monin A.S. Vvedenie v teoriyu klimata [Introduction to the theory of climate]. Leningrad, Gidrometeoizdat Publ., 1982, 296 p.
[2] Climate Change 2013. The Physical Science Basis. The Physical Science Basis. New York, Cambridge University Press, 2013. Available at: http://www.climatechange2013.org/images/report/WG1AR5_ALL_FINAL.pdf
[3] Moiseev N.N., Aleksandrov V.V., Tarko A.M. Chelovek i biosfera [Man and the biosphere]. Moscow, Nauka Publ., 1985, 272 p.
[4] Dimitrienko Yu.I., Koryakov M.N., Zakharov A.A. Applied Mathematical Sciences,, 2015, vol. 9, no. 98, pp. 4873-4880. http://dx.doi.org/10.12988/ams.2015.55405
[5] Dimitrienko Yu.I., Koryakov M.N., Zakharov A.A. Matematicheskoe mo-delirovanie i chislennye metody — Mathematical Modelling and Computational Methods, 2015, no. 4, pp. 75-91.
[6] Dimitrienko Yu.I., Koryakov M.N., Zakharov A.A. Finite Difference Methods, Theory and Applications. Lecture Notes in Computer Science, 2015, vol. 9045, pp. 161-168. DOI 10.1007/978-3-319-20239-6_15
[7] Dimitrienko Yu.I., Zakharov A.A., Koryakov M.N., Syzdykov E.K. Izvestiya vysshikh uchebnykh zavedeniy. Mashinostroenie — Proceedings of Higher Educational Institutions. Machine Building, 2014, no. 3, pp. 23-34.
[8] National Aeronautics and Space Administration: Earth Systems Science: A Closer View. Report of the Earth Systems Science Committee NASA Advisor Council NASA, Washington, NASA, 1988, 208 p.
[9] Belov P.N., Borisenkov E.P., Panin B.D. Chislennye metody prognoza pogody [Numerical methods of weather forecast]. Leningrad, Gidrometeoizdat Publ., 1989, 375 p.
[10] Parkhomenko V.P., Lang T.V. Journal of Computer Science and Cybernetics, 2013, vol. 29, no. 2, pp. 138-148.
[11] Parkhomenko V.P. Realizatsiya globalnoi klimaticheskoi modeli na mnogopro-cessornoi EVM klasternogo tipa. Parallelnye vychislitelnye tehnologii [The implementation of a global climate model on a cluster type multiprocessor computer. Parallel computing technologies]. Trudy Mezhdunarodnoy nauchnoy konferentsii «Parallelnye vychislitelnye tekhnologii 2009» [Proceedings of the International scientific conference «Parallel computational technologies», 2009] (Nizhny Novgorod, 30 March — 3 April 2009). Chelyabinsk, Publishing House of the SUSU, 2009, 839 p.
[12] Parkhomenko V.P. Vestnik MGTU im. N.E. Baumana. Ser. Estestvennye nauki — Herald of the Bauman Moscow State Technical University. Series Natural Sciences, 2011, spec. iss. «Mathematical modeling», pp. 186-200.
[13] Parkhomenko V.P. Matematicheskoe modelirovanie i chislennye metody — Mathematical Modelling and Computational Methods, 2015, no. 1, pp. 94-108.
[14] Parkhomenko V.P. Matematicheskoe modelirovanie i chislennye metody — Mathematical Modelling and Computational Methods, 2014, no. 2, pp. 115-126.
[15] Parkhomenko V.P. Inzhenernyy zhurnal: nauka i innovatsii — Engineering Journal: Science and Innovation, 2012, no. 2.
DOI 10.18698/2308-6033-2012-2-45
[16] Parkhomenko V.P. Inzhenernyy zhurnal: nauka i innovatsii — Engineering Journal: Science and Innovation, 2013, no. 9.
DOI 10.18698/2308-6033-2013-9-962
[17] Parkhomenko V.P. Sea Ice Cover Sensitivity Analysis in Global Climate Model. Research Activities in Atmospheric and Oceanic Modelling. Geneva, World Meteorological Organization, 2003, vol. 33, pp. 7.19-7.20.
[18] Arakawa A., Lamb V. Methods in Computational Physics, 1977, vol. 17, pp. 174-207.
[19] Parkhomenko V.P. Problemy realizatsii i funktsionirovaniya globalnoi klimati-cheskoi modeli na parallelnykh vychislitelnykh sistemakh [Problems of implementation and functioning of the global climate models on parallel computer systems]. Trudy IV Mezhdunarodnoi konferentsii «Parallelnye vychisleniya i zadachi upravleniya» (Moscow, 27-29 Oct., 2008) [Proceedings of the IV International conference Parallel computations and control problems (Moscow, 27-29 Oct., 2008)]. Moscow, V.A. Trapeznikov Institute of Control Sciences, Russian Academy of Sciences, 2008, pp. 122-141.
[20] Voevodin V.V., Voevodin Vl.V. Parallelnye vychisleniya [Parallel computations]. St. Petersburg, BHV-Petersburg Publ., 2002, 608 p.
[21] Climate Change 2007: The physical Science Basis. Contribution of Working Group I to the Fourth Assessment Report of the Intergovernmental Panel Climate Change, Paris, 2007, 989 p.
Parkhomenko V.P. graduated from Lomonosov Moscow State University, Department of Physics. Cand. Sci. (Phys.-Math.), Head of Division for Modelling of Climatic and Biosphere Processes in Institution of Russian Academy of Sciences, Dorodnicyn Computing Centre of RAS, Assoc. Professor at Bauman Moscow State Technical University. Author of over 120 research publications. Research interests: nonstationary gas dynamics, numerical methods for continuous media dynamics, mathematical modeling of climate. e-mail: [email protected]
Описание моделируемой системы. Моделирование работы специализированного вычислительного устройства
Похожие главы из других работ:
Имитационное моделирование системы массового обслуживания
1.1 Описание моделируемой системы
На склад готовой продукции каждые 5±2 мин поступают изделия А партиями по 500 штук, а каждые 20±5 мин — изделия В партиями по 200 штук. С интервалом 10±5 мин к складу подъезжают машины, в каждую из которых нужно погрузить по 100 штук изделий А и В…
Компьютерное моделирование конвейера по изготовлению шестерен
1. Описание моделируемой системы
…
Моделирование процессов обработки информации
1.1 Описание моделируемой системы
Самолеты прибывают для посадки в район аэропорта каждые 10±5 мин. Если полоса свободна, прибывший самолет получает разрешение на посадку, если занята — самолет выполняет полет по кругу и возвращается к аэропорту через каждые 4 мин…
Моделирование процессов обработки информации
1.1 Описание моделируемой системы
Поставленная в этой курсовой работе задача относится к классу задач теории систем массового обслуживания (СМО). При решении этой задачи используется непрерывно-стохастическая модель (вычислительный центр), включающую одну ЭВМ…
Моделирование процессов обработки информации
1.1 Описание моделируемой системы
Задача, решаемая в данной курсовой работе, относится к задачам теории систем массового обслуживания (СМО). Пакеты данных на обработку поступают с двух направлений. Пакеты данных с первого направления поступают во входной буфер…
Моделирование работы библиографической системы
1.1 Описание моделируемой системы
Информационно-поисковая библиографическая система построена на базе двух ЭВМ и имеет один терминал для ввода и вывода информации. Первая ЭВМ обеспечивает поиск литературы по научно-техническим вопросам (вероятность обращения к ней — 0,7)…
Моделирование работы дома быта
1.1 Описание моделируемой системы
Задача, решаемая в данной курсовой работе, относится к задачам теории систем массового обслуживания (СМО). Это объясняется тем, что используется непрерывно-стохастическая модель, элементом которой является рабочие места (дом быта)…
Моделирование работы машинного зала
1. Описание моделируемой системы
Задача на моделирование поставлена следующим образом: в машинный зал с интервалом времени 10±5 мин заходят пользователи, желающие произвести расчеты на ЭВМ. В зале имеется одна ЭВМ, работающая в однопрограммном режиме. Время…
Моделирование работы переговорного пункта
1.1 Описание моделируемой системы
Переговорный пункт имеет один телефонный аппарат. Переговоры бывают обычные и срочные. При поступлении заявки на срочные переговоры обычный разговор прерывается. В среднем за сутки поступает 180 заявок на обычные и 60 срочные переговоры…
Моделирование работы специализированного вычислительного устройства
Описание моделируемой системы
Специализированное вычислительное устройство, работающее в режиме реального времени, имеет в своем составе два процессора, соединенные с общей оперативной памятью. В режиме нормальной эксплуатации задания выполняются на первом процессоре…
Моделирование работы СТО
1.1 Описание моделируемой системы
Станция технического обслуживания состоит из четырех однотипных участков. Через каждые 8 минут на станцию приезжает машина, занимает свободный участок и обслуживается в течение 30 минут. Если машина застает все участки занятыми…
Моделирование работы транспортного цеха
1.1 Описание моделируемой системы
Задача, решаемая в данной работе, относится к задачам теории систем массового обслуживания (СМО). Это объясняется тем, что используется непрерывно-стохастическая модель, элементом которой является прибор (Диспетчер)…
Моделирование работы цеха сборки
1.1 Описание моделируемой системы
Дадим точную формулировку задачи. Имеется цех и ОТК. В цехе на нескольких линиях происходит сборка изделий. Будем считать, что поступающие детали формируют заявку на сборку. Следовательно…
Моделирование работы цеха, в котором осуществляется сборка изделий и их регулировка
1. Описание моделируемой системы
…
Моделирование работы цеха, в котором осуществляется сборка изделий и их регулировка
1.1 Описание моделируемой системы
На сборочный участок цеха через интервалы времени, распределенные экспоненциально со средним значением 10 минут, поступают партии деталей. Процесс сборки детали занимает 6 минут. Затем изделие поступает на участок регулировки…
Домашняя страница предложения по моделированию ЦП
0. ОБЛОЖКА
Проект
Название: CPU Simulation
Имя: Дарио Винсент
Эл. Почта: [email protected]
Дата: 11 февраля 2003 г.,
Председатель комитета:
Подпись председателя комитета:
Список задач
1. ЦЕЛЬ
Симулятор ЦП может быть отличным академическим инструментом, помогающим преодолеть
разрыв между дискретными компонентами и архитектурными абстракциями в компьютере
организационный курс.Этот исследовательский проект предлагает создать программное обеспечение
моделирование относительно простого процессора. Этот виртуальный ЦП обеспечит
иллюстрация декодирования данных и управления из машинной инструкции
вплоть до цифровых ворот, которые обрабатывают информацию в разных частях
микросхемы ЦП.
Примечания
2. ВВЕДЕНИЕ
Моделирование заключается в создании представления или модели.
физической системы или конкретной ситуации.Можно использовать симулятор
воспроизвести процессор в программном обеспечении. Это также может позволить нам наблюдать
состояния различных частей внутри процессора таким образом, чтобы мы не могли
сделали это с реальным оборудованием. В этом проекте будет создан симулятор ЦП.
который будет фиксировать поток данных и управляющую информацию внутри ЦП.
Это обеспечит «мгновенное воспроизведение» внутри ЦП. Он будет отслеживать
сигналы через различные модули ЦП и иллюстрируют, как
инструкция выполнена.
Было реализовано множество симуляторов ЦП. А
большое количество этих тренажеров предназначено для образовательных целей. SimOS — это
полная среда моделирования, предназначенная для изучения одного и нескольких
процессорные системы [2]. Он имитирует
физическая система настолько детализирована, что с нее можно загрузить коммерческую операционную систему.
Некоторые тренажеры настроены на производительность и используют специальные методы, такие как
двоичный перевод Embra [5] для ускорения
до выполнения кода.Другие, такие как MXS [2]
заботятся о предоставлении точного представления об оборудовании.
Коммерческий симулятор тоже используется давно. Техника
моделирования ЦП помог производителям оборудования перенести системы из
от одной архитектуры к другой с сохранением устаревшего программного обеспечения. IBM имеет
многолетний опыт использования моделирования для сохранения обратной совместимости
линейка мэйнфреймов [4]. Apple также использовала
этот метод при переходе с CISC на RISC-семейство CPU [4].
Архитектура компьютера может быть представлена как серия слоев [6]. Некоторые уровни реализуются физическими
оборудование и прочее — программное обеспечение. Моделирование также сыграло свою роль в
уровни виртуальных машин. Microsoft использовала моделирование, чтобы сохранить совместимость
между различными операционными системами Windows [4]. Виртуальная машина Java на компьютере Sun
еще один пример архитектуры, которая может существовать только в моделировании ЦП *
[6].
Этот симулятор не будет моделировать физическую систему, вместо этого он будет
воплотить в жизнь простой процессор, предназначенный для этой образовательной цели.
Имитация ЦП — это использование программной виртуальной машины.
вместо фактического оборудования. Может применяться как к существующим, так и к
гипотетические машины. В качестве педагогического инструмента [1] он иллюстрирует простые архитектуры.
которые можно изучить в рамках времени и ограниченных ресурсов
университетского курса.В отрасли это становится мощным инструментом для
эмулировать одну машину в среде другой.
Было реализовано множество симуляторов ЦП.
Коммерческие продукты очень сложны и могут имитировать существующие процессоры.
Apple Computers использовала симулятор процессора при переходе с 68K
семейство процессоров для новой архитектуры PowerPC. Виртуальный
ПК позволяет запускать программу, разработанную для микропроцессора Intel, на
PowerPC.Виртуальная машина Java Sun реализована на популярных сегодня процессорах.
и позволяет программе Java работать на нескольких процессорах. Недавно появилась новая порода
процессоров Transmeta Crusoe [7],
реализован в аппаратном и программном обеспечении вместе. Эти процессоры
может быть запрограммирован на эмуляцию архитектуры Intel или других архитектур
с их технологией Code Morphing [8].
Также доступны более простые симуляторы ЦП для образовательных целей.CPU Sim [2] обеспечивает среду для
спроектировать ЦП на уровне передачи регистров. Это позволяет модификации и
сравнение между разными архитектурами. Очень простой симулятор ЦП [3] имеет фиксированную архитектуру и иллюстрирует
графически, как различные компоненты ЦП работают во время выполнения инструкции
цикл.
В этом проекте будет использоваться очень простой дизайн, но он будет сосредоточен на
о потоке данных и управляющей информации внутри ЦП.Выполнение
цикл машинного кода будет представлен графически. Начиная с
декодирование битов в коде операции и следование путям данных
память и регистры. Симулятор покажет данные и инструкции
путешествие внутри процессора.
При необходимости исследователь должен включить модель, которую можно применить.
своему проекту, чтобы продемонстрировать его обоснованность и полезность. Это делает
не требует сбора данных, а просто использует случай, чтобы продемонстрировать, как
это могло быть использовано.
Примечания
3. ТЕХНИЧЕСКИЙ ПОДХОД
Банкноты
4. ГРАФИК
5. КРИТЕРИИ УСПЕХА
6. ССЫЛКИ
Симулятор компьютерной системы CPUlator
Симулятор компьютерной системы CPUlatorСимулятор компьютерной системы CPUlator
CPUlator — это симулятор компьютерной системы (процессора и устройств ввода-вывода) и отладчик Nios II, ARMv7 и MIPS, работающий в современном веб-браузере.Он разработан как инструмент для обучения программирование на ассемблере и компьютерная организация.
Чтобы начать использовать CPUlator сейчас, выберите компьютерную систему для моделирования, затем перейдите по ссылке.
Чтобы узнать больше, попробуйте образец программы в симуляторе (Справка → Примеры программ) или просмотрите документацию.
Выберите систему для моделирования
Характеристики
- Наборы инструкций : Nios II, ARMv7 и MIPS
- Устройства ввода-вывода :
- Nios II и ARMv7: Включает большинство устройств на DE1-SoC (и других моделях плат, используемых программой Altera University), включая поддержку прерываний.
- MIPS: включает терминал, совместимый с SPIM
- Нечего устанавливать : Работает полностью в веб-браузере
- Отладчик : пошаговое выполнение, точки останова, точки наблюдения, трассировка, стек вызовов, проверка разборки, памяти и регистров
- Отладочные утверждения : Дополнительные утверждения времени выполнения выявляют множество потенциальных ошибок
- Вход : принимает как исходный код сборки, так и исполняемые файлы ELF
- См. Дополнительную документацию…
- Демо (изображение программы Nios II на дисплее VGA)
Nios II, ARMv7,
и MIPS Simulator?Оказывается, написать симулятор ЦП (или четыре) относительно легко. Сложная часть — это создание полнофункциональный отладчик с удобным и эффективным пользовательским интерфейсом. Таким образом, CPUlator поддерживает несколько наборов инструкций, повторно используя ту же инфраструктуру отладки и пользовательского интерфейса.
Симулятор был впервые написан для Nios II в январе 2016 года для использования в Университете Торонто.Поддержка ARMv7 была добавлена осенью 2016 г., а MIPS32r6 — в январе 2018 г. Версия 5 MIPS32 была добавлена в ноябре 2018 г. потому что оказывается, что выпуск 6 несовместим со всеми более ранними наборами инструкций MIPS, а с r6 пока никто не учит.
Сравнительная таблица
Ниже приводится сравнение функций CPUlator с некоторыми популярными симуляторами, используемыми для обучения.
| CPUlator | MARS 4.5 | QtSPIM 9.1.20 | ARMSim # 1.91 | ARMSim # 2.1 | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Установка не требуется | |||||||||||||||||||||||
| Платформа | Веб-браузер | Java JRE | Windows, OSX, Linux .NET | 3.016 | |||||||||||||||||||
| Бесплатно | |||||||||||||||||||||||
| Открытый исходный код | |||||||||||||||||||||||
| Редактор | |||||||||||||||||||||||
| Ассемблер | GNU | custom | custom | custom | GNU | ||||||||||||||||||
| C или другие языки | 9015 | ||||||||||||||||||||||
| Точки останова | |||||||||||||||||||||||
| Одношаговый | |||||||||||||||||||||||
| Обратный шаг | |||||||||||||||||||||||
| Функция шага | 9015 | 9015 | Изменить регистры | (кроме ПК) | |||||||||||||||||||
| Изменить память | |||||||||||||||||||||||
| Показать стек вызовов | |||||||||||||||||||||||
| Точки наблюдения за данными | |||||||||||||||||||||||
| Наборы команд | MIPS32 r5 MIPS32 r6 ARMv7 Nios II | MIPS32 | MIPS2 | ARM | может быть | может быть | |||||||||||||||||
| MMU | |||||||||||||||||||||||
| FPU | 1 сегмент | ||||||||||||||||||||||
| Максимально полезная память | 2042 МБ | 4 + 4 + 4 МБ данных 4 + 4 МБ код | 4 + 1 + 0.5 МБ данных 256 + 64 КБ код | 64 КБ данных 512 МБ код | 96 КБ данных 512 МБ код | ||||||||||||||||||
| Устройства ввода / вывода | |||||||||||||||||||||||
| Терминал | |||||||||||||||||||||||
| Файловый ввод / вывод | |||||||||||||||||||||||
| Другие устройства | |||||||||||||||||||||||
| Скорость моделирования ( Минст / секунда 3 ) 903 | 2 | 3 |
— MATLAB и Simulink
Моделирование SIL и PIL
Обзор программного обеспечения в контуре (SIL) и процессора в контуре моделирования (PIL).
Выберите подход SIL или PIL
Тестовый код, созданный на основе топовых моделей, ссылочных моделей или подсистем.
Создание целевой конфигурации подключения PIL для Simulink
Настройте моделирование PIL для вашей целевой среды.
Связь между хостом и целью для моделирования PIL в Simulink
Используйте rtiostream API для связи между вашими
компьютер разработки и целевое оборудование во время моделирования PIL.
Указать аппаратный таймер
Укажите аппаратный таймер с помощью средства замены кода.
Настройка подключения PIL с помощью целевого пакета
Обеспечивает связь PIL между Simulink ® и целевым оборудованием.
Директивы Custom Toolchain, необходимые для покрытия кода и профилирования выполнения
Укажите директивы компилятора для создания приложения PIL, поддерживающего код анализ покрытия и профилирование исполнения.
Настройка и запуск моделирования PIL
Настройка и запуск топ-модели PIL, модельного блока PIL и PIL-блока симуляции.
Рабочий процесс проверки SIL / PIL Manager
Упрощенный рабочий процесс для проверки сгенерированного кода.
Последовательность моделирования PIL
Как происходит симуляция PIL.
Поведение отмены режима моделирования в иерархии ссылок на модель
Как режим моделирования верхней модели или родительской модели определяет моделирование поведения модели иерархии.
Полевое управление синхронной машиной с постоянными магнитами
Моделируйте систему управления двигателем, сгенерируйте код контроллера и используйте PIL моделирование для проверки числовой эквивалентности и выполнения кода профиля раз.
Безопасность для моделирования PIL
Меры безопасности для моделирования PIL.
Ограничения SIL и PIL
Функции моделирования и генерации кода, которые не поддерживаются или поддерживаются частично поддерживается симуляциями SIL и PIL.
Область рабочей нагрузки (минимальная конфигурация с 4 узлами) | ||
Платформа | Двухпроцессорная серверная платформа | Двухпроцессорная серверная платформа |
Процессор | 2 процессора Intel® Xeon® Gold 6126 (2.60 ГГц, 12 ядер / 24 потока), процессор Intel® Xeon® Gold 6226 (2,7 ГГц, 12 ядер / 24 потока), процессор Intel® Xeon® Gold 6226R (2,90 ГГц / 16 ядер / 32 потока) или более мощная модель номер Процессор Intel® Xeon® Scalable | 2 процессора Intel® Xeon® Gold 6148 (2,40 ГГц, 20 ядер / 40 потоков), процессор Intel® Xeon® Gold 6252 (2,5 ГГц, 12 ядер / 24 потока), процессор Intel® Xeon® Gold 6248R (3,00 ГГц , 24 ядра, 48 потоков) или более высокий номер модели Intel Xeon Масштабируемый процессор |
Память | 96 ГБ (12 × 8 ГБ, 2666 МГц, 288-контактный модуль DDR4 RDIMM) 2 ГБ памяти на каждое ядро процессора и заполнены все каналы памяти | 96 ГБ (12 × 8 ГБ, 2666 МГц, 288-контактный модуль DDR4 RDIMM) 2 ГБ памяти на каждое ядро процессора и заполнены все каналы памяти |
Локальное хранилище | 1 × Intel® SSD DC серии S3520 или лучше, или Intel SSD DC серии P3520 или лучше ** | 1 × Intel SSD DC серии S3520 или лучше, или Intel SSD DC серии P3520 или лучше ** |
Messaging Fabric | 1 × Архитектура Intel® Omni-Path (Intel® OPA), однопортовый интерфейс Peripheral Component Interconnect Express (PCIe) 3.0 x16, 100 гигабит в секунду (Гбит / с) | 1 × Intel® OPA, однопортовый адаптер PCIe 3.0 x16, 100 Гбит / с |
Домен управления | ||
Сеть управления | Встроенный 1 гигабитный Ethernet (GbE) ** | Интегрированный 1 GbE ** |
Программное обеспечение | Операционная система Linux * Intel® Cluster Checker 2019 Программный стек для управления кластером ** Программное обеспечение Intel® Omni-Path Fabric (Intel® OP Fabric) Intel® Parallel Studio XE 2018 Cluster Edition ** | Операционная система Linux Intel Cluster Checker 2019 Программный стек для управления кластером ** Программное обеспечение Intel Omni-Path Fabric (Intel OP Fabric) Intel Parallel Studio XE 2018 Cluster Edition ** |
Оптимизация прошивки и программного обеспечения | Технология Intel® Hyper-Threading (Intel® HT) включена Технология Intel® Turbo Boost включена Предварительная выборка XPT включена | Технология Intel HT включена Технология Intel Turbo Boost включена Предварительная выборка XPT включена |
Минимальные стандарты производительности Проверено на соответствие или превышение следующих минимальных возможностей производительности: 1 | ||
Высокопроизводительный пакет Linpack (HPL) (для всех четырех узлов) | Более 5200 гигафлопс в секунду (GFLOP / s) | Более 7,700 GFLOP / s |
Высокопроизводительный сопряженный градиент (HPCG) (на всех четырех узлах) | Более 118 GFLOP / s | Более 127 GFLOP / s |
HPCG (на каждом узле) | Более 30.1 ГФЛОП / с | Более 32 GFLOP / s |
DGEMM (на каждом узле) | Более 1300 GFLOP / s | Более 2480 GFLOP / s |
ПОТОК (на каждом узле) | Более 150 000 МБ в секунду (МБ / с) | Более 164000 МБ / с |
IMB PingPong (на каждой паре узлов) | Более 11300 МБ / с (пропускная способность) Менее 1.80 микросекунд (задержка) | Более 11300 МБ / с (пропускная способность) Менее 1,80 микросекунд (задержка) |
Бизнес-ценность выбора конфигурации Plus по сравнению с базовой конфигурацией | По данным теста HPL, до 54% выше GFLOP / s, чем в базовой конфигурации. 1 | |
| ** Рекомендуется, не требуется | ||
Границы | NeuroFlow: универсальная платформа для моделирования нейронной сети с использованием настраиваемых процессоров
Введение
Обратный инжиниринг мозга — одна из величайших инженерных задач этого века. Различные проекты работают над рядом аспектов этой проблемы, включая характеристику типов нейронов и их генетическую транскрипцию (Hawrylycz et al., 2012), разработка генетических инструментов для нацеливания отдельных типов клеток на зондирование или возмущение (Madisen et al., 2010; Kohara et al., 2013), восстановление нейронных связей («коннектом»; Livet et al., 2007; Oh et al. al., 2014), разработка инструментов и вычислительной инфраструктуры для крупномасштабного нейронного моделирования (Markram, 2006; Plana et al., 2007; Ananthanarayanan et al., 2009; Markram et al., 2011). С развитием нейронных симуляторов нейронное моделирование способствует развитию исследований в области компьютерных наук, включая области искусственного интеллекта, компьютерного зрения, робототехники и интеллектуального анализа данных.Вычислительные возможности мозговых вычислений активно исследуются в нескольких проектах (Eliasmith et al., 2012; Furber et al., 2014), и разрабатываются новые алгоритмы, основанные на принципе нейронных вычислений (Gütig and Sompolinsky, 2006; Sussillo, Abbott, 2009; Schmidhuber, 2014). В последнее время растет интерес к построению крупномасштабных моделей с использованием нейронных сетей (SNN), которые могут обеспечить более высокую биологическую точность и более полную функциональность, чем модели меньшего масштаба (Ижикевич и Эдельман, 2008; Eliasmith et al., 2012; Reimann et al., 2013). В результате появился ряд вычислительных платформ, нацеленных на SNN, такие как SpiNNaker (Furber et al., 2013; Sharp et al., 2014), FACETS (Schemmel et al., 2010), Neurogrid (Silver et al., 2007), и TrueNorth (Merolla et al., 2014) были разработаны, чтобы сделать крупномасштабное сетевое моделирование более быстрым, более энергоэффективным и доступным. Платформы нейронного моделирования обычно используют такие процессоры, как многоядерные процессоры, микросхемы специализированных интегральных схем (ASIC) или графические процессоры (GPU), и предлагают различные степени программируемости, от программируемых параметров до полного управления уровнем команд.Хотя ASIC имеют высокую производительность и низкое энергопотребление, их архитектура фиксируется во время изготовления, и поэтому им не хватает гибкости для принятия новых конструкций или модификаций в соответствии с потребностями пользователя, такими как точность параметров, тип арифметических представлений и нейронные или синаптические модели использоваться. С другой стороны, графические процессоры обеспечивают некоторое ускорение по сравнению с многоядерными процессорами, обладают хорошей программируемостью и гибкостью, но, как правило, имеют большое энергопотребление.
ПЛИСранее использовались в качестве ускорителя для нейронного моделирования, как для моделей, основанных на проводимости (Graas et al., 2004; Blair et al., 2013; Smaragdos et al., 2014) и точечных нейронов (Cassidy et al., 2007; Cheung et al., 2009; Rice et al., 2009; Thomas, Luk, 2009; Moore et al., 2012; Cong et al., ., 2013; Wang et al., 2013). Высокая настраиваемость, масштабируемость и детальный параллелизм делают FPGA хорошим кандидатом для разработки платформы нейронного моделирования. Однако до сих пор в ускорителях на основе ПЛИС отсутствуют средства автоматизации проектирования, и они поддерживают только ограниченный набор моделей, поэтому получаемые в результате платформы часто имеют относительно низкую гибкость.Чтобы предоставить нейробиологам гибкую нейроморфную аппаратную платформу для моделирования крупномасштабных биологических моделей с использованием пиков нейронов, мы разрабатываем NeuroFlow, реконфигурируемый имитатор нейронной сети с пиками на основе ПЛИС с высокоуровневым API (интерфейс прикладного программирования), подходящим для пользователей без предварительных знаний. оборудования или технологии FPGA. Он обеспечивает высокую скорость по сравнению с традиционными многоядерными симуляторами или симуляторами графического процессора, позволяя разработчикам и нейробиологам реализовывать модели в обычной программной среде.
По сравнению с несколькими другими нейронными симуляторами, которые реализованы на индивидуальном оборудовании, NeuroFlow нацелен на простые в обслуживании стандартные системы и делает нейронную платформу более доступной и портативной. Это позволяет разработчику сосредоточиться на оптимизации реализации моделей и вычислений вместо создания и обслуживания базового оборудования и системы. Более того, он переносится на другие платформы. Таким образом, по мере появления новых и более быстрых платформ производительность платформы может быть увеличена без дополнительных усилий по разработке путем обновления оборудования.
В отличие от аппаратных процессоров, использование FPGA обеспечивает гибкость для изменения моделей и вычислений в нейронном моделировании, позволяя платформе удовлетворять потребности большой группы исследователей. NeuroFlow хранит нейронные и синаптические параметры в больших внекристальных модулях DRAM (динамической памяти с произвольным доступом), что позволяет моделировать сети порядка 100 000 нейронов на одной FPGA. Размер сети, которая может быть смоделирована на одном процессоре, больше, чем у ряда предыдущих нейронных симуляторов FPGA, таких как описанные Graas et al.(2004) и Thomas and Luk (2009), которые хранят все параметры с помощью быстрых, но небольших встроенных в кристалл модулей BRAM (блочная оперативная память). Эта система также обладает большей гибкостью, чем подходы, оптимизирующие определенный класс нейронов, такие как Cassidy et al. (2011) и Merolla et al. (2014).
Наша платформа имеет ряд новых аспектов по сравнению с существующими симуляторами:
• Мы используем PyNN для разработки высокоуровневого API, который предоставляет пользователям описание модели и среду моделирования.Это первый симулятор на основе FPGA, поддерживающий использование PyNN для настройки аппаратного процессора и автоматизации аппаратного сопоставления нейронных моделей. Это означает, что пользователям не требуются специальные знания в области аппаратного обеспечения для использования ускорителя, что позволяет им извлекать выгоду из гибкости и производительности специализированного оборудования с помощью только программного обеспечения без необходимости разбираться в деталях низкоуровневой реализации.
• NeuroFlow может автоматически определять параметры проектирования оборудования на основе нейронной модели, используемой в симуляции, для оптимизации аппаратных ресурсов, таких как степень параллелизма и количество используемых ПЛИС.Это увеличивает производительность и сокращает усилия и время, затрачиваемые на использование аппаратного процессора, для исследователей, мало или совсем не знакомых с аппаратными системами.
• Мы реализуем пластичность, зависящую от времени всплеска (STDP), используя хост-процессор в качестве сопроцессора. Он демонстрирует возможность распределения рабочей нагрузки на основе вычислений для достижения оптимальной производительности нейронного моделирования.
Материалы и методы
Обзор Neuroflow
Целью NeuroFlow является моделирование крупномасштабных SNN с помощью гибких опций модели.Мы разрабатываем платформу моделирования на базе систем FPGA от Maxeler Technology. Он имеет ряд преимуществ по сравнению с существующими аппаратными ускорителями, включая высокую портативность, гибкость и масштабируемость благодаря конструкции аппаратной системы. Мы разрабатываем процесс компиляции для перевода описания нейронной сети в PyNN в описание, используемое NeuroFlow в качестве уровня абстракции для базового оборудования. Описание высокого уровня также помогает автоматически определять параметры оборудования, такие как степень параллелизма, количество используемых ПЛИС и оптимизации, требующие дополнительных аппаратных ресурсов.Как и в предыдущей работе, мы используем программные синапсы, записанные в памяти, в качестве справочных таблиц вместо физических соединений между модулями (Cheung et al., 2012; Moore et al., 2012; Wang et al., 2013), что позволяет осуществлять крупномасштабные сети, моделируемые на высокой скорости. Мы также используем ряд стратегий проектирования оборудования для ускорения и распараллеливания вычислений в NeuroFlow, как описано в Cheung et al. (2012), такие как временное мультиплексирование, конвейерная обработка, обработка всплесков на основе событий и низкоуровневая оптимизация памяти, в разработке NeuroFlow.В настоящее время пользователи должны использовать системы от Maxeler Technologies, но принципы проектирования системы могут быть применены к другим системам на основе FPGA с достаточным объемом памяти.
Аппаратная система
ПЛИС для реконфигурируемых вычислений
ПЛИС— это реконфигурируемые аппаратные процессоры, состоящие из массивов конфигурируемых и фиксированных логических ресурсов, таких как умножители и встроенные модули памяти. Блоки логических ресурсов подключаются через соединительные провода и распределительные коробки.Архитектура типичной ПЛИС показана на рисунке 1. ПЛИС позволяют реализовать определяемую пользователем логику и вычислительные операции путем настройки логических ресурсов и схемных путей, связывающих вход и выход логических блоков, что делает ПЛИС настраиваемым электронным устройством. чип с возможностью перенастройки по желанию. Эта гибкая структура также упрощает распараллеливание вычислений с меньшими накладными расходами по сравнению с процессорами общего назначения. Хотя FPGA обычно работают на гораздо более низкой тактовой частоте, чем процессоры общего назначения, индивидуальные вычисления, реализованные с помощью реконфигурируемых логических блоков, означают, что для завершения может потребоваться всего несколько циклов, что может занять многоядерный процессор от десятков до сотен циклов для обработки.
Рисунок 1. Упрощенная архитектура типичной ПЛИС . ПЛИС состоит из ряда реконфигурируемых логических блоков, которые реализуют произвольные логические функции, и они соединены блоками переключателей и межсоединениями, которые направляют входные и выходные логические блоки в желаемые места назначения. Конфигурация логических блоков и блоков переключателей составляется серверным программным обеспечением с использованием функциональных описаний, написанных на языке описания оборудования.
FPGA предлагает ряд преимуществ для нейронного моделирования по сравнению с другими типами процессоров.Архитектура FPGA поддерживает реконфигурацию оборудования, которая допускает гибкие функциональные описания. ПЛИС имеют большое количество межсоединений с малой задержкой, которые идеально подходят для соединения узлов процессора в высокопроизводительной вычислительной системе. Они также обеспечивают больший контроль доступа к памяти и детальное распараллеливание. Исследователи использовали FPGA для разработки нейрокомпьютеров для искусственных нейронных сетей с пиковыми и без пиковыми пиками (Maguire et al., 2007). Однако сложность программирования ПЛИС может препятствовать их внедрению в требовательных приложениях, таких как нейронное моделирование.В последнее время инструменты синтеза высокого уровня (HLS), способные переводить языки высокого уровня в описания более низкого уровня, позволили сократить время разработки, уменьшить усилия для модификации конструкции и кросс-системную переносимость. Например, в нашей системе мы используем Java для описания вычислений высокого уровня, которые должны быть реализованы на микросхеме.
Высокопроизводительная вычислительная платформа на базе ПЛИС
Мы выбираем системы, предоставленные Maxeler Technologies, в качестве целевой платформы для разработки NeuroFlow.Производитель предлагает ряд высокопроизводительных вычислительных платформ на базе FPGA. ПЛИС сконфигурированы как потоковые процессоры, обеспечивая высокую вычислительную мощность с большим объемом внешней памяти. Доступны различные форм-факторы, включая автономные рабочие столы, многоузловые серверные системы и облачные услуги по запросу. На рис. 2 показаны системная плата и две доступные платформы. Подобно программным платформам, симулятор может работать в любом из этих форм-факторов без изменений, если базовая системная плата FPGA имеет ту же модель.Различные форм-факторы имеют свои плюсы и минусы и подходят исследователям с разными потребностями: автономный рабочий стол обеспечивает доступный и эксклюзивный доступ исследователям для моделирования их собственных моделей; система в масштабе сервера имеет несколько ПЛИС в одном узле и может использоваться для моделирования более крупных сетей; с другой стороны, облачный сервис более удобен и потенциально стоит дешевле, чем другие варианты, поскольку не требует владения физическими системами и, таким образом, подходит для краткосрочного развертывания.В этой работе мы используем автономный настольный компьютер с 1 ПЛИС (процесс Virtex 6, 40 нм) и стоечный сервер с 6 ПЛИС (процесс Altera Stratix V, процесс 28 нм). Поскольку инструменты компилятора и архитектура системы настроены для вычислений потока данных, NeuroFlow нельзя запускать непосредственно на других автономных платах FPGA без изменений.
Рис. 2. Примеры систем Maxeler, запускаемых нейронным симулятором NeuroFlow на . Вверху слева : одиночная системная плата, содержащая одну ПЛИС; вверху справа : рабочая станция с одной платой FPGA; внизу: серверный блок 1U.
Архитектура и вычисления симулятора
Этапы вычислений и основная структура
Архитектура вычислительного ядра показана в нижней части рисунка 3. FPGA имеет два основных аппаратных ядра, которые синтезируются из высокоуровневых описаний, а именно ядро состояния нейрона и ядро синаптической интеграции. Каждый из них отвечает за фазу двухфазного вычисления. Мы используем управляемую по времени модель для обновления состояния нейронов, и каждое из двухфазных вычислений представляет собой временной шаг в 1 мс.Они взаимодействуют с узлом хост-процессора во время начальной настройки в начале моделирования и во время считывания результатов моделирования (пиковый выходной сигнал) в конце моделирования. Во время начальной настройки архитектурные параметры и описание модели нейрона передаются компилятору аппаратного синтеза, который запускает конвейер компиляции (Section Compilation Pipeline). Затем нейронные и синаптические параметры компилируются и загружаются во внешнюю память DRAM на карте FPGA.Во время моделирования параметры, которые должны быть извлечены для последующего анализа, назначенного пользователем, такие как данные пиковых значений и нейронные состояния определенных нейронов, сохраняются во внешней DRAM и передаются на хост после моделирования.
Рис. 3. Конвейер компиляции и загрузка файла времени выполнения NeuroFlow . Конвейер получает код нейронной модели, написанный на Python, который затем компилируется в конфигурацию оборудования, конфигурацию стороны хоста и файл данных памяти.Полученные файлы данных и конфигурации загружаются в главный процессор (CPU) и FPGA системы во время выполнения.
На рисунке 4 показан подробный поток вычислений NeuroFlow на этапе моделирования. Основными этапами вычисления SNN являются (i) обновление состояния нейронов и (ii) накопление синаптического веса.
Рисунок 4. Упрощенный процесс вычислений и архитектура NeuroFlow . Система состоит из двух основных ядер, соответствующих двум основным фазам вычислений: ядро состояния нейрона, которое соответствует фазе обновления нейрона и вычисляет обновленные состояния нейронов с использованием синаптических и нейронных моделей на каждом временном шаге; и ядро синаптической интеграции, которое передает нейронные импульсы на собственные и другие ПЛИС в фазе синаптического накопления.Нейронные и синаптические параметры хранятся в внекристальной памяти большой емкости, в то время как остальные хранятся в высокоскоростной встроенной памяти для оптимизации общей задержки памяти.
На первом этапе процесса (i) ПЛИС обновляют параметры нейронов и записи о выбросах, хранящиеся в большой внешней памяти DRAM. Они извлекаются и обновляются FPGA во время моделирования. Модули обновления состояния нейронов обновляют динамику состояний нейронов параллельно с использованием нейронных моделей на основе обыкновенных дифференциальных уравнений, которые вычисляются в арифметике с плавающей запятой.Количество параллельных нейронных модулей, обычно от 2 до 32, определяется количеством нейронных параметров и доступной пропускной способностью памяти. Эти настраиваемые модули реализованы с мультиплексированием по времени, распараллеливанием и конвейерной обработкой для оптимизации пропускной способности с помощью ряда вариантов модели на выбор.
На втором этапе (ii) ПЛИС извлекают и сохраняют входящие синаптические данные в быстром запоминающем устройстве BRAM на кристалле. Ядро синаптической интеграции извлекает синаптические данные из внешней памяти и затем вычисляет синаптический вход для нейронов.Вычисления выполняются с помощью до 48 параллельных модулей синапсов, ограниченных доступной полосой пропускания и временной задержкой аппаратных логических ресурсов. Доступ к синаптическим данным из памяти и последующая синаптическая обработка запускаются пиками, поэтому общее время обработки примерно пропорционально уровню активности сети. Синаптические данные предварительно обрабатываются и упаковываются в определенный формат с фиксированной точностью перед сохранением во внешней памяти для ускорения моделирования.
Ближайший сосед STDP
Наш симулятор также поддерживает STDP ближайшего соседа, используя как FPGA, так и многоядерные процессоры скоординированным образом. Он демонстрирует, что обычные многоядерные процессоры могут использоваться вместе с FPGA во время нейронного моделирования в этой системе. Метод ближайшего соседа — это распространенный алгоритм пластичности для обучения в SNN (Бенускова и Абрахам, 2007; Бабади и Эбботт, 2010; Хамбл и др., 2012). Это эффективное и хорошее приближение STDP со спайковым взаимодействием «все ко всем», как показано на рисунке 5.Он вычисляет изменение синаптических весов, используя только самые близкие пары спайков вместо всех пар спайков, чтобы уменьшить сложность вычислений, оставаясь при этом биологически точным (Ижикевич и Десаи, 2003). В соответствии с Ижикевичем и Десаи (2003), мы учитываем только пресинаптически-центрические взаимодействия, так что только первый постсинаптический спайк до или после пресинаптического спайка может вызвать депрессию или потенцирование, но, тем не менее, система способна реализовывать другие формы взаимодействий.Мы реализуем аддитивную модель STDP в NeuroFlow, и другие типы более сложных моделей, такие как мультипликативная синаптическая модель, могут быть включены за счет дополнительных аппаратных ресурсов. Требуемый аппаратный ресурс будет пропорционален степени параллелизма модулей синапсов.
Рис. 5. (A) Спайковые взаимодействия между пре- и постсинаптическими нейронами для обучения STDP. Поскольку количество взаимодействий пропорционально квадрату скорострельности, эта парадигма требует больших вычислительных ресурсов. (B) Пресинаптические спайковые взаимодействия между пре- и постсинаптическими нейронами для обучения STDP приняты в NeuroFlow. Этот метод эффективен с точки зрения вычислений и может аппроксимировать парадигму «все ко всем» с высокой биологической достоверностью.
Для вычисления STDP ПЛИС отправляет данные пиков многоядерному процессору, который обновляет таблицу относительного времени пиков, хранящуюся на стороне хоста, размером, пропорциональным максимальной аксональной задержке. Кэш памяти на стороне хоста более эффективен для выборки и обновления данных в произвольных ячейках памяти, что дополняет слабость FPGA в этом отношении.Информация об относительной синхронизации используется для доступа к изменениям синаптических весов в таблице поиска, которые накапливаются и отправляются обратно в FPGA. Обмен данными для обновления таблицы синаптических весов происходит с фиксированным интервалом временных шагов, указанным пользователем (например, 100 мс и 1000 мс в примерах из раздела «Результаты»), чтобы уменьшить накладные расходы на обмен данными.
Для эффективной реализации правила STDP мы используем схему, аналогичную модели отложенных событий (Раст и др., 2009), которая минимизирует количество обращений к памяти путем пакетной обработки изменений веса.Схема сохраняет пики на предыдущих временных шагах и вычисляет соответствующее изменение веса только через определенное временное окно, обычно несколько десятков миллисекунд. Временное окно устанавливается таким образом, чтобы никакие дальнейшие всплески не могли вызвать изменения в синапсах из-за всплеска нейрона в начале окна.
Автоматическая настройка с использованием описания PyNN
Поскольку платформа FPGA является реконфигурируемой и имеет ограниченные аппаратные ресурсы, в идеале можно было бы моделировать SNN с индивидуальным дизайном для каждой конкретной нейронной модели, чтобы оптимизировать использование ресурсов.Высокоуровневое описание сети в PyNN облегчает автоматическую настройку, чтобы вернуть набор параметров для проектирования оборудования. Мы определили ряд проектных параметров, которые могут определяться требованиями моделирования и аппаратными ограничениями. Такая настройка обеспечивает дальнейшее ускорение за счет дополнительных аппаратных ресурсов. Когда параметры настройки включены, компиляция попытается скомпилировать проект с максимальным использованием аппаратных ресурсов, а затем перейдет к проектам с более низкими требованиями к ресурсам, когда аппаратных ресурсов недостаточно или временные ограничения не соблюдены.Переменные делятся на два типа:
• Статические параметры — это параметры времени компиляции для кода вычислительной машины, и при изменении этих параметров требуется перекомпиляция оборудования. Поскольку для типичной перекомпиляции аппаратной части FPGA требуется 10–20 часов, эти параметры не часто меняются для данной модели и конфигурации. Статические параметры определяются путем анализа описания PyNN и доступных аппаратных ресурсов в системе. Параметры включают:
1.Количество параллельных модулей обновления состояния нейронов. Обычно параллелизм рассчитывается как разрядность потока памяти, деленная на точность (одинарная или двойная точность) и количество нейронных параметров на нейрон.
2. Дополнительный механизм кеширования веса для доступа к синаптической памяти. Он использует дополнительные буферы BRAM на кристалле для хранения данных. В настоящее время требуемые дополнительные ресурсы оцениваются по предыдущим сборкам. Вместе с используемой ПЛИС и размером сети, которую необходимо моделировать, эта информация может определить, может ли этот механизм быть встроен в проект.
3. Метод синаптической организации, основанный на плотности нейронных связей. Сеть с плотным подключением может быть упакована в более компактный формат, что может привести к сокращению аппаратных ресурсов.
• Динамические параметры — это параметры моделирования во время выполнения, считываемые хост-процессором, которые не нуждаются в перекомпиляции оборудования. Параметры не могут быть изменены во время симуляции, но могут быть изменены между разными симуляциями в одной и той же программе. Параметры включают количество используемых FPGA, распределение имитируемых нейронов и количество нейронов, обрабатываемых каждой FPGA.
Спецификация модели
PyNN для спецификации нейронной модели
PyNN — это пакет нейронного моделирования на основе Python с открытым исходным кодом для построения моделей нейронных сетей, разработанный Davison et al. (2008). Он предлагает простой и стандартизированный язык для нейронного моделирования и позволяет перепроверять результаты между различными средами моделирования без необходимости переписывать код. Кроме того, пользователи также могут использовать инструменты визуализации и анализа, совместимые с PyNN.В настоящее время PyNN имеет API-интерфейсы с рядом популярных стандартных программ нейронного моделирования, таких как NEURON, NEST и Brian (Davison et al., 2008), которые можно установить вместе с пакетами программного обеспечения. Следовательно, результаты NeuroFlow могут быть сопоставлены с программными симуляторами. В ряде крупномасштабных симуляторов также реализованы высокоуровневые привязки с PyNN для облегчения использования симуляторов, таких как SpiNNaker (Galluppi et al., 2010) и FACETS (Brüderle et al., 2011).
Воспользовавшись его популярностью, мы применяем PyNN для предоставления стандартизованного интерфейса для построения нейронных моделей.Код 1 показывает пример, который можно использовать для объявления популяций нейронов, создания нейронных соединений и настройки параметров оборудования в NeuroFlow. Пользователь может определять совокупности нейронов, которые имеют один и тот же параметр (параметры) нейронов, и соединять их, используя различные методы проекции для добавления синапсов. Пользователь также может установить параметры конфигурации оборудования, такие как тактовая частота и степень параллелизма, с помощью команды настройки. Если не указано явно, используются значения по умолчанию.
Код 1.Пример кода интерфейса NeuroFlow PyNN . Использование такое же, как и в стандартном формате PyNN. Код создает ряд нейронов с интеграцией и запуском и соединяет их с помощью универсального метода коннектора, предоставляемого PyNN. Пользователь может подавать внешнюю стимуляцию нейронам и записывать активность нейронов. Пользователь может изменить конфигурации оборудования, такие как параллелизм, максимальная задержка аксонов и тактовая частота ПЛИС, используя функцию setup .
Конвейер компиляции
Чтобы автоматизировать процесс запуска нейронных моделей и определения параметров оборудования, мы разрабатываем конвейер процессов компиляции для преобразования высокоуровневой спецификации в конфигурацию оборудования для системы FPGA.
Общий поток компиляции изображен на рисунке 3. На первом этапе конвейера интерфейс PyNN извлекает и преобразует нейронные и синаптические параметры в определенный формат, как описано в Cheung et al. (2012) для облегчения распараллеливания обновления состояния нейронов и накопления синаптических входных данных, которые затем записываются в файлы данных памяти. С другой стороны, инструмент компиляции также определяет ряд параметров проекта на основе условий моделирования и аппаратных ограничений, чтобы обеспечить возможность настройки и оптимизации аппаратных ресурсов (раздел «Автоматическая настройка с использованием описания PyNN»).
На следующем этапе мы используем инструменты, предоставленные Maxeler, для компиляции кода, написанного на Java, описывающего вычисления и архитектуру, в описания оборудования, читаемые FPGA. Компилятор считывает статические параметры и выбирает, какие модели реализовать на этапе синтеза в соответствии с пользовательскими спецификациями. Вместо программных процессоров, которые используются рядом других подходов к FPGA (Maguire et al., 2007), дифференциальные уравнения компилируются в представления путей потока данных для построения конвейерных вычислений на уровне схем.Хотя этот подход эффективен по площади, при использовании другой нейронной модели требуется новая аппаратная компиляция. Затем инструмент компиляции вызывает программное обеспечение конкретного производителя, которое выполняет преобразование описаний аппаратного языка нижнего уровня в формат VHDL, отображение аппаратных ресурсов и место и маршрут (PAR), которое определяет фактическую аппаратную реализацию. В конце этого процесса создается файл битового потока FPGA, который описывает конфигурацию оборудования для симулятора.Затем главный процессор считывает код хоста, сгенерированный в процессе компиляции, инициирует обмен данными с ПЛИС и запускает процесс моделирования.
Уровни описания
Для создания общей системы нейронного моделирования, которая позволяет сообществу нейронного моделирования использовать этот ускоритель в качестве серверной части моделирования, фактическая реализация оборудования должна быть отделена от пользователя. Мы используем инструменты PyNN и Maxeler для реализации ряда уровней абстракции для запуска нейронного моделирования.
Используя несколько уровней абстракции, NeuroFlow позволяет пользователям писать на предметно-ориентированном языке, с которым они знакомы, для ускорения работы оборудования без глубоких знаний об оборудовании. Как показано на рисунке 6, каждый уровень описания NeuroFlow описывает отдельный аспект для моделирования нейронной сети на ПЛИС. Каждый уровень можно изменять независимо от других уровней, что упрощает обслуживание и разработку платформы.
Рисунок 6. Уровни описания нейронного моделирования в NeuroFlow .Описание системы NeuroFlow состоит из нескольких уровней: уровень приложения, уровень электронной системы и уровень регистрации-передачи. Пользователи системы кодируют только на уровне приложений и используют функции, предоставляемые с уровней ниже, без необходимости знать детали оборудования. Изменения в реальной реализации нейронных моделей вносятся на уровне электронной системы, которая не зависит от оборудования. Уровень передачи регистров реализуется на аппаратном уровне и обрабатывается программным обеспечением, предоставляемым поставщиком, что снижает затраты на обслуживание системы.
Верхний уровень приложения описывает типы нейронов, сетевое соединение и экспериментальную установку. Описание будет переносимо на различные серверы для проверки и проверки. Он соответствует пользовательскому коду на Python в NeuroFlow, где пользователь указывает нейронную модель и параметры настройки, а также работу по переводу для извлечения описания в Python на последующие этапы конвейера. Затем уровень электронной системы описывает поведение потока вычислений (дифференциальные уравнения, синаптическое интегрирование и STDP) и конфигурацию системы, такую как внешняя память и межпроцессорная связь.Когда используется другая система, необходимо изменять только конфигурацию системы, а не весь код вычислительной машины, что облегчает переносимость между различными системами. Аппаратное обеспечение также автоматически настраивается на основе высокоуровневого описания, что означает повышение производительности без ущерба для удобства использования системы. На самом низком уровне описания оборудования FPGA программа транслируется на язык описания оборудования, такой как VHDL, который затем компилируется в фактический поток битов FPGA с использованием инструментов синтеза, специфичных для внутренних поставщиков.
Поддерживаемые функции симулятора
NeuroFlow предлагает ряд общих моделей и функций, используемых в нейронном моделировании, которые суммированы в таблице 1. В настоящее время NeuroFlow поддерживает ряд нейронных моделей, и процесс добавления новых моделей в симулятор относительно прост, добавляя необходимые нейронные параметры в бэкэнде PyNN и написание соответствующих дифференциальных уравнений в функциональном описании Java. В настоящее время поддерживаются модели с утечкой, интегрируйте и запускайте (Герстнер и Кистлер, 2002), адаптивную экспоненциальную интеграцию и запускайте (Бретт и Герстнер, 2005), модель Ижикевича (Ижикевич, 2003) и модель Ходжкина. Модель Хаксли (Hodgkin and Huxley, 1952).Кроме того, симулятор может использовать различные решатели обыкновенных дифференциальных уравнений (ОДУ); в настоящее время в NeuroFlow реализованы методы Эйлера и Рунге-Кутта, чтобы продемонстрировать эту возможность. Нейроны можно разделить на нейронные популяции, а параметры нейронов, которые являются общими для популяции, можно объявить через интерфейс PyNN, и, таким образом, уменьшить использование памяти за счет удаления повторяющихся параметров.
Таблица 1. Обзор функций, поддерживаемых NeuroFlow .
Текущая схема предполагает, что синаптические веса являются линейными и аддитивными как для возбуждающих, так и для тормозных синапсов, которые накапливаются во встроенной памяти и могут быть изменены при необходимости. Пользователь может определять различные входные функции синаптического тока, такие как функция экспоненциального затухания, альфа-функция или дельта-функция.
Пользователь может указать произвольную подачу внешнего тока в нейроны, а такие параметры, как амплитуда, время и индекс целевого нейрона, сохраняются во встроенной памяти.Для генерации шума, поступающего в нейроны, доступен ряд генераторов случайных чисел, включая генераторы однородных и нормально распределенных случайных чисел. Пользователь также может отслеживать выбросы и мембранный потенциал определенных нейронов, которые сохраняются на FPGA во время моделирования и отправляются обратно в главный процессор после завершения моделирования.
Текущая реализация системы отображает нейроны на оборудование, последовательно назначая нейроны ПЛИС в соответствии с их индексами.Хотя этот подход прост и эффективен, связь между ПЛИС может не быть оптимизирована и может привести к увеличению времени моделирования при использовании более чем одной ПЛИС. Теоретически связь между ПЛИС и отображением может быть осуществлена аналогично тому, как это делается у Furber et al. (2013), которые представили виртуальный слой отображения для эффективной передачи спайков.
Результаты
Чтобы оценить производительность платформы, мы моделируем ряд моделей для проверки точности, скорости и энергопотребления нашей платформы.Модели различаются по размеру и сложности, чтобы протестировать весь спектр возможностей, предлагаемых NeuroFlow.
Два нейрона с парной стимуляцией
В первой серии экспериментов мы проверяем точность и точность вычислений путем моделирования двух адаптивных экспоненциальных интегрирующих и запускающих нейронов (aEIF) с внешней стимуляцией и STDP (рис. 7A). Динамика мембранного потенциала описывается следующими уравнениями:
CdVdt = −gL (V − EL) + gLΔTexp (V − VTΔT) −w + I (1) τwdwdt = a (V − EL) −w (2)Рисунок 7.Моделирование с использованием NeuroFlow с включенным STDP по протоколу парной стимуляции . (A) Моделирование состоит из двух связанных между собой нейронов aEIF. Каждый из них получает попеременную стимуляцию 10 мА в течение 250 мс. (B) Профиль STDP, использованный для моделирования, с A + = 0,1, A — = 0,12 и τ + = τ — = 20 мс (C) Следы мембранного напряжения два нейрона с разницей во времени спайков 10 мс.Нейроны вспыхивают при получении внешней стимуляции, где синие (красные) стрелки соответствуют времени, когда нейрон a (нейрон b) получает внешнюю стимуляцию на диаграмме. (D) Эволюция силы синаптической связи между двумя нейронами во времени в испытании, описанном в (C) .
Модель представляет собой систему с двумя дифференциальными уравнениями, которые решают для мембранного потенциала V и переменной адаптации w. Модель получает входной ток I и имеет параметры мембранной емкости C, проводимости утечки g L , реверсивного потенциала E L , порога выброса V T , коэффициента наклона Δ T , параметра связи адаптации a и времени адаптации. постоянная τ w .Бретт и Герстнер (2005) показали, что модель способна воспроизводить точную временную динамику биологических нейронов.
Мы проверяем влияние STDP на синаптическую силу, моделируя два нейрона, запускаемых поочередно в течение 250 мс, используя внешний входной ток 10 мА с разницей во времени всплеска 10 мс. Применяется общий профиль STDP с временной причинно-следственной связью (рисунок 7B). Вес изменен в соответствии со следующими правилами:
Δw + = A + exp (−Δtτ +) при Δt> 0 (3) Δw− = A − exp (−Δtτ−) для Δt <0 (4)с параметрами A + = 0.1, A — = 0,12 и τ + = τ — = 20 мс, где учитываются только самые близкие спайки для каждого срабатывания пресинаптических нейронов.
На рисунках 7C, D показаны результаты моделирования. Нейроны стимулируются извне, чтобы заставить нейроны срабатывать в моменты времени, обозначенные красными и синими стрелками. Два нейрона производят возбуждающие постсинаптические потенциалы (ВПСП) в другом нейроне, когда они вспыхивают, с начальной синаптической силой 0,1. Из-за эффекта обучения STDP нейрон B получает более сильный синаптический ввод от нейрона A, и, наоборот, нейрон A получает более слабый синаптический ввод от нейрона B.Синаптическая сила ограничена значениями, определяемыми пользователем, в этом случае 0
Крупномасштабная пиковая сеть
Чтобы проверить производительность NeuroFlow для моделирования больших сетей, мы моделируем крупномасштабные сети размером до 589 824 нейронов с возбуждающими и тормозящими нейронами, как показано на рисунке 8.Сеть аналогична той, которую использовали Фиджеланд и Шанахан (2010), с параметрами нейронов, взятыми из Ижикевича (2003), для оценки их нейронного симулятора. В следующей таблице показаны детали оборудования и моделирования. Указанные время настройки и время считывания увеличиваются с увеличением размера сети, а время считывания увеличивается со временем моделирования.
Рис. 8. Тороидальная нейронная сеть . Каждая точка представляет положение нейрона.Вероятность синаптического соединения зависит от расстояния между нейронами, имеющего гауссово распределение. Пунктирные кружки обозначают вероятность соединения в пределах 1 и 2 стандартных отклонений. Одна FPGA обрабатывает 98 304 нейронов.
Сеть имеет тороидальную структуру, и вероятность соединения пространственно ограничена. Каждый нейрон подключается к разному количеству постсинаптических нейронов n syn с помощью статических или пластиковых синапсов, чтобы проверить влияние количества синапсов на производительность платформы (в данном случае без STDP, т.е.е., для статических синапсов), где n syn находится в диапазоне от 1000 до 10 000 при моделировании. Значения синаптической силы устанавливаются на случайные значения от 0 до 0,5 и регулируются с помощью коэффициента масштабирования n syn , чтобы обеспечить аналогичный уровень сетевой активности в различных сценариях n syn . Вероятность соединения следует гауссовской вероятности синаптического расстояния со стандартным отклонением (S.D.) изменения σ для соединений от возбуждающих нейронов и S.D. из 16 для тормозных нейронов. Мы тестируем σ в диапазоне от 32 до 512, чтобы оценить влияние разреженности соединений на производительность системы. Задержки проводимости синапсов пропорциональны расстоянию между нейронами, с максимальной задержкой 16 мс для возбуждающих синапсов и задержкой 1 мс для тормозных нейронов, чтобы обеспечить быстрое торможение со стороны тормозных нейронов и ритмическую активность сети.
При отображении сети на ПЛИС каждая ПЛИС обрабатывает вычисление 98 304 нейронов, находящихся в непосредственной пространственной близости, и для моделирования используются максимум шесть ПЛИС.Из-за расположения синаптических соединений нейроны подключаются к целям на той же или соседней FPGA, таким образом, аппаратное отображение нейронов облегчает получение синаптических данных. Нейронам, которые находятся ближе к границе, таким как нейрон – на рисунке 8, требуется немного больше времени для сбора синаптических данных, чем нейрону –.
На рисунке 9 показана производительность системы для моделирования с использованием двух показателей: ускорение в реальном времени и скорость доставки пиков.На ускорение относительно реального времени влияет количество требуемых FPGA и количество синапсов. Скорость доставки пиков, предложенная Фиджеландом и Шанаханом (2010) в качестве меры производительности, которая измеряет пропускную способность системы независимо от скорости срабатывания, получается путем расчета количества пиков, доставляемых системой в секунду.
Рис. 9. (A) Ускорение NeuroFlow относительно реального времени и (B) производительность NeuroFlow с точки зрения скорости доставки пиков.Ускорение NeuroFlow обратно пропорционально размеру сети, а сети с меньшим количеством синапсов на нейрон работают в несколько раз быстрее. Из-за накладных расходов на распределение вычислений между разными процессорами ускорение сети не зависит от ее размера.
Для моделирования с использованием STDP мы моделируем сеть из 55 000 нейронов с применением STDP к возбуждающим синапсам, используя профиль STDP в разделе «Фазы вычислений» и «Основная структура».Тормозящие синапсы настроены как непластические, как описано в предыдущей литературе (Phoka et al., 2012). Мы тестируем два случая с разной частотой обновления синаптической силы, 1 и 10 Гц, и измеряем производительность. Частота определяет интервал между пакетным обновлением синаптических весов, и, следовательно, более низкая частота обновления влечет меньшие накладные расходы. Изменения веса группируются, а затем обновляются в DRAM FPGA через каждый фиксированный интервал (1 с и 100 мс соответственно). На рисунке 10 показана производительность NeuroFlow в сравнении с многоядерными симуляторами и симуляторами графического процессора.Поскольку общее количество синаптических обновлений пропорционально частоте обновления STDP и количеству синапсов, эти два параметра сильно влияют на время вычислений. Обновление синаптических весов в FPGA также требует большой полосы пропускания для передачи данных между хост-процессором и FPGA, что ограничивает частоту обновления весов. Мы сравниваем производительность NeuroFlow с производительностью программного симулятора NEST (Gewaltig and Diesmann, 2007) на 8-ядерном процессоре i7 920 и симуляторе на базе графического процессора (Richert et al., 2011) на графическом процессоре Tesla C1060. При частоте обновления 1 Гц NeuroFlow в среднем в 2,83 раза быстрее, чем графический процессор, и в 33,6 раза быстрее, чем обычный процессор.
Рисунок 10. Сравнение производительности различных тренажеров . Производительность NeuroFlow сравнивается с производительностью программного симулятора на базе ЦП NEST и симулятора на базе графического процессора CarlSim. NeuroFlow быстрее платформ GPU и CPU в 2,83 и 33,6 раза соответственно при моделировании сетей из 55 000 нейронов с использованием 100, 300 и 500 синапсов с включенным STDP и частотой обновления 1 Гц.
Нейронная сеть с полихронными пиками
Мы моделируем сеть, которая демонстрирует полихронизацию, как показано в Ижикевич (2006), как форма функциональной проверки. Используя взаимодействие между задержкой проводимости и STDP, модель отображает большое количество самоорганизованных нейронных групп, которые демонстрируют воспроизводимые и точные последовательности активации в зависимости от конкретного паттерна активации (рис. 12A). Количество паттернов может быть больше, чем количество нейронов в сети, что показывает потенциальный скачок вычислительной мощности нейронов по сравнению с традиционными моделями нейронов, основанными на скорости.Сеть также демонстрирует диапазон ритмической активности и баланс возбуждения и торможения, аналогичный биологическим сетям. Из-за длительного моделирования, необходимого для демонстрации влияния STDP на схемы запуска, это хороший пример для демонстрации необходимости в платформах нейронного моделирования, таких как NeuroFlow и других реализациях на основе FPGA, таких как Wang et al. (2013) для таких экспериментов.
В эксперименте моделируется сеть из 1000 нейронов Ижикевича, каждый со 100 пластиковыми синапсами.Моделирование длится 24 часа модельного времени с временным разрешением 1 мс. Каждую миллисекунду в сети случайным образом выбирается один нейрон, который получает случайный входной сигнал амплитудой 20 мВ. Вероятность соединения между нейронами составляет 0,1, и STDP включен для возбуждающих синапсов. Каждый синапс имеет случайную задержку проводимости 1–20 мс. Для завершения моделирования в NeuroFlow требуется 1435 с, что в 15 раз быстрее, чем 6 часов, о которых сообщалось в первоначальном исследовании с использованием ПК с процессором 1 ГГц. Различные комбинации пресинаптических якорных нейронов в отсутствие случайного входа тестируются после моделирования, чтобы выяснить возможные группы нейронов.
На рисунке 11 показан растровый график моделирования, демонстрирующий влияние STDP на динамику нейрона. При первом запуске моделирования в сети виден ритм от 2 до 4 Гц, который исчезает во время моделирования и заменяется гамма-ритмом 30–100 Гц после времени моделирования, равного 1 часу модельного времени. На рисунке 12B показан образец группы нейронов после моделирования. Нейроны спонтанно самоорганизуются в группы и генерируют синхронизированные по времени паттерны. Пост-симуляционный анализ обнаружил 520 нейронных групп, которые согласованы на протяжении всей симуляции после первого часа моделирования.Смоделированные данные согласуются с результатами исходного исследования, что приводит к аналогичному распределению размеров групп.
Рис. 11. (A) Растровый график сетевой активности с 1000 нейронами в начале моделирования. (B) Растровый график того же набора нейронов после 3600-секундного моделирования с включенным STDP. Он показывает колебания 2–4 Гц до моделирования и 30–100 Гц после моделирования, что очень похоже на исходную реализацию.
Рисунок 12. (A) Принцип работы полихронизации. Ижикевич (2006) предложил этот механизм, который показывает, что различная задержка спайковой проводимости может создавать синхронизированные по времени паттерны спайков, которые запускаются определенным начальным паттерном активации. Эта закономерность возникает спонтанно во время длительного моделирования сети с помощью STDP. Пунктирная линия показывает распространение всплесков в сети. (B) Моделируемая полихронная сеть создает ряд синхронизированных по времени шаблонов при активации определенных нейронов.
Обсуждение
В свете растущего интереса к моделированию крупномасштабных нейронных сетей, существует потребность в платформах с такими возможностями, которые являются мощными, но простыми в использовании и гибкими. Ориентируясь на настраиваемые ПЛИС, мы разрабатываем NeuroFlow, который предлагает гибкую, портативную и масштабируемую среду моделирования для сетей SNN, доступную в различных форм-факторах, от многоузловых суперкомпьютеров до автономных настольных систем. NeuroFlow стремится заполнить пробел с точки зрения гибкости и масштабируемости всего спектра настраиваемых ускорителей SNN.На одном конце спектра системы на основе ASIC имеют самое высокое ускорение и самое низкое энергопотребление среди всех форм нейронных вычислительных систем (Silver et al., 2007; Schemmel et al., 2010; Merolla et al., 2014), но им не хватает гибкости, и они не широко доступны из-за высокой стоимости производства. На другом конце спектра ускорители на основе многоядерных процессоров и систем графического процессора поддерживают широкий спектр синаптических, нейронных и пластических моделей (Fidjeland and Shanahan, 2010; Richert et al., 2011; Hoang et al., 2013), но потребляемая мощность высока для большого кластера GPU. Системы на основе FPGA предлагают золотую середину, которая может быть очень полезной для крупномасштабных программ моделирования мозга. Следуя первым начальным реализациям нейронных систем с пиковыми импульсами на ПЛИС (Cheung et al., 2012; Moore et al., 2012; Wang et al., 2013, 2015), здесь мы подробно сообщаем о первом, гибком, общем -целевая реализация крупномасштабной нейронной сети, включающей «полные» нейроны в стиле Ижикевича и STDP.
При разработке специализированных нейрокомпьютеров гибкость иногда приносится в жертву для достижения более высокого ускорения, но это делает платформу менее полезной для нейробиологов, которые обычно выполняют конкретные и быстрые модификации моделей. Проекты ASIC имеют самую низкую программируемость и гибкость. Модели нейронов с импульсами фиксируются во время изготовления, а синаптические соединения часто непластичны, имеют низкую точность и имеют ограничения по количеству и шаблону соединений. Для сравнения, система SpiNNaker, основанная на процессорах ARM, предлагает высокую степень гибкости, но из-за небольшого количества нейронов, обрабатываемых каждым процессором (порядка 10 4 нейронов) и необходимости длинных путей связи для больших сетей, платформа плохо справляется со случаями с большим количеством событий, таких как плотное соединение, STDP или высокоактивная сеть (Furber et al., 2014). Эти ситуации обычны в нейронном моделировании, но часто не учитываются при построении нейроморфных систем. Кроме того, индивидуальные аппаратные платформы должны быть перепроектированы и изготовлены, когда возникает необходимость в замене или включении дополнительных моделей, таких как пластичность, нейронные отсеки, ионные каналы, щелевые соединения или более высокая точность. Например, SpiNNaker использует представление чисел с фиксированной запятой вместо арифметики с плавающей запятой в качестве представления по умолчанию, что приводит к трудностям и ограничениям программирования, таким как отсутствие встроенной операции деления и проблемы с точностью (Furber et al., 2013).
Интеграция PyNN в дизайн симулятора NeuroFlow дает ряд преимуществ с точки зрения разработки модели и повышения производительности. PyNN сокращает время разработки модели, позволяя разработчикам моделей переносить моделирование в новую среду моделирования с меньшими затратами времени и проверять правильность своих моделей в других симуляторах. Это также позволяет автоматизировать настройку оборудования, что позволяет оптимизировать использование аппаратных ресурсов. В настоящее время разработка с использованием инфраструктуры PyNN сталкивается с рядом проблем, таких как обратная несовместимость, мелкие дефекты и отсутствие технической поддержки; но идея интеграции языка нейронного описания высокого уровня с аппаратной платформой для ускорения моделирования привлекательна и полезна.
Нейронные сети для различных целей требуют различных уровней абстракции и точности. На сегодняшний день нет единого мнения о том, каков оптимальный уровень абстракции для описания биологической нейронной сети. Обычно модели с более высокой сложностью имеют более богатую динамику, что способствует их большей вычислительной мощности. Например, нелинейные дендриты могут решать линейно неразделимые задачи классификации (Cazé et al., 2013), а расширение точечных нейронов с целью включения одного или нескольких дендритных отделов может резко изменить динамику возбуждения нейрона, которая может учитывать наблюдения. из экспериментов (Rospars, Lánský, 1993; Vaidya, Johnston, 2013).Таким образом, изменения в описании модели повлияют на потребность в вычислительных возможностях нейрокомпьютера. Хотя эти свойства обычно игнорируются при разработке нейрокомпьютера, иногда они имеют решающее значение при моделировании нейронов. Учитывая большое разнообразие нейрональных, синаптических и пластических моделей, используемых в нейробиологии, негибкие платформы нейронного моделирования будут иметь ограниченную ценность для вычислительных нейробиологов.
В этом отношении одним из возможных вариантов использования NeuroFlow является создание прототипов нейрокомпьютеров.Инженеры могут тестировать различные конфигурации с помощью нейрокомпьютеров на базе FPGA и находить оптимальную точность для данного приложения и использовать минимальную сложность и точность в качестве системных конфигураций. Подобно прототипированию ASIC с использованием FPGA, прототипирование с использованием NeuroFlow может снизить стоимость модификации чипа и может принести пользу будущим нейронным вычислительным системам.
Как показали эксперименты, NeuroFlow демонстрирует хорошую производительность и гибкость, но у него есть ряд проблем, которые необходимо решить, чтобы расширить его привлекательность.В то время как изменения нейронных, синаптических параметров и параметров моделирования требуют только создания новых файлов данных, FPGA требует значительного времени на синтез для перекомпиляции конфигураций оборудования. Однако был предпринят ряд попыток сократить время синтеза за счет использования предварительно скомпилированных модулей, таких как жесткое макросшивание (Lavin et al., 2011) и модульная реконфигурация (Sedcole et al., 2006). В то время как текущая система эффективна при обработке большого размера сети из 10 5 –10 6 нейронов с использованием простого межсоединения, необходимо проделать дополнительную работу над схемой нейронного сопоставления и взаимодействием между узлами, например, аналогичная работа над SpiNNaker ( Хан и др., 2008), чтобы расширить масштабируемость существующей системы для поддержки моделирования более крупных сетей. Другой вопрос — энергопотребление системы. NeuroFlow использует внешнюю DRAM и, следовательно, не так энергоэффективен, как автономные платформы FPGA, но замена их более быстрой и энергоэффективной SRAM может решить проблему.
В настоящее время существует большой пробел в нашем понимании между небольшими нейронными сетями и нейронной системой в целом. Такие модели, как работа Ижикевича и Эдельмана (2008), включают динамику отдельных нейронов в крупномасштабную модель человеческого мозга, которую можно использовать для сравнения с данными визуализации всего мозга и потенциально может привести к разработке персонализированной диагностики и лечения. .Разработка нейронных симуляторов, таких как NeuroFlow, позволяет нейробиологам изучать нейронную динамику с высокой скоростью и исследовать пространство параметров и подгонку параметров к нейрофизиологическим измерениям, которые устраняют разрыв между мелкими и крупномасштабными исследованиями. NeuroFlow демонстрирует многообещающие возможности нейронного моделирования в производительности, простоте использования для нейробиологов и гибкости, что продемонстрировано в моделировании полихронной сети и соматосенсорной коры. Благодаря настраиваемости, предлагаемой NeuroFlow, он облегчает исследование различных конфигураций оборудования, которые могут привести к лучшим и более эффективным реализациям нейронных сетей.Также есть планы расширить функции NeuroFlow, такие как включение шаровых моделей и синапсов AMPA, NMDA и GABA с нелинейной временной динамикой, чтобы поддерживать моделирование более сложной нейронной динамики и сделать платформу полезно для более широкой группы нейробиологов.
Авторские взносы
KC, SS и WL придумали идею исследования, KC провел исследование и подготовил рисунки, KC, SS и WL написали рукопись. Все авторы рецензировали рукопись.
Заявление о конфликте интересов
Авторы заявляют, что исследование проводилось при отсутствии каких-либо коммерческих или финансовых отношений, которые могут быть истолкованы как потенциальный конфликт интересов.
Благодарности
Это исследование получило финансирование от программы Horizon 2020 Европейского Союза со ссылкой на проект 671653. Поддержка Фонда Краучера, UK EPSRC (ссылки на гранты EP / I012036 / 1 и EP / L00058X / 1), HiPEAC NoE, Программа Университета Макселера, Altera и Xilinx выражают признательность.
Список литературы
Анантанараянан Р., Эссер С. К., Саймон Х. Д. и Модха Д. С. (2009). «Кот вышел из мешка: моделирование коры с 10 9 нейронами, 10 13 синапсов», в материалах Proceedings of the Conference on High Performance Computing Networking, Storage and Analysis (Portland, OR: IEEE), 1 –12.
Бенускова, Л., и Абрахам, В. К. (2007). Правило STDP, наделенное скользящим порогом BCM, учитывает гетеросинаптическую пластичность гиппокампа. J. Comput. Neurosci. 22, 129–133. DOI: 10.1007 / s10827-006-0002-x
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Блэр, Х. Т., Конг, Дж., И Ву, Д. (2013). «Механизм моделирования ПЛИС для индивидуального построения нейронных микросхем», в Международная конференция IEEE / ACM по автоматизированному проектированию (Сан-Хосе, Калифорния), 607–614.
Бретт Р. и Герстнер В. (2005). Адаптивная экспоненциальная модель интеграции и запуска как эффективное описание нейронной активности. J. Neurophysiol. 94, 3637–3642. DOI: 10.1152 / jn.00686.2005
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Брюдерле Д., Петрович М. А., Фоггингер Б., Эрлих М., Пфейл Т., Миллнер С. и др. (2011). Комплексный рабочий процесс для нейронного моделирования общего назначения с настраиваемыми нейроморфными аппаратными системами. Biol. Киберн. 104, 263–296. DOI: 10.1007 / s00422-011-0435-9
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Кэссиди, А., Андреу, А.Г., и Георгиу, Дж. (2011). «Проектирование нейроморфной системы с одним миллионом нейронов на ПЛИС для многомодального анализа сцены в реальном времени», в 45-я ежегодная конференция по информационным наукам и системам (Балтимор, Мэриленд: IEEE), 1–6.
Кэссиди А., Денхэм С., Канольд П. и Андреу А. (2007). «Нейронная матрица на основе кремниевых пиков на базе FPGA», в Biomedical Circuits and Systems Conference 2007 (Montreal, QC), 75–78.
Казе, Р. Д., Хамфрис, М., и Гуткин Б. (2013). Пассивные дендриты позволяют отдельным нейронам вычислять линейно неразрывные функции. PLoS Comput. Биол. 9: e1002867. DOI: 10.1371 / journal.pcbi.1002867
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Cheung, K., Schultz, S. R., and Leong, P.H. (2009). «Симулятор нейронной сети с параллельными пиками», International Conference on Field-Programmable Technology (Сидней, Новый Южный Уэльс), 247–254.
Cheung, K., Schultz, S.Р., и Лук, В. (2012). «Крупномасштабный ускоритель нейронной сети для систем FPGA», в Искусственные нейронные сети и машинное обучение — ICANN 2012 , ред. AEP Villa, W. Duch, P. Érdi, F. Masulli и G. Palm (Берлин; Гейдельберг: Springer), 113–120.
Конг, Дж., Блэр, Х. Т., и Ву, Д. (2013). «Механизм моделирования ПЛИС для создания нейронных микросхем по индивидуальному заказу», в 21-й ежегодный международный симпозиум IEEE по программируемым пользовательским вычислительным машинам , 229.
Дэвисон, А. П., Брюдерле, Д., Эпплер, Дж., Кремков, Дж., Мюллер, Э., Печевски, Д. и др. (2008). PyNN: общий интерфейс для симуляторов нейронных сетей. Фронт. Нейроинформ. 2:11. DOI: 10.3389 / нейро.11.011.2008
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Элиасмит К., Стюарт Т. К., Чу X., Беколай Т., ДеВольф Т., Танг Ю. и др. (2012). Масштабная модель функционирующего мозга. Наука 338, 1202–1205.DOI: 10.1126 / science.1225266
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Фиджеланд, А. К., и Шанахан, М. П. (2010). «Ускоренное моделирование нейронных сетей с использованием графических процессоров», в The International Joint Conference on Neural Networks (Barcelona: IEEE), 1–8.
Фурбер, С., Лестер, Д., Плана, Л., Гарсайд, Дж., Пейнкрас, Э., Темпл, С., и др. (2013). Обзор архитектуры спинакерной системы. IEEE Trans. Comput. 62, 2454–2467. DOI: 10.1109 / TC.2012.142
CrossRef Полный текст | Google Scholar
Фурбер, С. Б., Галлуппи, Ф., Темпл, С., и Плана, Л. А. (2014). Проект SpiNNaker. Proc. IEEE 104, 652–665. DOI: 10.1109 / JPROC.2014.2304638
CrossRef Полный текст | Google Scholar
Галлуппи Ф., Раст А., Дэвис С. и Фурбер С. (2010). «Универсальная система трансляции моделей универсального нейронного чипа», в Neural Information Processing.Теория и алгоритмы , ред. К. В. Вонг, Б. С. У. Мендис и А. Бузердум (Берлин; Гейдельберг: Springer), 58–65.
Google Scholar
Герстнер В. и Кистлер В. (2002). «Интегрируй и запускай модель», в Spiking Neurons Models: Single Neurons, Populations, Plasticity (Cambridge: Cambridge University Press), 93–102.
PubMed Аннотация | Google Scholar
Гевалтиг, М. О., Дисманн, М. (2007). NEST (инструмент нейронного моделирования). В Scholarpedia 2, 1430.DOI: 10.4249 / scholarpedia.1430
CrossRef Полный текст | Google Scholar
Граас, Э. Л., Браун, Э. А., и Ли, Р. Х. (2004). Подход на основе ПЛИС к высокоскоростному моделированию моделей нейронов на основе проводимости. Нейроинформатика 2, 417–435. DOI: 10.1385 / NI: 2: 4: 417
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Гаврилич, М. Дж., Лейн, Э. С., Гильозет-Бонгаартс, А. Л., Шен, Э. Х., Нг, Л., Миллер, Дж. А. и др. (2012). Анатомически исчерпывающий атлас транскриптома мозга взрослого человека. Nature 489, 391–399. DOI: 10.1038 / природа11405
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Хоанг, Р. В., Танна, Д., Джайет Брей, Л. К., Даскалу, С. М., и Харрис, Ф. К. (2013). Новая среда моделирования CPU / GPU для крупномасштабного биологически реалистичного нейронного моделирования. Фронт. Нейроинформ. 7:19. DOI: 10.3389 / fninf.2013.00019
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Ходжкин А.Л., Хаксли А.Ф. (1952). Количественное описание мембранного тока и его применение к проводимости и возбуждению в нерве. J. Physiol. 117, 500. DOI: 10.1113 / jphysiol.1952.sp004764
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Хамбл, Дж., Денхэм, С., и Веннекерс, Т. (2012). Распознаватели пространственно-временных паттернов, использующие спайковые нейроны и пластичность, зависящую от спайков. Фронт. Comput. Neurosci. 6:84. DOI: 10.3389 / fncom.2012.00084
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Хан, М.М., Лестер, Д. Р., Плана, Л. А., Раст, А., Джин, X., Пейнкрас, Э. и др. (2008). «SpiNNaker: отображение нейронных сетей на массивно-параллельный мультипроцессор на микросхемах», в Международная объединенная конференция IEEE по нейронным сетям (Всемирный конгресс IEEE по вычислительному интеллекту) (Гонконг), 2849–2856.
Кохара К., Пигнателли М., Ривест А. Дж., Юнг Х. Ю., Китамура Т., Сух Дж. И др. (2013). Генетические и оптогенетические инструменты, специфичные для типов клеток, выявляют цепи CA2 гиппокампа. Нат. Neurosci. 17, 269–279. DOI: 10.1038 / nn.3614
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Лавин К., Падилья М., Лампрехт Дж., Лундриган П., Нельсон Б. и Хатчингс Б. (2011). «HMFlow: ускорение компиляции FPGA с помощью жестких макросов для быстрого прототипирования», в 19-й ежегодный международный симпозиум IEEE по программируемым пользовательским вычислительным машинам, 2011 г., (Солт-Лейк-Сити, Юта: IEEE), 117–124.
Ливет, Дж., Вайсман, Т.A., Kang, H., Draft, R. W., Lu, J., Bennis, R.A., et al. (2007). Трансгенные стратегии комбинаторной экспрессии флуоресцентных белков в нервной системе. Nature 450, 56–62. DOI: 10.1038 / nature06293
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Madisen, L., Zwingman, T.A., Sunkin, S.M., Oh, S.W., Zariwala, H.A., Gu, H., et al. (2010). Надежная и высокопроизводительная система Cre отчетов и характеристик для всего мозга мыши. Нат.Neurosci. 13, 133–140. DOI: 10.1038 / nn.2467
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Магуайр, Л. П., МакГиннити, Т. М., Глакин, Б., Гани, А., Белатрече, А., и Харкин, Дж. (2007). Проблемы крупномасштабной реализации нейронных сетей с пиками на ПЛИС. Neurocomputing 71, 13–29. DOI: 10.1016 / j.neucom.2006.11.029
CrossRef Полный текст | Google Scholar
Markram, H., Meier, K., Lippert, T., Grillner, S., Frackowiak, R., Dehaene, S., et al. (2011). Представляем проект «Человеческий мозг». Процедуры Comput. Sci. 7, 39–42. DOI: 10.1016 / j.procs.2011.12.015
CrossRef Полный текст | Google Scholar
Меролла П. А., Артур Дж. В., Альварес-Иказа Р., Кэссиди А. С., Савада Дж., Акопян Ф. и др. (2014). Интегральная схема с миллионным импульсным нейроном с масштабируемой коммуникационной сетью и интерфейсом. Наука 345, 668–673. DOI: 10.1126 / science.1254642
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Мур, С.У., Фокс, П. Дж., Марш, С. Дж., Маркеттос, А. Т., и Муджумдар, А. (2012). «Bluehive — программируемая на заказ вычислительная машина для моделирования нейронных сетей в экстремальных масштабах в реальном времени», в 20-й ежегодный международный симпозиум IEEE по программируемым пользовательским вычислительным машинам, (Торонто, Онтарио), 133–140.
Oh, S. W., Harris, J. A., Ng, L., Winslow, B., Cain, N., Mihalas, S., et al. (2014). Мезомасштабный коннектом мозга мыши. Природа 508, 207–214. DOI: 10.1038 / природа13186
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Фока, Э., Вильди, М., Шульц, С. Р., и Бараона, М. (2012). Сенсорный опыт изменяет динамику спонтанного состояния в крупномасштабной бочковой кортикальной модели. J. Comput. Neurosci. 33, 323–339. DOI: 10.1007 / s10827-012-0388-6
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Plana, L.A., Furber, S. B., Temple, S., Khan, M., Shi, Y., Wu, J., et al. (2007).Инфраструктура GALS для многопроцессорной системы с массовым параллелизмом. Design Test Comput. IEEE 24, 454–463. DOI: 10.1109 / MDT.2007.149
CrossRef Полный текст | Google Scholar
Раст А., Джин X., Хан М. и Фурбер С. (2009). «Модель отложенных событий для аппаратно-ориентированных нейронных сетей с пиками», в Advances in Neuro-Information Processing , ред. М. Кеппен, Н. Касабов и Г. Когхилл (Берлин; Гейдельберг: Springer), 1057–1064.
Рейманн, М.В., Анастассиу, К. А., Перин, Р., Хилл, С. Л., Маркрам, Х., и Кох, К. (2013). Биофизически подробная модель потенциалов локального поля неокортекса предсказывает критическую роль активных мембранных токов. Нейрон 79, 375–390. DOI: 10.1016 / j.neuron.2013.05.023
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Райс, К. Л., Бхуйян, М., Таха, Т. М., Вуцинас, К. Н., и Смит, М. К. (2009). «Реализация на ПЛИС нейронных сетей Ижикевича для распознавания символов», в Международная конференция по реконфигурируемым вычислениям и ПЛИС, 2009 г. (Кинтана-Роо: IEEE), 451–456.
Google Scholar
Рихерт, М., Нагесваран, Дж. М., Датт, Н. и Кричмар, Дж. Л. (2011). Эффективная среда моделирования для моделирования крупномасштабной обработки коркового вещества. Фронт. Нейроинформ. 5:19. DOI: 10.3389 / fninf.2011.00019
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Rospars, J. P., and Lánský, P. (1993). Стохастическая модель нейрона без сброса дендритного потенциала: приложение к обонятельной системе. Biol.Киберн. 69, 283–294. DOI: 10.1007 / BF00203125
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Шеммель, Дж., Брудерле, Д., Грубл, А., Хок, М., Мейер, К., и Милльнер, С. (2010). «Нейроморфная аппаратная система в масштабе пластины для крупномасштабного нейронного моделирования», в материалах Proceedings of 2010 IEEE International Symposium on Circuits and Systems (Paris), 1947–1950.
Седкол П., Блоджет Б., Беккер Т., Андерсон Дж. И Лисагт П. (2006).Модульная динамическая реконфигурация в ПЛИС Virtex. Comput. Цифра. Техн. IEE Proc. 153, 157–164. DOI: 10.1049 / IP-CDT: 20050176
CrossRef Полный текст | Google Scholar
Сильвер Р., Боахен К., Грилнер С., Копелл Н. и Олсен К. Л. (2007). Neurotech для нейробиологии: объединение концепций, принципов организации и новых инструментов. J. Neurosci. 27, 11807–11819. DOI: 10.1523 / JNEUROSCI.3575-07.2007
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Смарагдос, Г., Исаза, С., ван Эйк, М. Ф., Сурдис, И., и Стридис, К. (2014). «Биофизически значимое моделирование оливоцеребеллярных нейронов на основе ПЛИС», в Proceedings of the 2014 ACM / SIGDA International Symposium on Field-Programmable Gate Arrays (New York, NY), 89–98.
Томас, Д. Б., и Лук, В. (2009). «Ускоренное моделирование с помощью ПЛИС нейронных сетей с биологически вероятными импульсами», 17-й симпозиум IEEE по программируемым пользовательским вычислительным машинам в полевых условиях (Напа, Калифорния), 45–52.
Google Scholar
Вайдья, С. П., и Джонстон, Д. (2013). Временная синхронность и преобразование мощности гамма-тета в дендритах пирамидных нейронов CA1. Нат. Neurosci. 16, 1812–1820. DOI: 10.1038 / nn.3562
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Ван, Р., Коэн, Г., Штифель, К. М., Гамильтон, Т. Дж., Тэпсон, Дж., И ван Шайк, А. (2013). Реализация полихронной нейронной сети с пиковыми импульсами на ПЛИС с адаптацией задержки. Фронт. Neurosci. 7:14. DOI: 10.3389 / fnins.2013.00014
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Ван, Р. М., Гамильтон, Т. Дж., Тэпсон, Дж. К., и ван Шайк, А. (2015). Нейроморфная реализация правил множественной синаптической пластичности с синхронизацией импульсов для крупномасштабных нейронных сетей. Фронт. Neurosci. 9: 180. DOI: 10.3389 / fnins.2015.00180
PubMed Аннотация | CrossRef Полный текст | Google Scholar
(PDF) Точное и точное моделирование процессора
Точное и точное моделирование процессора
Департамент компьютерных наук
Университет Висконсина
1210 W.Dayton Street
Madison, WI 53706
{cain, baschwar} @ cs.wisc.edu
Abstract
Точное и точное моделирование процессоров и компьютерных систем
— это кропотливая, трудоемкая и
подверженная ошибкам задача. Абстракция и упрощение — это мощные инструменты
для снижения стоимости и сложности моделирования
, но, как известно, они снижают точность. Аналогичным образом,
, ограничивающее и упрощающее рабочие нагрузки, которые используются для моделирования привода
, может упростить задачу архитектора компьютера
, одновременно подвергая точность моделирования риску
.Исторически сложилось так, что точность предпочтительнее, чем точность
, что привело к появлению симуляторов, которые могут анализировать
-минутных вариаций модели машины, при этом неверно прогнозируя —
иногда резко — фактическую производительность моделируемого процессора
. В этой статье мы утверждаем, что необходимы
как точных, так и точных симуляторов, а
доказывают, что противостоит общепринятому мнению для
трех факторов, влияющих на точность и точность моделирования.Во-первых, мы показываем, что эффекты операционной системы
важны не только для коммерческих рабочих нагрузок, но также
для целочисленных тестов SPEC. Затем мы покажем, что sim
, выводящий неверные спекулятивные пути, в значительной степени не важен как для коммерческих рабочих нагрузок, так и для тестов SPEC integer
. Наконец, мы утверждаем, что правильная симуляция поведения ввода-вывода
даже в однопроцессорных системах может повлиять на точность симулятора
.
1.0 Введение и мотивация
На протяжении многих лет моделирование на различных уровнях абстракции
играло ключевую роль в проектировании компьютерных систем.
Существует множество веских причин для внедрения симуляторов
, большинство из которых очевидны. Команды разработчиков нуждаются в симуляторах
на всех этапах цикла проектирования. Первоначально,
во время высокоуровневого проектирования, моделирование используется для сужения пространства проектирования
и установления надежных и осуществимых альтернативных вариантов, которые, вероятно, будут соответствовать целям конкурентоспособных показателей
. Позже, во время определения микроархитектуры, симулятор
помогает находить компромиссы при проектировании, позволяя
проводить количественное сравнение различных альтернатив.Во время реализации проекта
симуляторы используются для компромиссов тестирования
, функциональной проверки и проектирования на поздних этапах цикла.
Наконец, симуляторы предоставляют полезные справочные материалы для проверки производительности, когда становится доступным реальное оборудование.
Вне цикла промышленного проектирования тренажеры
также активно используются в исследовательском сообществе
академической компьютерной архитектуры. В этом контексте симуляторы
в основном используются в качестве средства демонстрации или сравнения
полезности новых архитектурных функций, методов компиляции или методов микроархитектуры, а не для
, помогающих руководить реальным дизайнерским проектом.В результате демо-симуляторы aca
редко используются для функциональной или производственной проверки, а используются строго для подтверждения концепции, исследования космоса проекта
или количественного анализа компромиссов.
Моделирование может происходить на различных уровнях абстракции.
Некоторые возможные подходы, их преимущества и недостатки суммированы в таблице 1. Например, гибкие
и мощные аналитические модели, использующие теорию очередей, могут использоваться для изучения компромиссов на системном уровне. Определите
узких мест и сделайте приблизительные прогнозы производительности
.В качестве альтернативы, уравнения, в которых
вычислительных циклов на инструкцию (CPI) на основе пропусков кэша
скоростей и фиксированных задержек также могут быть использованы для оценки производительности
, хотя этот подход не эффективен для систем
, которые могут маскировать задержка при одновременной активности.
Эти подходы эффективны и широко используются, но
не будет далее рассматриваться в этой статье. Вместо этого мы сосредоточим внимание на последних трех альтернативах:
, управляемом трассировкой, выполнением, или моделированием всей системы
для моделирования процессоров и компьютерных систем.
Моделирование на основе трассировки использует трассировки выполнения, собранные
из реальных систем. Схемы сбора варьируются от программных
только программных схем, которые оборудуют все программные двоичные файлы
и заканчивая проприетарными аппаратными устройствами, которые подключаются к портам отладки процессора
. Первые загрязняют собранную трассировку
, поскольку служебные данные программного обеспечения замедляют выполнение программы по отношению к устройствам ввода-вывода и другим внешним событиям. Последний
может работать на полной скорости, но требует дорогостоящих инвестиций в проприетарное оборудование, знание интерфейсов порта отладки
и, вероятно, не пригоден для будущих процессоров с несколькими
гигагерц.Сбор трассировки также затрудняется
тем фактом, что обычно в трассировку записываются только неспекулятивные или фиксированные инструкции
. Следовательно, эффекты
спекулятивно выполненных инструкций из неправильных ветвей
путей теряются. Кроме того, как только след был обнаружен,
Электротехника и вычислительная техника
Университет Висконсина
1415 Engineering Drive
Madison, WI 53706
{lepak, mikko} @ece.wisc.edu
Гарольд В. Кейн, Кевин М. Лепак, Брэндон А. Шварц и Микко Х. Липасти
Подтверждено! Мы живем в симуляции
С тех пор, как философ Ник Бостром предложил в Philosophical Quarterly , что Вселенная и все, что в ней может быть симуляцией, возникли интенсивные общественные спекуляции и дискуссии о природе реальности. Такие публичные интеллектуалы, как лидер Tesla и плодовитый Твиттер-овод Илон Маск, высказывают мнение о том, что статистическая неизбежность нашего мира не более чем каскадный зеленый код.Недавние статьи основывались на исходной гипотезе для дальнейшего уточнения статистических границ гипотезы, утверждая, что вероятность того, что мы живем в симуляции, может составлять 50–50.
Утверждения были подтверждены повторением светил, не менее уважаемых, чем Нил де Грасс Тайсон, директор планетария Хайдена и любимый популяризатор науки Америки. Тем не менее, были скептики. Физик Фрэнк Вильчек утверждал, что в нашей Вселенной слишком много потраченной впустую сложности, чтобы ее можно было смоделировать.Сложность строительства требует энергии и времени. Зачем сознательному, интеллектуальному разработчику реальности тратить столько ресурсов на то, чтобы сделать наш мир более сложным, чем он должен быть? Это гипотетический вопрос, но он все же может понадобиться. Другие, например, физик и научный коммуникатор Сабина Хоссенфельдер, утверждали, что вопрос в любом случае не является научным. Поскольку гипотеза симуляции не дает фальсифицируемого прогноза, мы не можем проверить или опровергнуть ее, и, следовательно, ее не стоит серьезно исследовать.
Однако все эти дискуссии и исследования гипотезы моделирования, как я полагаю, упускают из виду ключевой элемент научного исследования: простую старую эмпирическую оценку и сбор данных. Чтобы понять, живем ли мы в симуляции, нам нужно начать с рассмотрения того факта, что у нас уже есть компьютеры, на которых выполняются все виды симуляций для «интеллекта» или алгоритмов более низкого уровня. Для упрощения визуализации мы можем представить эти интеллекты как любых не связанных с личностью персонажей в любой видеоигре, в которую мы играем, но, по сути, любой алгоритм, работающий на любой вычислительной машине, подходит для нашего мысленного эксперимента.Нам не нужен интеллект, чтобы быть сознательными, и нам не нужно, чтобы он был даже очень сложным, потому что доказательства, которые мы ищем, «переживаются» всеми компьютерными программами, простыми или сложными, работающими на всех машинах, медленными. или быстро.
Все вычислительное оборудование оставляет артефакт своего существования в мире симуляции, которую оно запускает. Этот артефакт — скорость процессора. Если на мгновение мы представим себя программой, работающей на вычислительной машине, единственным и неизбежным артефактом поддерживающего нас оборудования в нашем мире будет скорость процессора.Все другие законы, с которыми мы столкнемся, будут законами симуляции или программного обеспечения, частью которого мы являемся. Если бы мы были симом или персонажем Grand Theft Auto, это были бы законы игры. Но все, что мы делаем, также будет ограничиваться скоростью процессора независимо от законов игры. Независимо от того, насколько полное моделирование, скорость процессора будет вмешиваться в операции моделирования.
В вычислительных системах, конечно, это вмешательство скорости обработки в мир выполняемого алгоритма происходит даже на самом фундаментальном уровне.Даже на самом фундаментальном уровне простых операций, таких как сложение или вычитание, скорость обработки определяет физическую реальность операции, которая отделена от моделируемой реальности самой операции.
Вот простой пример. 64-битный процессор будет выполнять вычитание, скажем, между 7,862,345 и 6,347,111 за то же время, что и вычитание между двумя и единицей (при условии, что все числа определены как переменные одного и того же типа). В смоделированной реальности семь миллионов — это очень большое число, а один — сравнительно очень небольшое число.В физическом мире процессора разница в масштабе между этими двумя числами не имеет значения. Оба вычитания в нашем примере представляют собой одну операцию и занимают одно и то же время. Здесь мы теперь ясно видим разницу между «смоделированным» или абстрактным миром программной математики и «реальным» или физическим миром микропроцессорных операций.
В абстрактном мире программной математики скорость обработки операций в секунду будет наблюдаться, ощущаться, ощущаться, отмечаться как артефакт лежащих в основе физических вычислительных машин.Этот артефакт появится как дополнительный компонент любой операции, на которую не влияет операция в моделируемой реальности. Значение этого дополнительного компонента операции можно было бы просто определить как время, необходимое для выполнения одной операции с переменными до максимального предела, который является размером контейнера памяти для переменной. Так, в восьмибитном компьютере, например, для упрощения, это будет 256. Значение этого дополнительного компонента будет одинаковым для всех чисел вплоть до максимального предела.Таким образом, дополнительный аппаратный компонент не будет иметь значения для каких-либо операций в моделируемой реальности, за исключением случаев, когда он определяется как максимальный размер контейнера. Наблюдатель в моделировании не имеет кадра для количественной оценки скорости процессора, за исключением тех случаев, когда она представляет собой верхний предел.
Если мы живем в симуляции, то в нашей вселенной тоже должен быть такой артефакт. Теперь мы можем сформулировать некоторые свойства этого артефакта, которые помогут нам в поисках такого артефакта в нашей Вселенной.
- Артефакт является дополнительным компонентом каждой операции, на который не влияет величина переменных, над которыми работают, и не имеет отношения к моделируемой реальности до тех пор, пока не будет соблюден максимальный размер переменной.
- Артефакт представляет себя в моделируемом мире как верхний предел.
- Артефакт не может быть объяснен механистическими законами моделируемой вселенной. Это должно быть принято как предположение или «дано» в рамках действующих законов моделируемой вселенной.
- Эффект артефакта или аномалии абсолютен. Без исключений.
Теперь, когда у нас есть некоторые определяющие особенности артефакта, конечно, становится ясно, как артефакт проявляется в нашей вселенной. Артефакт проявляется как скорость света.
Космос для нашей вселенной — это то же самое, что числа для моделируемой реальности на любом компьютере. Материю, движущуюся в пространстве, можно просто рассматривать как операции, происходящие в переменном пространстве.Если материя движется со скоростью, скажем, 1000 миль в секунду, то пространство на 1000 миль преобразуется функцией или воздействует на каждую секунду. Если бы было какое-то оборудование, выполняющее моделирование под названием «пространство», частью которого является материя, энергия, вы, я, все, тогда один контрольный признак артефакта оборудования в «пространстве» моделируемой реальности был бы максимальным пределом для размер контейнера для пространства, на котором может быть выполнена одна операция. Такой предел появился бы в нашей Вселенной как максимальная скорость.
Эта максимальная скорость равна скорости света. Мы не знаем, на каком оборудовании выполняется симуляция нашей Вселенной или какие у него свойства, но мы можем сказать одно: размер контейнера памяти для переменного пространства будет около 300000 километров, если процессор будет выполнять одну операцию в секунду .
Это помогает нам сделать интересное наблюдение о природе космоса в нашей Вселенной. Если мы находимся в симуляции, как кажется, то пространство — это абстрактное свойство, написанное в коде.Это не реально. Это аналог числа семь миллионов и один в нашем примере, просто разные абстрактные представления в блоке памяти одного и того же размера. Вверх, вниз, вперед, назад, 10 миль, миллион миль — это просто символы. Скорость чего-либо, движущегося в пространстве (и, следовательно, изменяющего пространство или выполняющего операцию в пространстве), представляет собой степень причинного воздействия любой операции на переменную «пространство». Это причинное воздействие не может распространяться за пределы примерно 300 000 км, если компьютер вселенной выполняет одну операцию в секунду.
Теперь мы можем видеть, что скорость света соответствует всем критериям аппаратного артефакта, выявленным при наблюдении за сборками наших собственных компьютеров. Она остается неизменной независимо от скорости наблюдателя (моделируемой), она наблюдается как максимальный предел, необъяснима физикой Вселенной и абсолютна. Скорость света — это аппаратный артефакт, показывающий, что мы живем в смоделированной вселенной.
Но это не единственный признак того, что мы живем в симуляции. Возможно, наиболее подходящим признаком было то, что мы прятались прямо у нас на глазах.Вернее, позади них. Чтобы понять, что это за важный признак, нам нужно вернуться к нашему эмпирическому исследованию известных нам симуляций. Представьте себе персонажа в ролевой игре (РПГ), скажем, Сима или персонажа из Grand Theft Auto. Алгоритм, представляющий персонажа, и алгоритм, представляющий игровую среду, в которой действует персонаж, взаимосвязаны на многих уровнях. Но даже если мы предположим, что персонаж и окружение разделены, персонажу не нужна визуальная проекция его точки зрения, чтобы взаимодействовать с окружающей средой.
Алгоритмы учитывают некоторые переменные окружения и некоторые переменные состояния персонажа, чтобы проецировать и определять поведение как окружающей среды, так и персонажа. Визуальная проекция или то, что мы видим на экране, идет нам на пользу. Это субъективная проекция некоторых переменных в программе, позволяющая нам испытать ощущение присутствия в игре. Аудиовизуальная проекция игры — это интегрированный субъективный интерфейс для нашей пользы, по сути, кто-то контролирует симуляцию.Интегрированный субъективный интерфейс не имеет других причин для существования, кроме как служить нам. Аналогичный мысленный эксперимент можно провести с фильмами. В фильмах часто рассматривается точка зрения персонажей и пытаются показать нам вещи с их точки зрения. Независимо от того, делает ли это конкретная сцена фильма это или нет, то, что проецируется на экран и динамики — интегрированный опыт фильма — не имеет смысла для персонажей фильма. Это полностью в наших интересах.
Практически с самого начала философии мы задаемся вопросом: зачем нам сознание? Какой цели это служит? Что ж, цель легко экстраполировать, если мы признаем гипотезу моделирования.Сознание — это интегрированный (объединяющий пять чувств) субъективный интерфейс между собой и остальной вселенной. Единственное разумное объяснение его существования — это то, что он существует для «переживания». В этом его основной смысл существования. Части этого могут или не могут обеспечить какое-либо эволюционное преимущество или другую полезность. Но в целом это существует как переживание и, следовательно, должно иметь основную функцию — быть переживанием. Сам по себе опыт в целом требует слишком больших затрат энергии и ограничивает информацию, чтобы развиваться как эволюционное преимущество.Простейшее объяснение существования опыта или квалиа состоит в том, что оно существует для того, чтобы быть опытом.
Нет ничего в философии или науке, никаких постулатов, теорий или законов, которые могли бы предсказать возникновение этого опыта, который мы называем сознанием. Законы природы не требуют его существования и, конечно же, не дают нам никаких эволюционных преимуществ. Объяснений его существованию может быть только два. Во-первых, действуют эволюционные силы, о которых мы не знаем или еще не теоретизировали, которые выбирают для возникновения переживания, называемого сознанием.Во-вторых, опыт — это функция, которую мы выполняем, продукт, который мы создаем, опыт, который мы создаем как люди. Для кого мы создаем этот продукт? Как они получают результат алгоритмов генерации квалиа, которыми мы являемся? Мы не знаем. Но одно можно сказать наверняка: мы его создаем. Мы знаем, что он существует. Это единственное, в чем мы можем быть уверены. И что у нас нет доминирующей теории, объясняющей, зачем она нам нужна.
Итак, здесь мы генерируем продукт, называемый сознанием, который, по-видимому, нам не нужен, это опыт и, следовательно, должен служить опытом.Единственный логичный следующий шаг — предположить, что этот продукт служит кому-то другому.
Итак, одна критика, которая может быть высказана в отношении этого образа мышления, заключается в том, что в отличие от персонажей RPG, скажем, в. Grand Theft Auto, мы сами испытываем квалиа. Если это продукт для кого-то еще, то почему мы его испытываем? Что ж, дело в том, что персонажи Grand Theft Auto тоже испытывают некоторую часть квалиа своего существования. Опыт персонажей сильно отличается от опыта игрока в игре, но между пустым персонажем и игроком есть серая область, где части игрока и части персонажа объединяются в некоторый тип сознания.
Игроки испытывают некоторые разочарования и радости, предназначенные для этого персонажа. Персонаж испытывает на себе последствия поведения игрока. Это очень элементарная связь между игроком и персонажем, но уже с устройствами виртуальной реальности мы видим, что границы стираются. Когда мы едем на американских горках в качестве персонажа, скажем, устройства Oculus VR, мы чувствуем гравитацию.
Откуда эта гравитация? Он существует где-то в пространстве между персонажем, который едет на американских горках, и нашим разумом, занимающим «разум» персонажа.Конечно, можно представить, что в будущем это промежуточное пространство будет шире. Конечно, возможно, что, когда мы переживаем мир и генерируем квалиа, мы сами переживаем крошечную крошечную часть квалиа, в то время как, возможно, более насыщенная информацией версия квалиа проецируется на какой-то другой разум, для блага которого опыт сознания впервые возникла.
Итак, вот оно. Самое простое объяснение существования сознания состоит в том, что это опыт, создаваемый нашими телами, но не для нас.Мы машины, производящие квалиа. Подобно персонажам в Grand Theft Auto, мы существуем для создания интегрированных аудиовизуальных материалов.
Ваш комментарий будет первым